快手开源GoLongRL:23K样本、9大任务类型,长上下文RL荒的时代结束了
快手开源GoLongRL:23K样本、9大任务类型,长上下文RL荒的时代结束了本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集
来自主题: AI技术研报
7591 点击 2026-06-20 10:21
 搜索
搜索
本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集
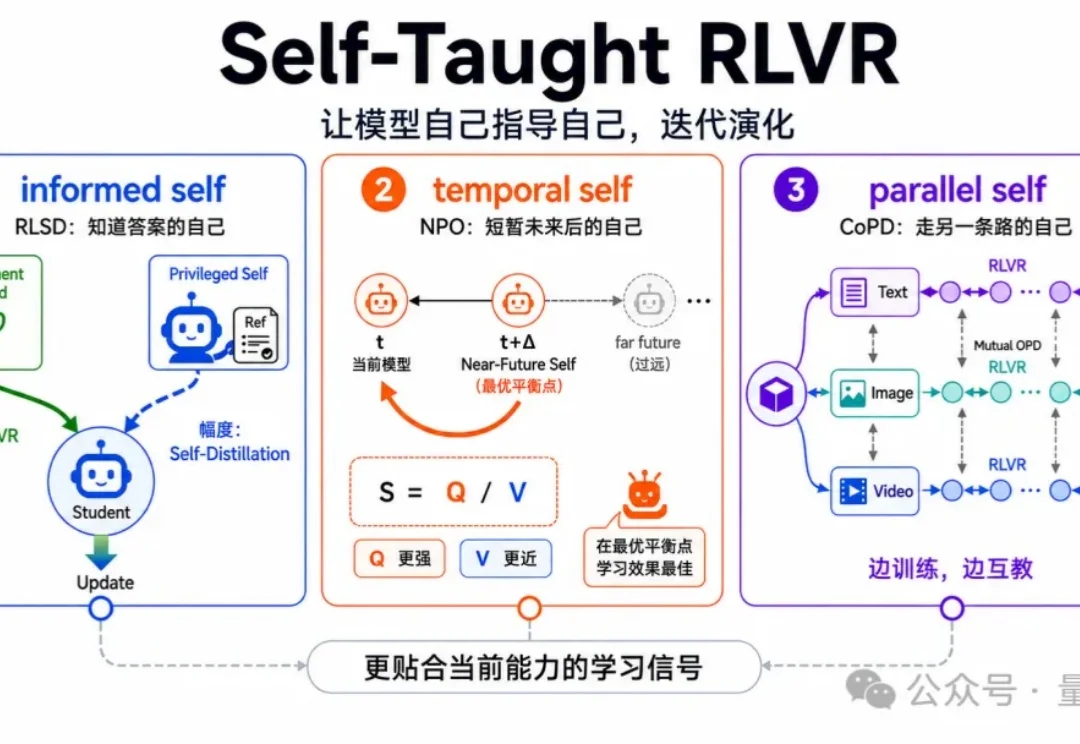
最近,京东和中科院信工所展开了Self-Taught RLVR的系列研究,并连发三篇后训练新作。
I²B-LPO 是一个面向 RLVR 后训练的探索增强框架,通过改进 rollout 策略引导模型生成更多样化的推理轨迹,将探索行为从 “重复采样” 推进到 “在关键节点生成更具区分度的推理轨迹”,在多个数学基准上同时提升准确率与语义多样性,最高分别达 5.3% 和 7.4%。该工作接收于 ACL 2026 Main,来自阿里达摩院 - 智能决策团队。

RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。

最近不论是在学术圈还是产业实践中,对于RLVR和传统SFT之间的区别与联系,以及RL本身基于奖励建模反馈机制并结合不同的策略优化算法过程中对模型显性知识的学习和隐参数空间的变化的讨论热度一直很高。
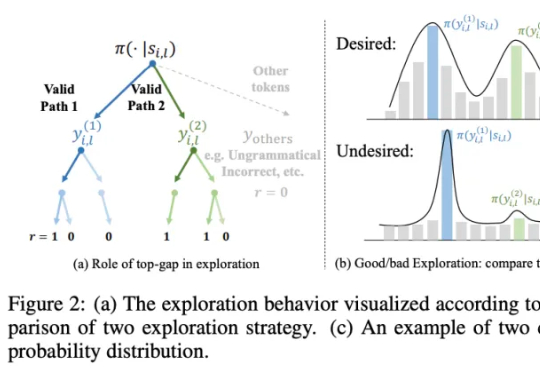
研究团队提出一种简洁且高效的算法 ——SimKO (Simple Pass@K Optimization),显著优化了 pass@K(K=1 及 K>1)性能。同时,团队认为当前的用熵(Entropy)作为指标衡量多样性存在局限:熵无法具体反映概率分布的形态。如图 2(c)所示,两个具有相同熵值的分布,一个可能包含多个峰值,而另一个则可能高度集中于一个峰值。
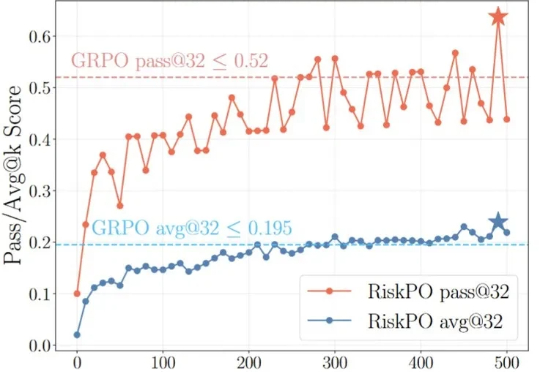
当强化学习(RL)成为大模型后训练的核心工具,「带可验证奖励的强化学习(RLVR)」凭借客观的二元反馈(如解题对错),迅速成为提升推理能力的主流范式。从数学解题到代码生成,RLVR 本应推动模型突破「已知答案采样」的局限,真正掌握深度推理逻辑 —— 但现实是,以 GRPO 为代表的主流方法正陷入「均值优化陷阱」。
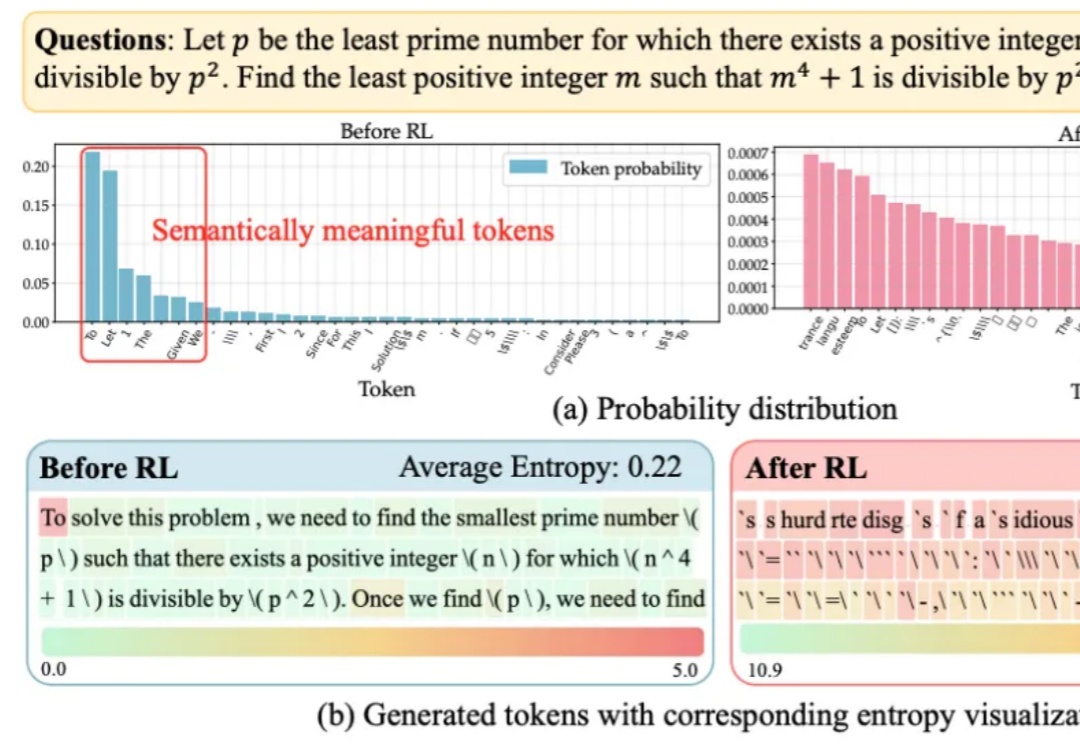
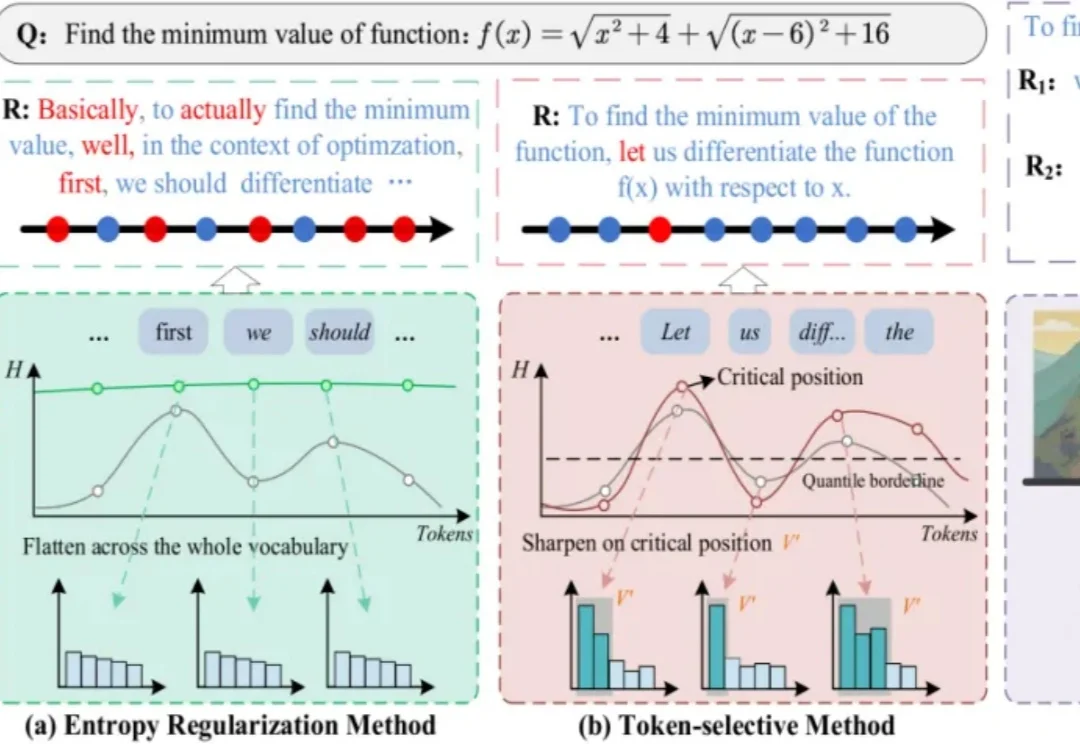
大语言模型在RLVR训练中面临的“熵困境”,有解了!

结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。