
训练加速40倍、打破“不可能三角”:MiniMax Agent RL 架构解密
训练加速40倍、打破“不可能三角”:MiniMax Agent RL 架构解密随着 MiniMax M2.5 的发布并在社区引发热烈反响,很高兴能借此机会,分享在模型训练背后关于 Agent RL 系统的一些思考。 在大规模、复杂的真实世界场景中跑 RL 时,始终面临一个核心难
来自主题: AI技术研报
8325 点击 2026-02-15 06:50
 搜索
搜索
随着 MiniMax M2.5 的发布并在社区引发热烈反响,很高兴能借此机会,分享在模型训练背后关于 Agent RL 系统的一些思考。 在大规模、复杂的真实世界场景中跑 RL 时,始终面临一个核心难
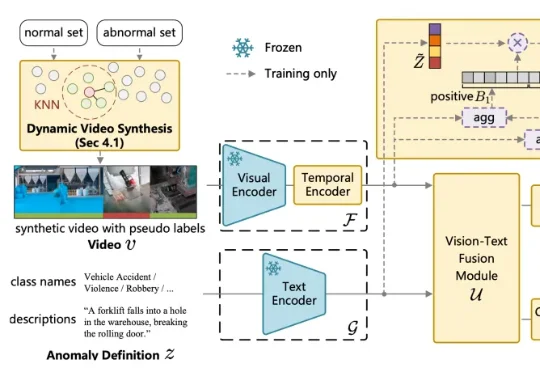
针对这一问题,中国传媒大学媒体融合与传播国家重点实验室的吴晓雨教授团队于 ICLR 2026 发表论文《Language-guided Open-world Video Anomaly Detection under Weak Supervision》,直面 VAD 领域的核心问题 —— 什么是异常?

TwinRL用手机扫一遍场景构建数字孪生,让机器人先在数字孪生里大胆探索、精准试错,再回到真机20分钟跑满全桌面100%成功率——比现有方法快30%,人类干预减少一半以上。

首个统一系统:将物理机器人提升为与 GPU 同等的计算资源,打破硬件隔阂。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
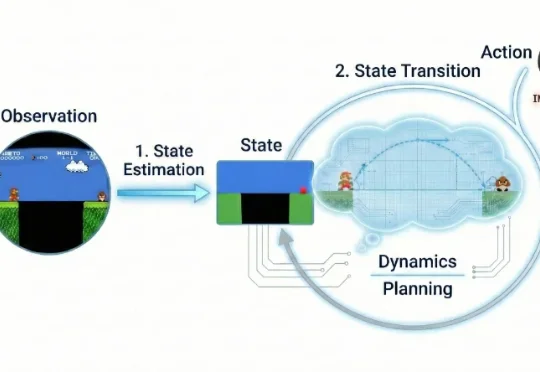
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。

27岁独立开发者靠它月入数万,前市场经理睡觉时它写邮件赚钱,柏林辍学生卖自定义技能赚12.7万美元——AI智能体的「iPhone时刻」已来,只是钱还没平均分。
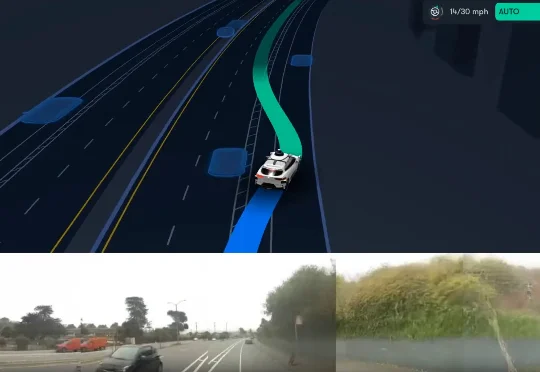
刚刚,Alphabet 旗下的自动驾驶汽车公司 Waymo,推出了最新世界模型 Waymo World Model,其基于 DeepMind 的 Genie 3 构建,在大规模、超真实自动驾驶仿真方面树立了全新的行业标杆。
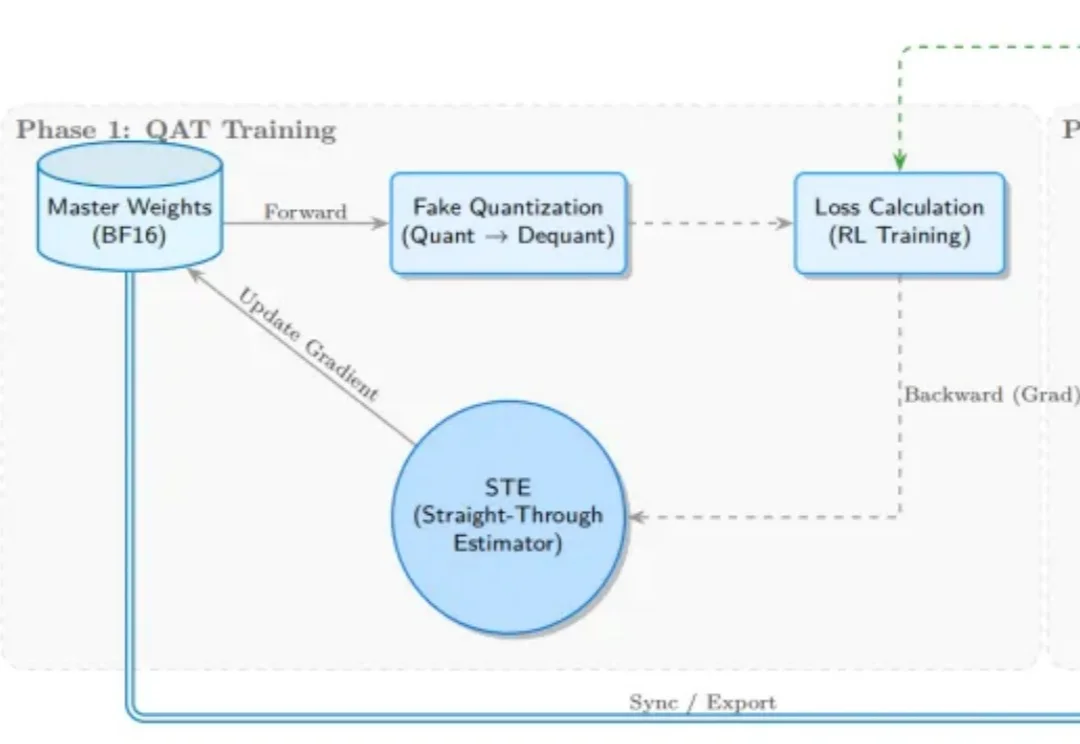
受 Kimi K2 团队启发,SGLang RL 团队成功落地了 INT4 量化感知训练(QAT) 流程方案。通过 “训练端伪量化 + 推理端真实量化(W4A16)” 的方案组合,我们实现了媲美 BF16 全精度训练的稳定性与训推一致性,
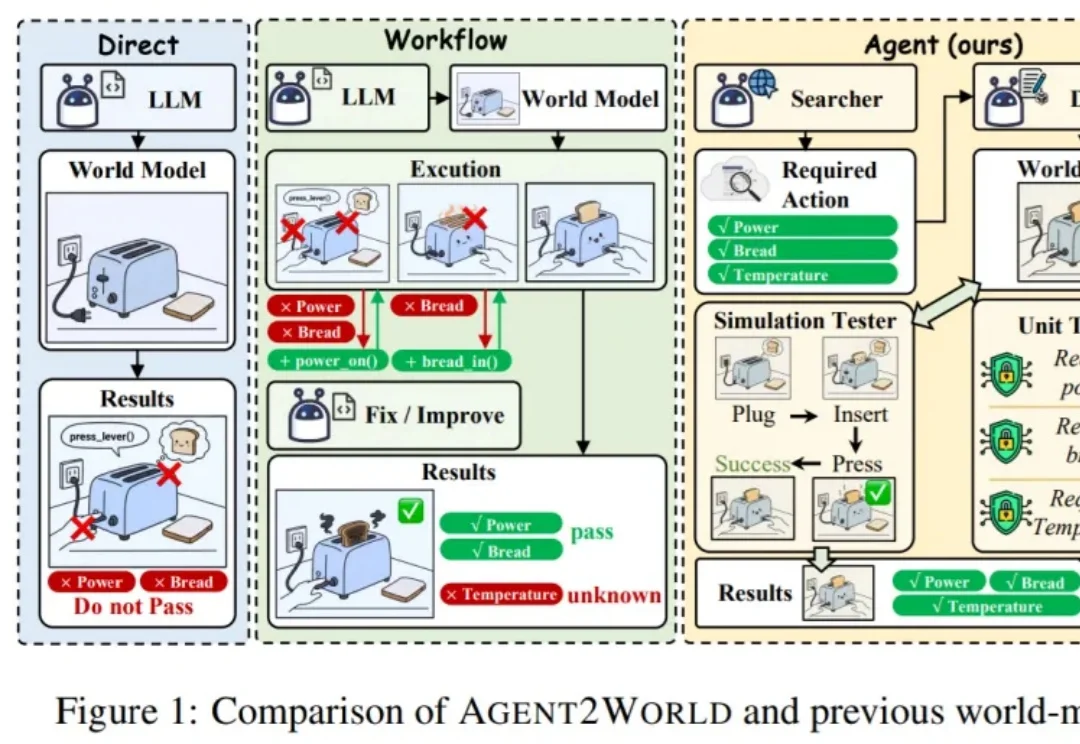
让模型真正 “能行动”,往往需要一个可执行、可验证的符号世界模型(Symbolic World Model):它不是抽象的文字描述,而是能被规划器或执行器直接调用的形式化定义 —— 例如 PDDL 领域 / 问题,或可运行的环境代码 / 模拟器。