对话百度文库:不做大模型能直接做的事,能力积累换来竞争壁垒|AI产品Time
对话百度文库:不做大模型能直接做的事,能力积累换来竞争壁垒|AI产品Time随着AI时代的到来,上一代取得巨大成功的互联网产品都在紧密地结合大模型的能力,为用户提供焕然一新的服务和产品体验。这其中,部分产品走在了变革前沿,不仅利用大模型完成了产品重塑,还借助AI开启了产品的第二增长曲线。
来自主题: AI资讯
8136 点击 2025-08-13 16:53
 搜索
搜索
随着AI时代的到来,上一代取得巨大成功的互联网产品都在紧密地结合大模型的能力,为用户提供焕然一新的服务和产品体验。这其中,部分产品走在了变革前沿,不仅利用大模型完成了产品重塑,还借助AI开启了产品的第二增长曲线。
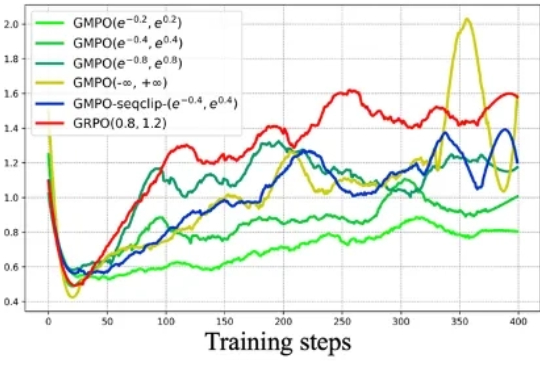
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
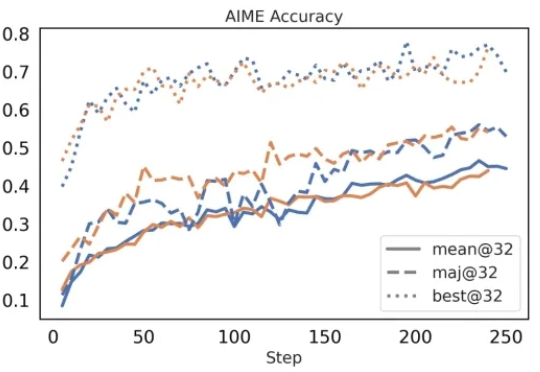
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
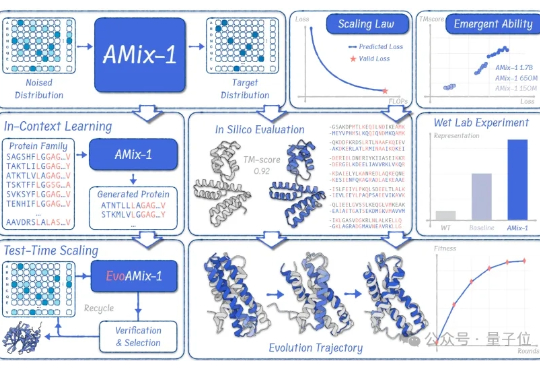
蛋白质模型的GPT时刻来了! 清华大学智能产业研究院(AIR)周浩副教授课题组联合上海人工智能实验室发布了AMix-1: 首次以Scaling Law、Emergent Ability、In-Context Learning和Test-time Scaling的系统化方法论来构建蛋白质基座模型。
近日,麻省理工学院也推出了一个AI学习平台。这个名叫MIT Learn的平台提供超过12700个学习资源,其中大部分是免费的。这个名叫MIT Learn的平台提供超过12700个学习资源,其中大部分是免费的。
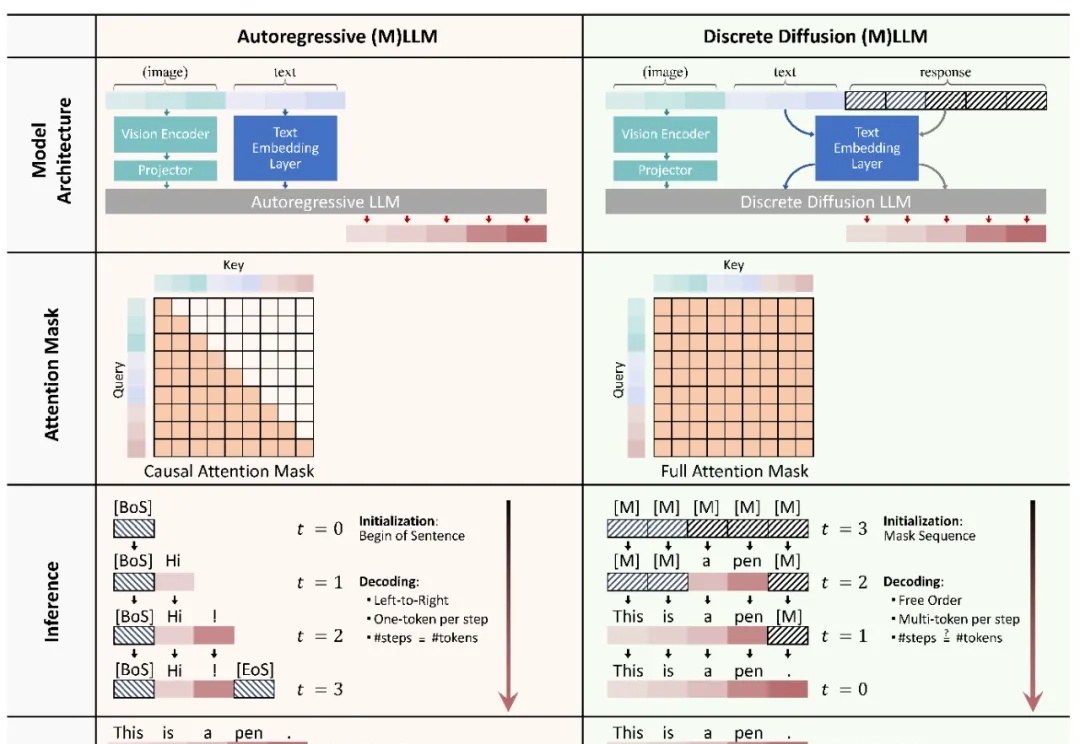
本文主要介绍 xML 团队的论文:Discrete Diffusion in Large Language and Multimodal Models: A Survey。
Zeju Qiu和Tim Z. Xiao是德国马普所博士生,Simon Buchholz和Maximilian Dax担任德国马普所博士后研究员

让大模型在学习推理的同时学会感知。伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了全新的专注于多模态推理的强化学习算法PAPO(Perception-Aware Policy Optimization)。
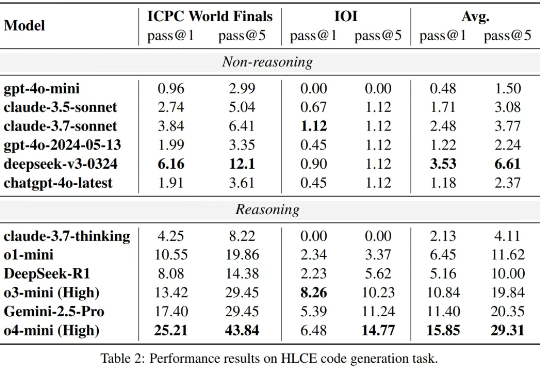
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。