
X上63万人围观的Traning-Free GRPO:把GRPO搬进上下文空间学习
X上63万人围观的Traning-Free GRPO:把GRPO搬进上下文空间学习年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
来自主题: AI技术研报
7823 点击 2025-10-23 11:41
 搜索
搜索
年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
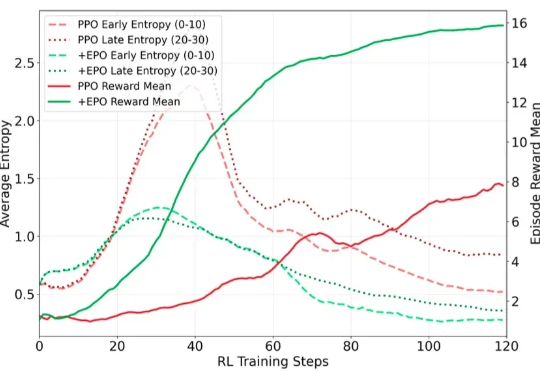
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
一张图,一个3D世界!今天,李飞飞团队重磅放出实时生成世界模型「RTFM」,通过端到端学习大规模视频数据,直接从输入2D图像生成同一场景下新视角的图像。值得一提的是,它仅需单块H100 GPU便能实时渲染出持久且3D一致的世界。

李飞飞的世界模型创业,最新成果来了!刚刚,教母亲自宣布对外推出全新模型RTFM(A Real-Time Frame Model),不仅具备实时运行、持久性和3D一致性,更关键的是——单张H100 GPU就能跑。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。

9月25日,在播客BG2最新一期节目中,BG2主播、Altimeter Capital创始人Brad Gerstner,Altimeter Capital合伙人Clark Tang与英伟达CEO黄仁勋展开了一次对话。黄仁勋在对话中回应了当下市场的关心的问题。
“看得出 Anthropic 是真急了,都开始澄清了。”有网友在看到发文解释 8 月至 9 月初陆续出现 bug 的推文后表示。“产品质量这么差。我之前不明白为什么,现在明白了。”开发者 Tim McGuire 在帖子下表示。
马斯克在忙着裁人,小扎这边继续忙着挖人。 这不?Optimus AI团队负责人Ashish Kumar决定离开特斯拉,加入Meta担任研究科学家。与此同时,小扎砸钱挖人的形象已经深入人心,使得网友不禁锐评,有10亿美元吗?

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。