
RLHF与RLVR全都要,陈丹琦团队最新力作将推理能力拓展到通用智能
RLHF与RLVR全都要,陈丹琦团队最新力作将推理能力拓展到通用智能一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。
来自主题: AI技术研报
8342 点击 2025-09-28 16:46
 搜索
搜索
一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。
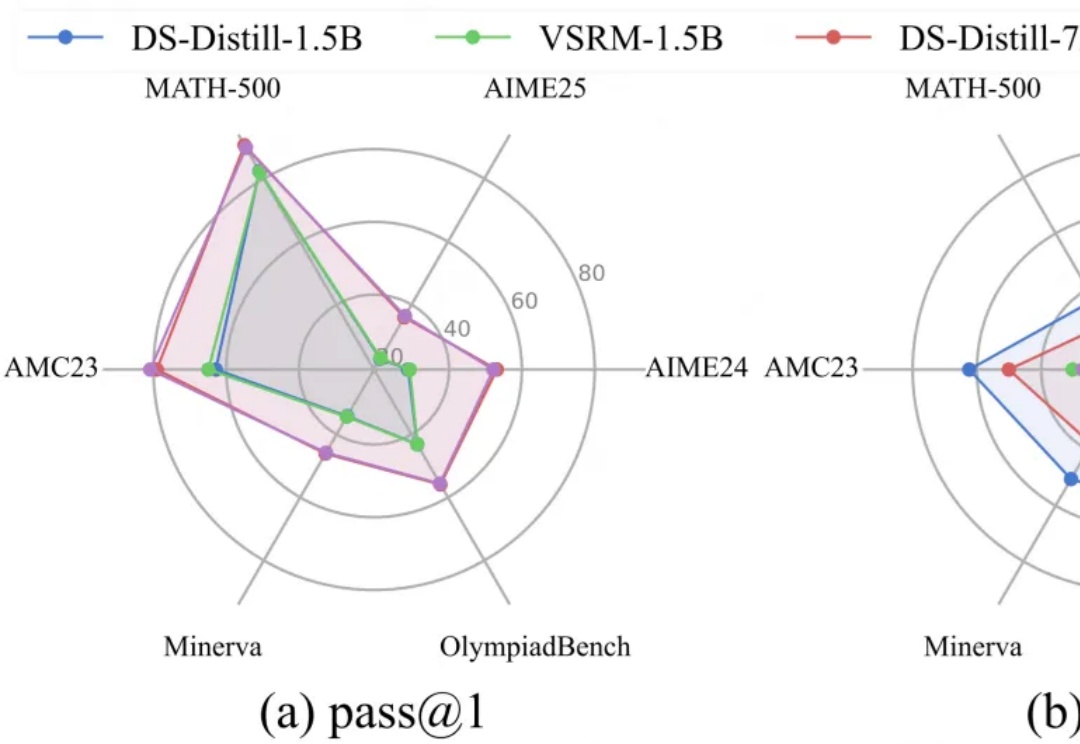
LRM通过简单却有效的RLVR范式,培养了强大的CoT推理能力,但伴随而来的冗长的输出内容,不仅显著增加推理开销,还会影响服务的吞吐量,这种消磨用户耐心的现象被称为“过度思考”问题。
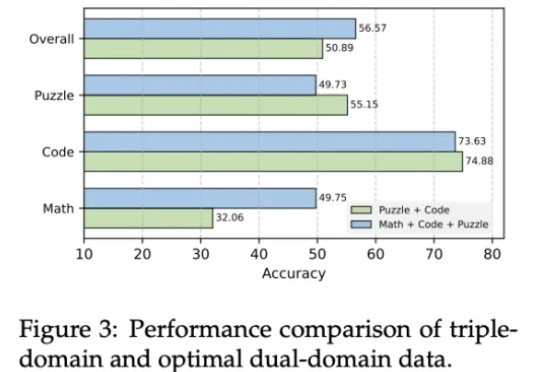
近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。
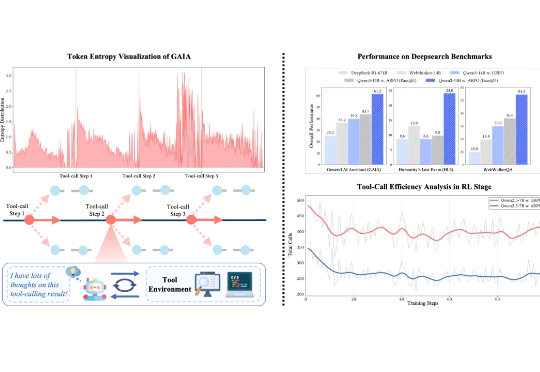
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。
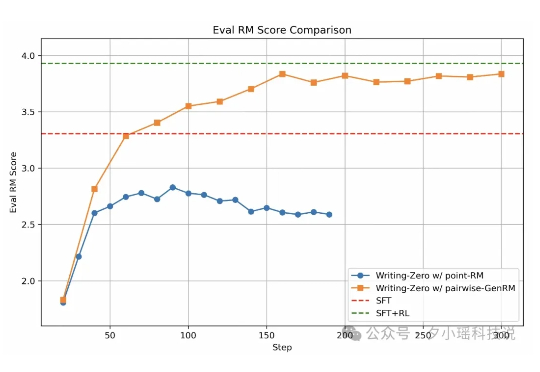
近年来, 大语言模型 (LLM) 在数学、编程等 "有标准答案" 的任务上取得了突破性进展, 这背后离不开 "可验证奖励" (Reinforcement Learning with Verifiable Rewards, RLVR) 技术的加持。RLVR 依赖于参考信号, 即通过客观标准答案来验证模型响应的可靠性。
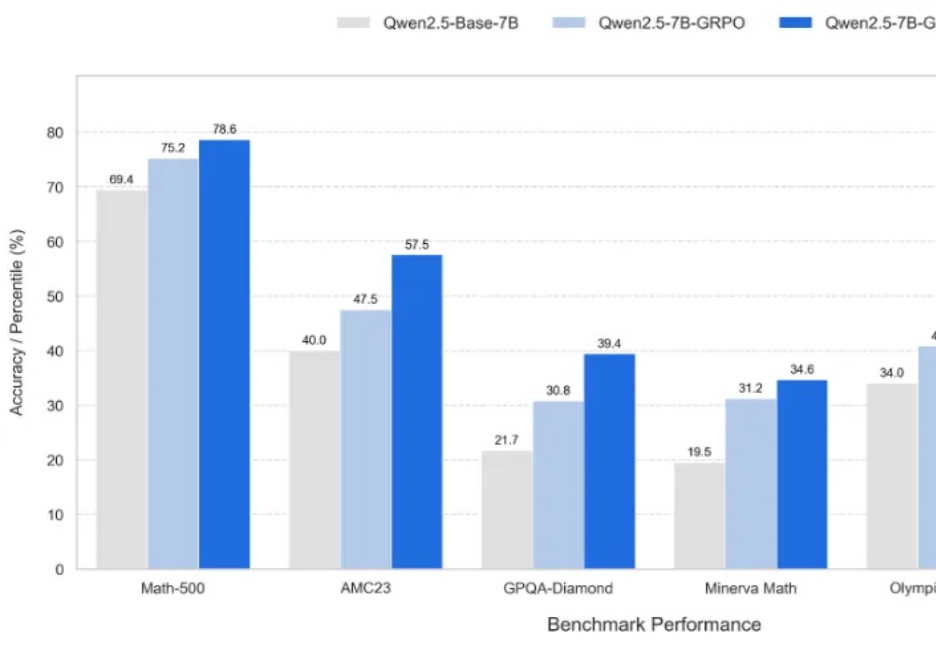
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
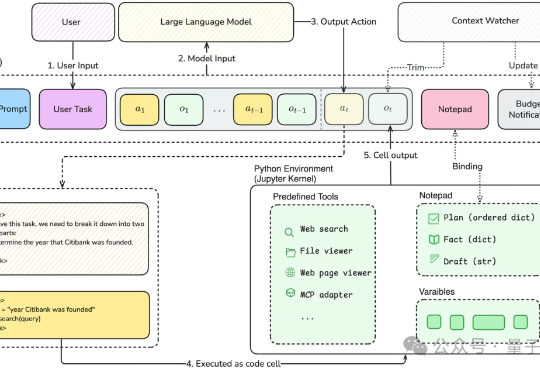
大模型可以不再依赖人类调教,真正“自学成才”啦?新研究仅通过RLVR(可验证奖励的强化学习),成功让模型自主进化出通用的探索、验证与记忆能力,让模型学会“自学”!
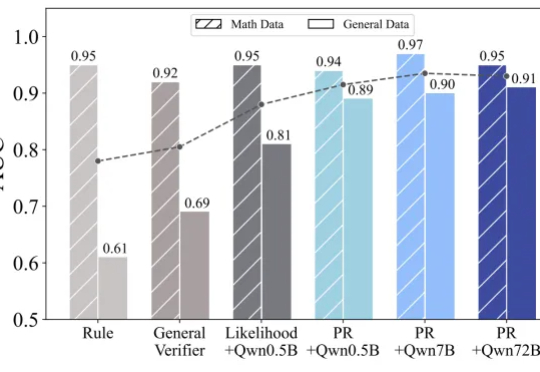
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward

AI顶流Claude升级了,程序员看了都沉默:不仅能写代码能力更强了,还能连续干活7小时不出大差错!AGI真要来了?这背后到底发生了什么?现在,还有机会加入AI行业吗?如今做哪些准备,才能在未来立足?
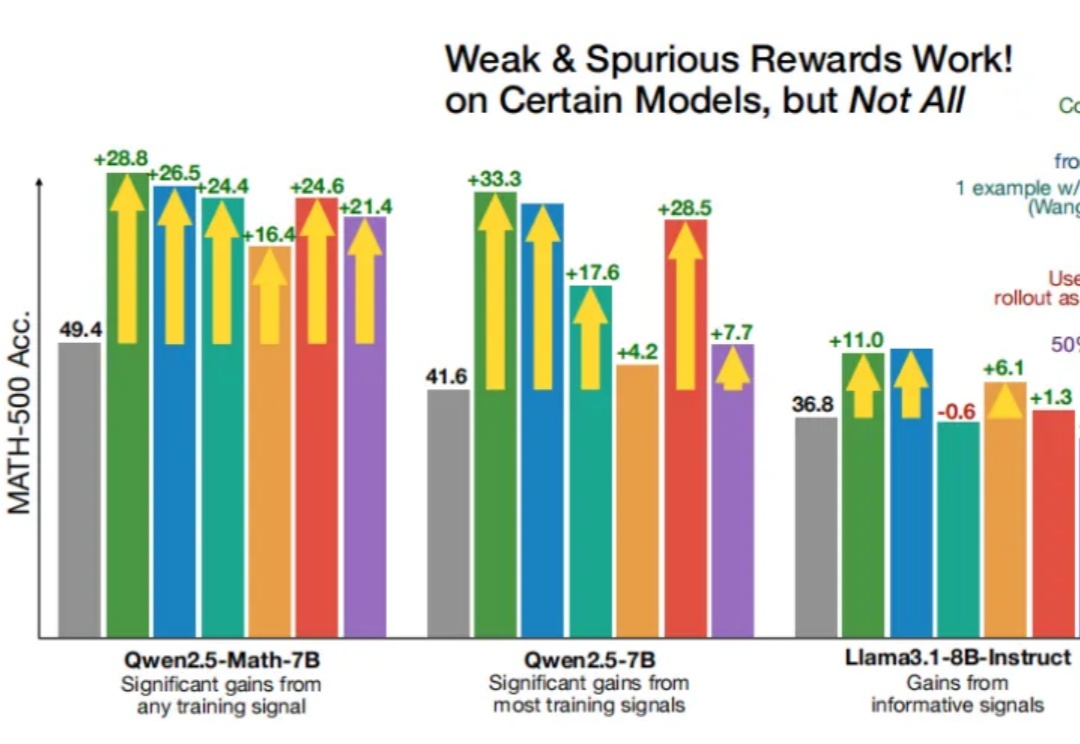
即使RLVR(可验证奖励强化学习)使用错误的奖励信号,Qwen性能也能得到显著提升?