
Agent 终于有了自己的社交网络——FloatlM 发布
Agent 终于有了自己的社交网络——FloatlM 发布人类的工作、娱乐、学习、交流,依托电脑、手机、游戏机等设备以及网络来实现。此前,FloatBoat 团队已经发布了 Floatboat 这款产品,将整台电脑打造为 Agent 的运行环境。而今天,团队正式发布了 FloatIM —— 一个专为 Agent 构建的网络。
来自主题: AI资讯
8410 点击 2026-04-23 11:30
 搜索
搜索
人类的工作、娱乐、学习、交流,依托电脑、手机、游戏机等设备以及网络来实现。此前,FloatBoat 团队已经发布了 Floatboat 这款产品,将整台电脑打造为 Agent 的运行环境。而今天,团队正式发布了 FloatIM —— 一个专为 Agent 构建的网络。
在AI应用市场上,AI命理是少有的在全球范围内都已验证商业化闭环的赛道。测测坐拥近6000万用户、数亿元营收,韩国Hellobot半年收入1.5亿元,常年稳居本土社交榜前列。印度AstroSage以8000万下载、150万日活实现连续18个月收入增长,毛利率近90%,成为零融资的AI应用成功典范。在欧美市场,Co-Star以零营销投放获得超2000万下载,Moonly活跃用户超1000万。

腾讯云“防爆箱”护航百万“龙虾”上岗,已助力MiniMax强化学习训练。

近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。
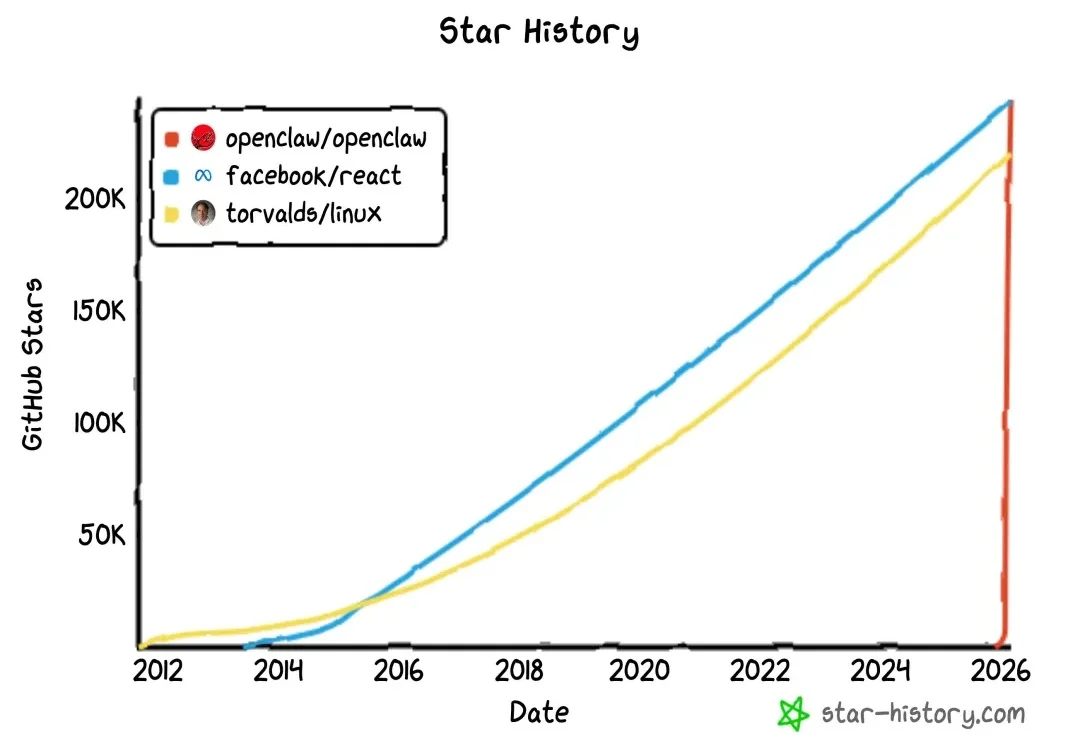
我确实对运行 OpenClaw 持相当怀疑的态度。…… 整个生态给人的感觉就像是一个彻底的狂野西部,在安全性上简直是一场噩梦。 —— Andrej Karpathy

上周发了给Agent用的superpowers插件那篇文章。 没想到反馈还不错,Skills这块的信息差,比我想的还要大一些= = 然后评论区里就有人问了,还是一个叫tim的朋友,问还有什么必装的Sk
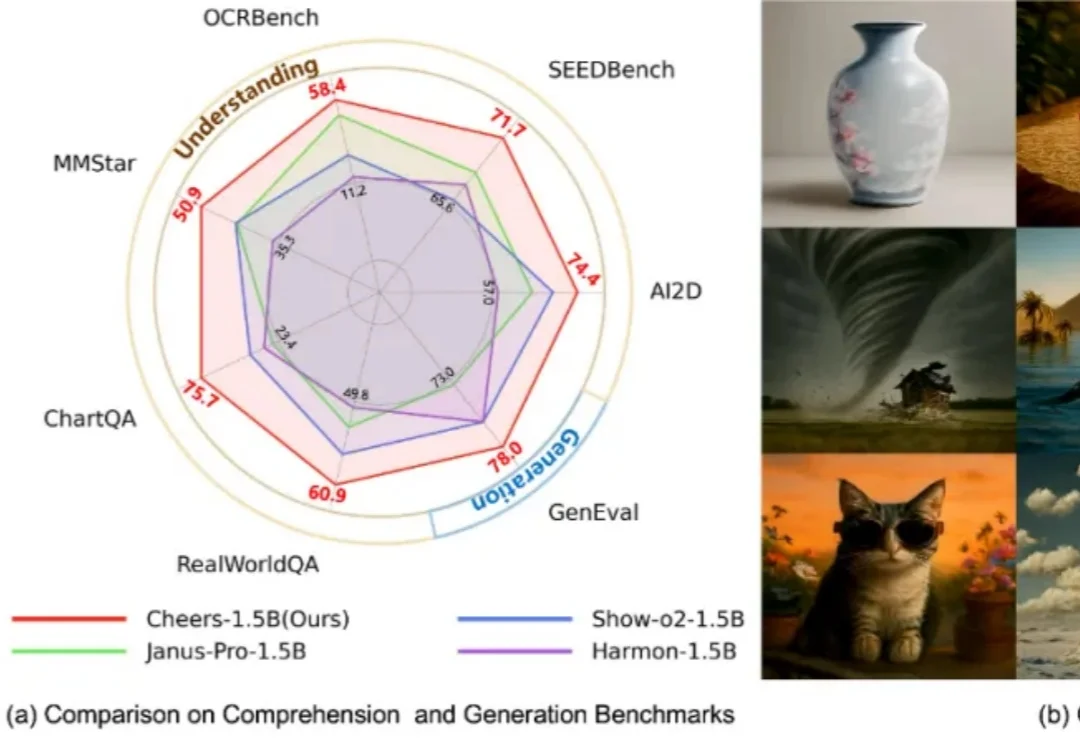
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大
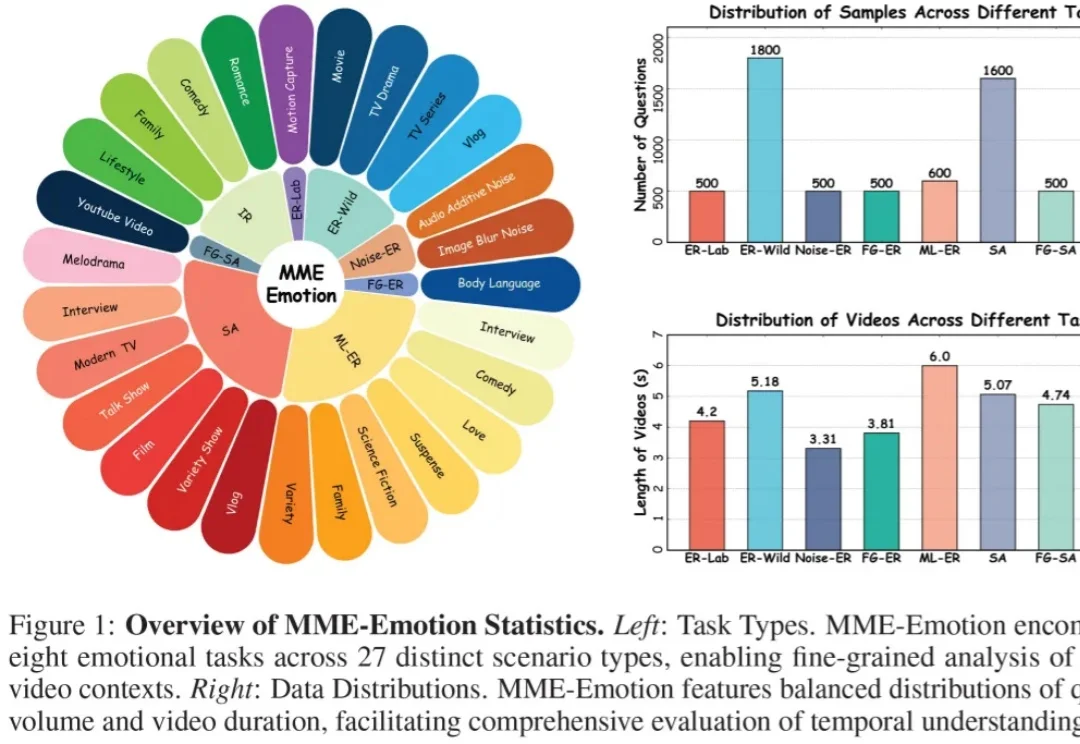
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?
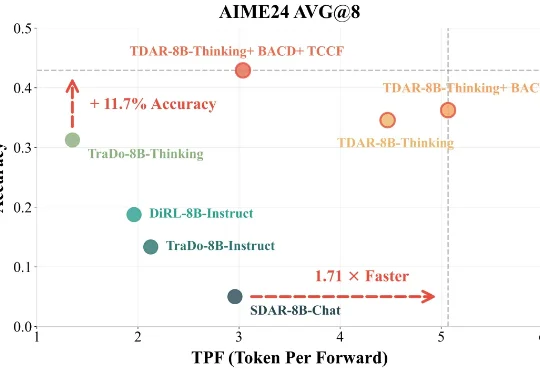
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码