
地瓜机器人携手虚时科技,补上具身智能的仿真数据“黑洞”|甲子光年
地瓜机器人携手虚时科技,补上具身智能的仿真数据“黑洞”|甲子光年重构仿真数据的生产方式。
来自主题: AI资讯
6119 点击 2026-05-12 14:56
 搜索
搜索
重构仿真数据的生产方式。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。
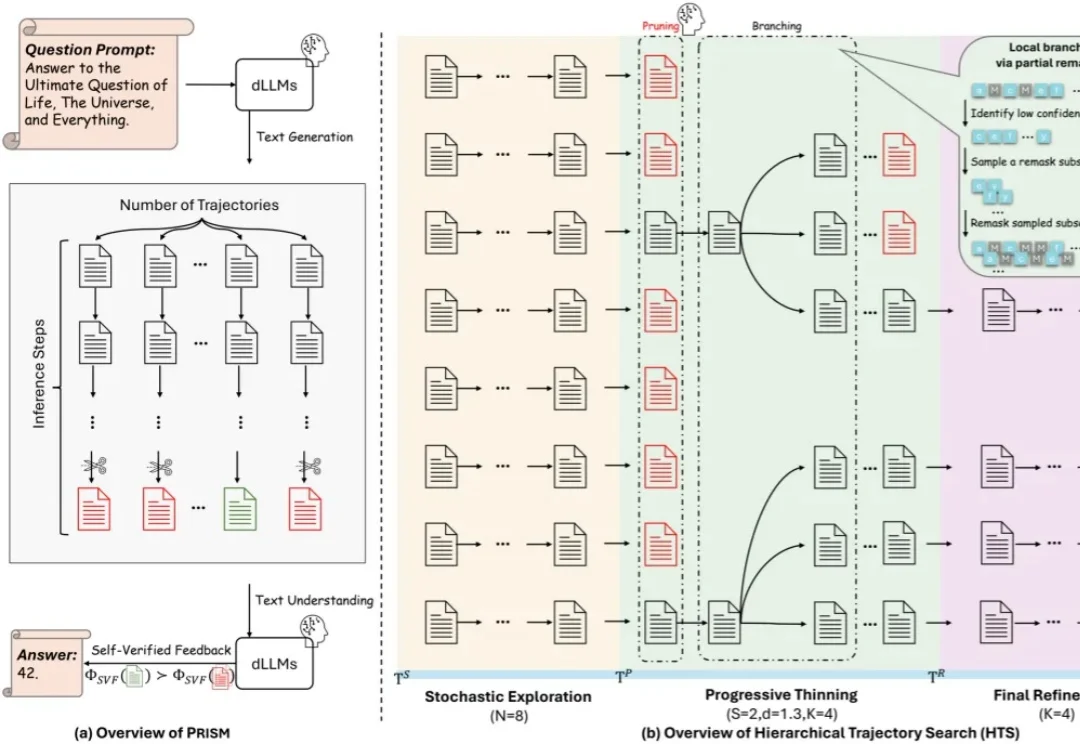
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。

不知道大家平时有没有这种经历。

Realtime API 是 OpenAI 的实时语音交互接口,在 24 年的 DevDay 首次亮相,当时还是 beta,调用贵到离谱,音频输出 200 刀/百万 token:OpenAI 凌晨发布:Realtime 实时多模态 API,及其他

Anthropic 的工程师们写了篇技术博客,标题是:构建 Claude Code 的经验教训:Prompt Caching 就是一切。Anthropic 内部把 Prompt Cache 的命中率当作基础设施级别的指标来监控,地位跟服务器 uptime 差不多。一旦命中率下降,就会触发 oncall 告警,工程师得像处理线上事故一样去排查。

ElatoAI 是一个开源免费的实时AI语音交互系统,采用Arduino 编程,运行在乐鑫 ESP32 主控制器上,通过安全WebSocket连接至部署在Deno边缘函数构建的服务端,通过OpenAI Realtime API等技术实现低成本、长时长、跨设备的自然对话体验,支持多种AI模型,

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。

机器之心编辑部 ICLR 2026 获奖论文已经公布。 今年共有 2 篇论文获得「杰出论文奖」(Outstanding Paper),另有 1 篇论文获得「荣誉提名」(Honorable Mention);此外,还有 2 篇 ICLR 2016 论文获得「时间检验奖」(Test of Time Award)。
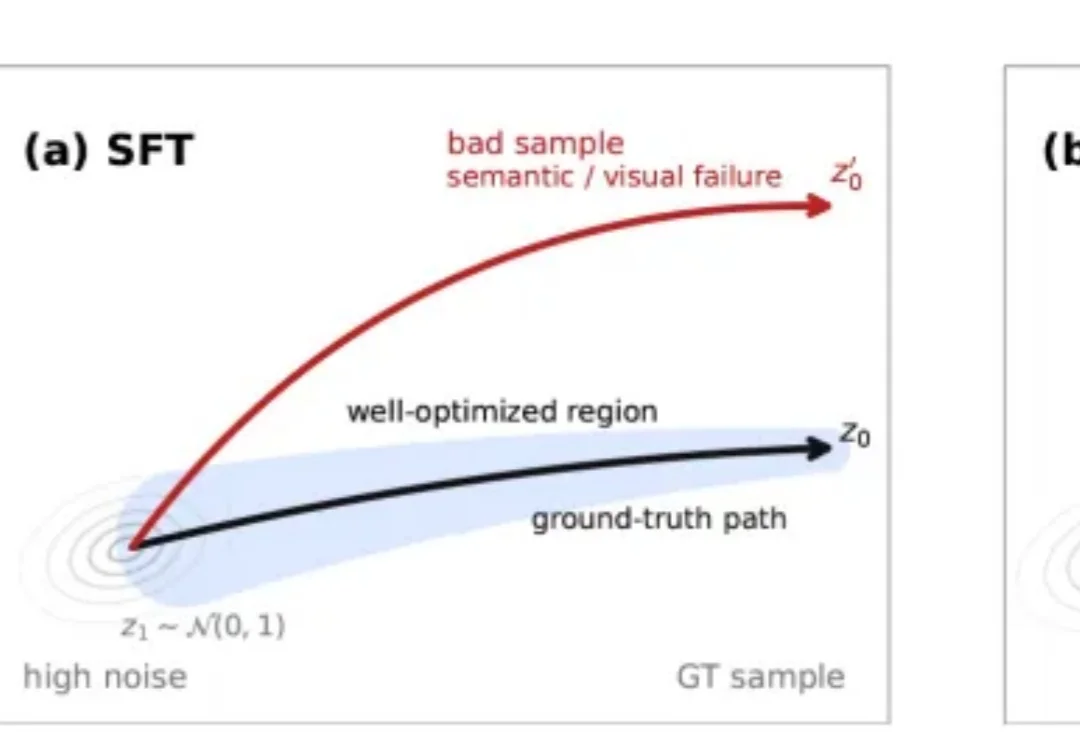
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。