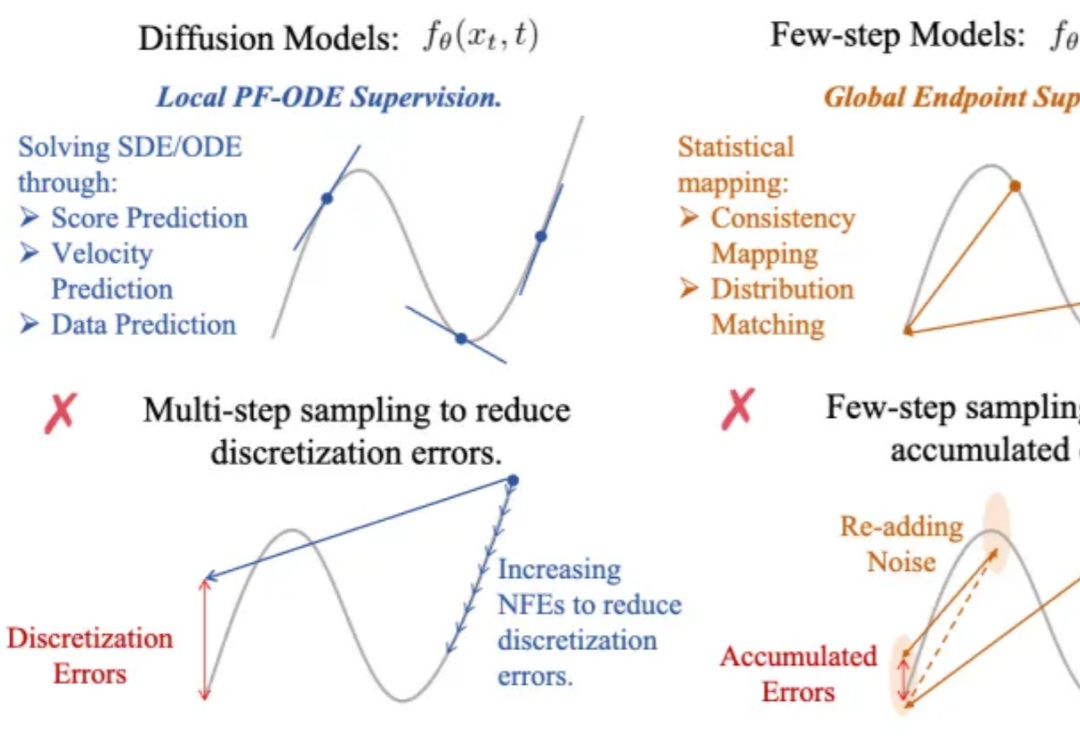
兼得快与好!训练新范式TiM,原生支持FSDP+Flash Attention
兼得快与好!训练新范式TiM,原生支持FSDP+Flash Attention生成式AI的快与好,终于能兼得了?
来自主题: AI技术研报
9365 点击 2025-09-16 10:43
 搜索
搜索
生成式AI的快与好,终于能兼得了?

自动化修复真实世界的软件缺陷问题是自动化程序修复研究社区的长期目标。然而,如何自动化解决视觉软件缺陷仍然是一个尚未充分探索的领域。最近,随着 SWE-bench 团队发布最新的多模态 Issue 修复

金色外观擎天柱首次曝出!一双与人类无异的双手震惊全网,且设计与现有第二代有所不同。网友纷纷猜测,Optimus第三代要来了。
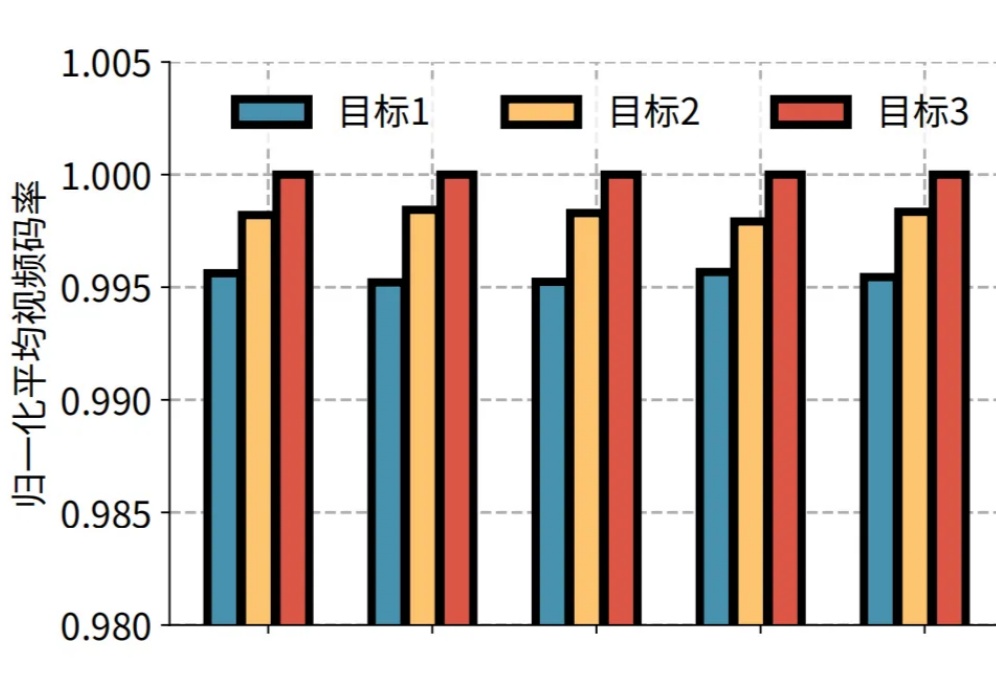
近日,快手与清华大学孙立峰团队联合发表论文《Towards User-level QoE: Large-scale Practice in Personalized Optimization of Adaptive Video Streaming》,被计算机网络领域的国际顶尖学术会议 ACM SIGCOMM 2025 录用。
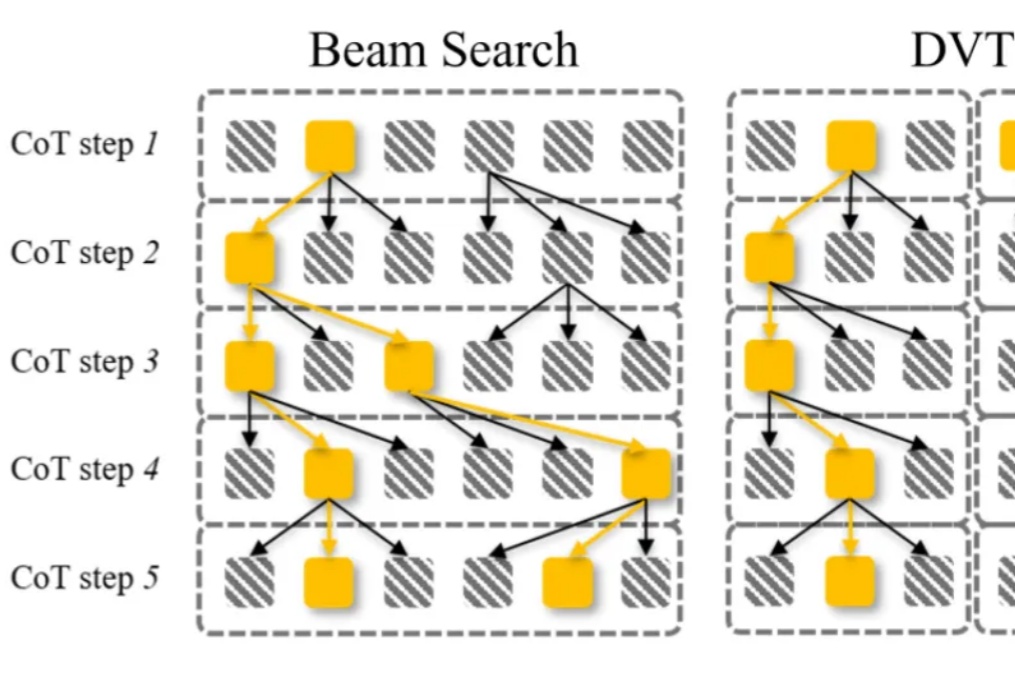
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。

OpenAI凌晨发布最新生产级别语音模型和API。Realtime API实现语音直接处理,支持图像输入、远程MCP服务器与SIP打电话,极大简化语音智能体构建;而新一代语音到语音模型gpt-realtime,在音质、理解力、指令遵循和函数调用上全面提升,语音几乎媲美真人,还能多语种切换与细腻表达。
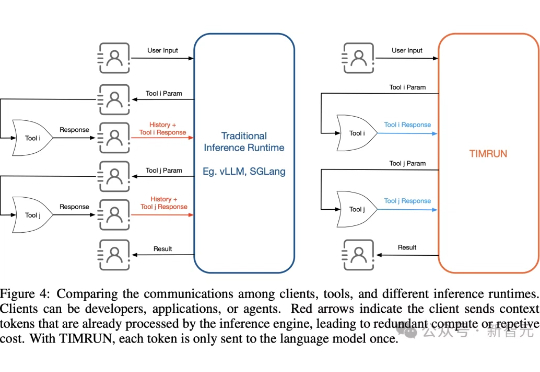
大模型再强,也躲不过上下文限制的「蕉绿」!MIT等团队推出的一套组合拳——TIM和TIMRUN,轻松突破token天花板,让8b小模型也能实现大杀四方。

为什么在这个科技高度发达的时代,我们在预约医生、租房看房、维修报修这些最基本的生活场景中,仍然要忍受漫长的等待和糟糕的体验?为什么一个简单的医疗预约需要等待数小时才能接通电话,一次房屋维修申请要等几天甚至几周才有回复?这些看似琐碎的日常痛点,实际上揭示了两个关键行业的深层问题:它们仍然停留在手工操作的石器时代。
成年后结交朋友可能很困难,尤其是搬到新城市后。幸运的是,现代科技提供了解决方案,越来越多人开始使用Bumble For Friends、Flox 和 Timeleft 等应用快速建立新友谊。
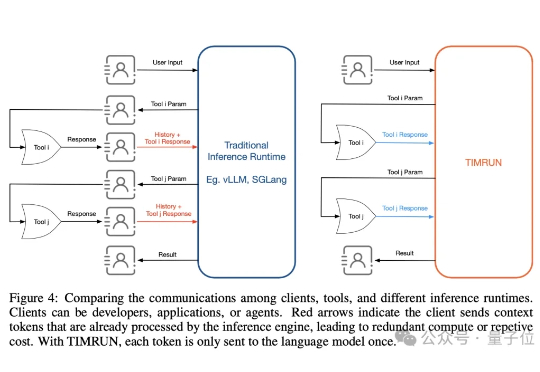
大模型的记忆墙,被MIT撬开了一道口子。 MIT等机构最新提出了一种新架构,让推理大模型的思考长度突破物理限制,理论上可以无限延伸。 这个新架构名叫Thread Inference Model,简称TIM。