
让龙虾看懂屏幕!谷歌多模态新成果,文本图像视频音频进同一空间
让龙虾看懂屏幕!谷歌多模态新成果,文本图像视频音频进同一空间刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——Gemini Embedding 2。这次模型最大的变化在于:把文本、图像、视频、音频和文档,全部映射进同一个统一的嵌入空间。
来自主题: AI资讯
7163 点击 2026-03-11 16:59
 搜索
搜索
刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——Gemini Embedding 2。这次模型最大的变化在于:把文本、图像、视频、音频和文档,全部映射进同一个统一的嵌入空间。
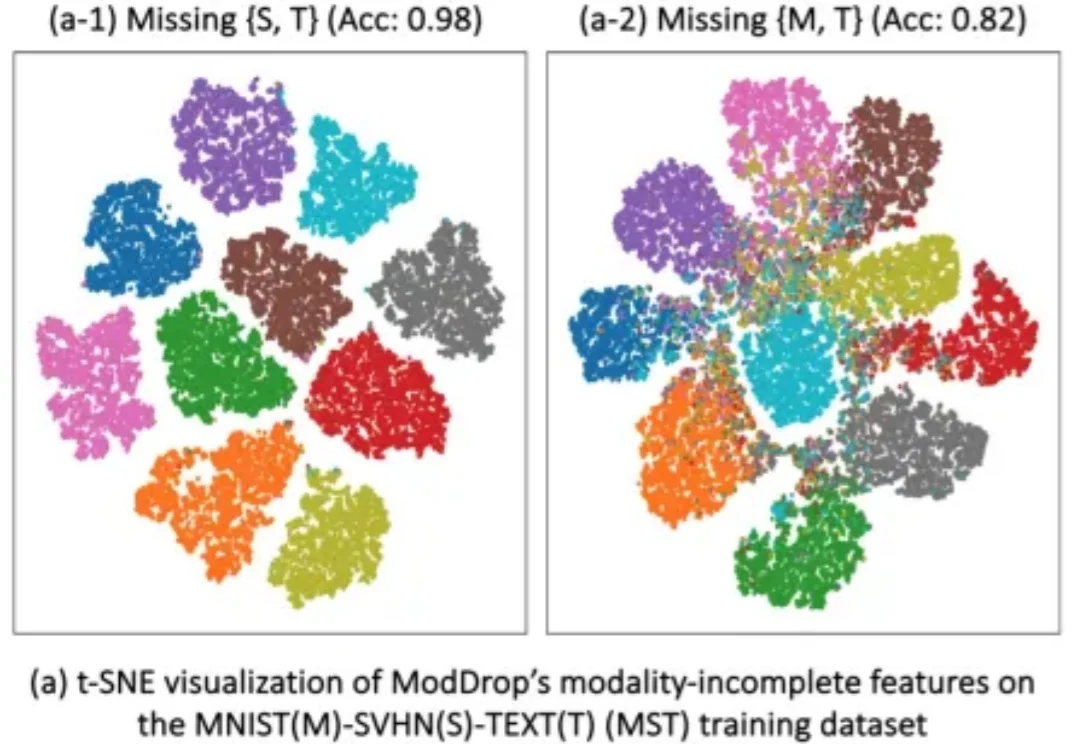
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
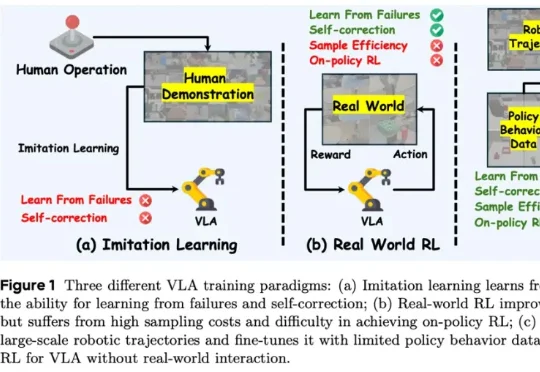
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。
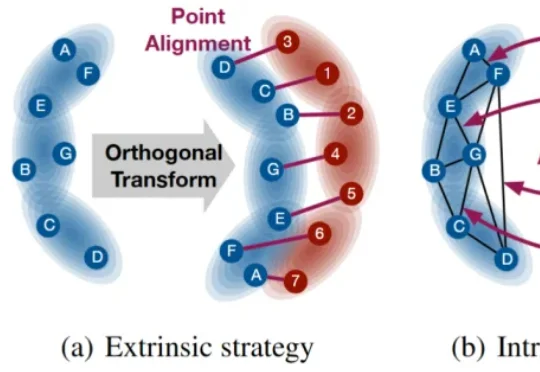
本文提出一种具有 SE(p) 不变传输性质的度量 SEINT:通过构造无需训练的 SE(p) 不变表示,将高维结构信息压缩为可用于 Optimal Transport (OT) 对齐的一维表征,从而在保持不变性与严格度量性质的同时显著提升效率。
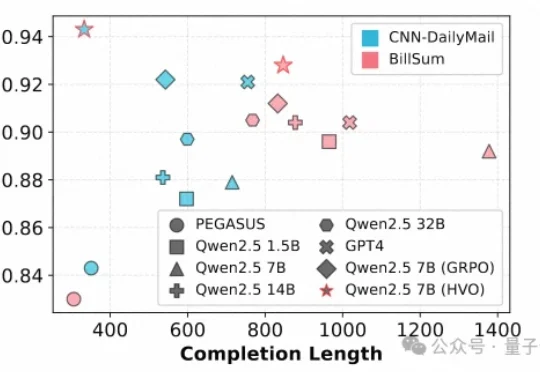
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。
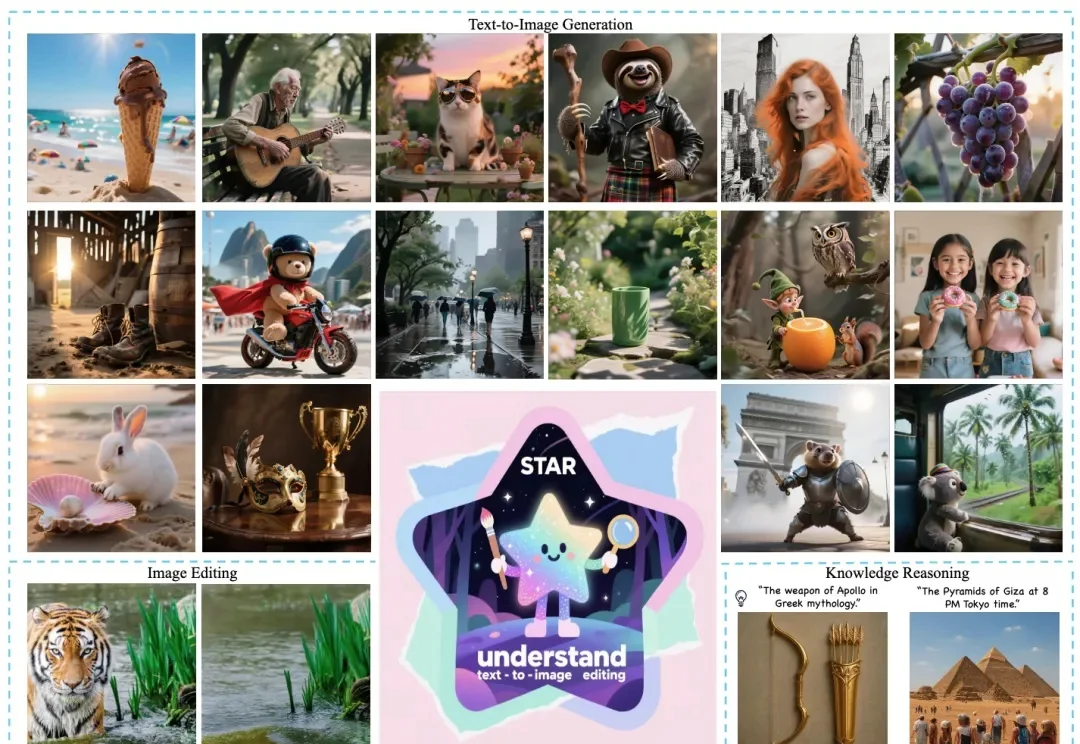
近日,美团推出全新多模态统一大模型方案 STAR(STacked AutoRegressive Scheme for Unified Multimodal Learning),凭借创新的 "堆叠自回归架构 + 任务递进训练" 双核心设计,实现了 "理解能力不打折、生成能力达顶尖" 的双重突破。

在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
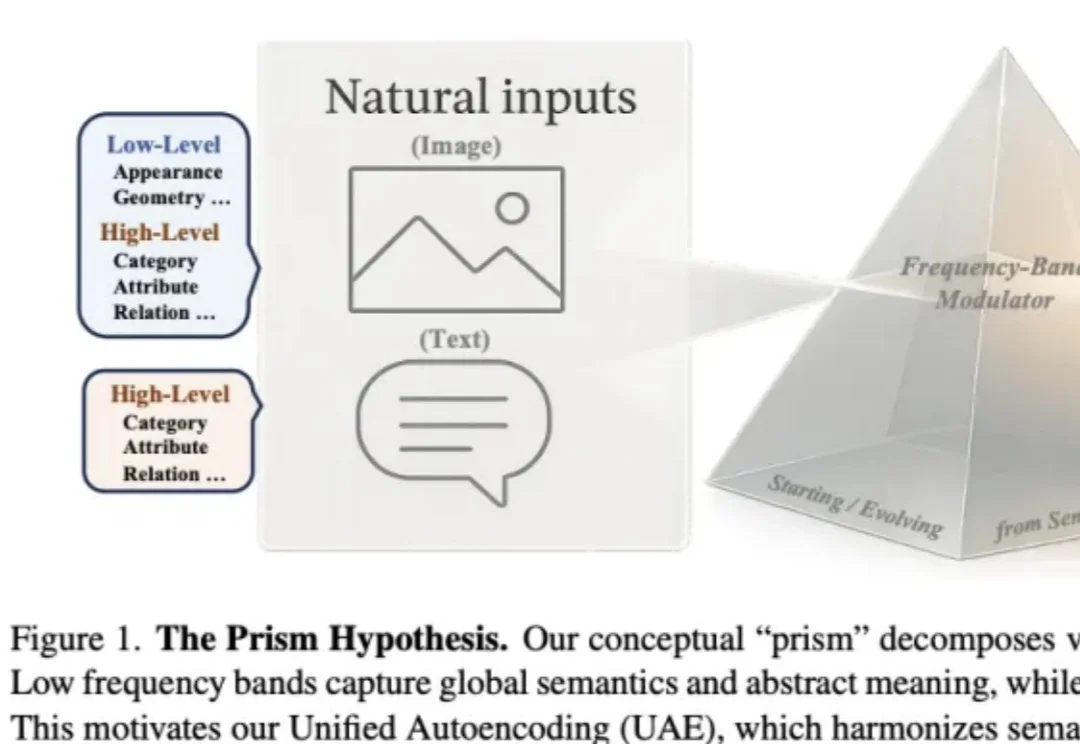
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。