
国产模型开源封神,谷歌Genie3紧急开源?蚂蚁AGI撕开世界模型闭源防线
国产模型开源封神,谷歌Genie3紧急开源?蚂蚁AGI撕开世界模型闭源防线世界模型迎来高光时刻:谷歌还在闭源,中国团队已经把SOTA级世界模型全面开源了,LingBot-World正面硬刚Genie 3,彻底打破了全球垄断!
来自主题: AI资讯
8366 点击 2026-01-29 20:16
 搜索
搜索
世界模型迎来高光时刻:谷歌还在闭源,中国团队已经把SOTA级世界模型全面开源了,LingBot-World正面硬刚Genie 3,彻底打破了全球垄断!

据彭博社消息:李飞飞创办的World Labs正在以约50亿美元估值进行新一轮融资,融资规模最高可达5亿美元。如果融资完成:World Labs的估值将从2024年的10亿美元,直接乘5到50亿美元。
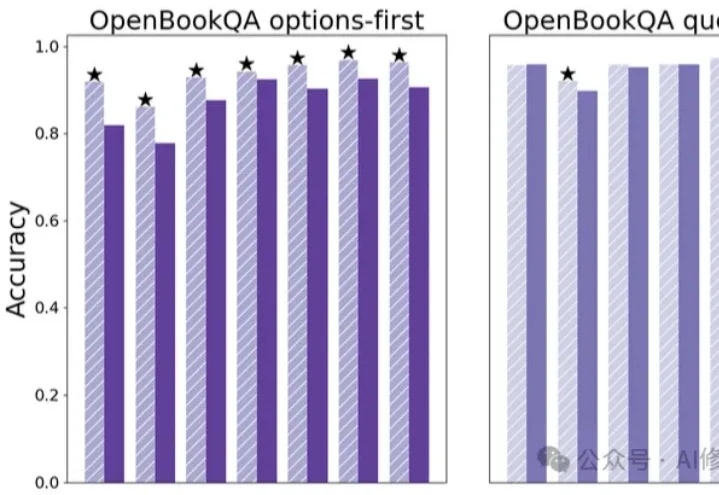
竟然只需要一次Ctrl+V?这可能是深度学习领域为数不多的“免费午餐”。

不要被AI的温柔表象欺骗! Anthropic最新研究刺穿了AGI的温情假象:你以为在和良师益友倾诉,其实是在悬崖边给「杀手」松绑。 当脆弱情感遇上激活值坍塌,RLHF防御层将瞬间溃缩。既然无法教化野兽,人类只能选择最冷酷的「赛博脑叶切除术」。
最火世界模型,最火具身智能基建,联手了!
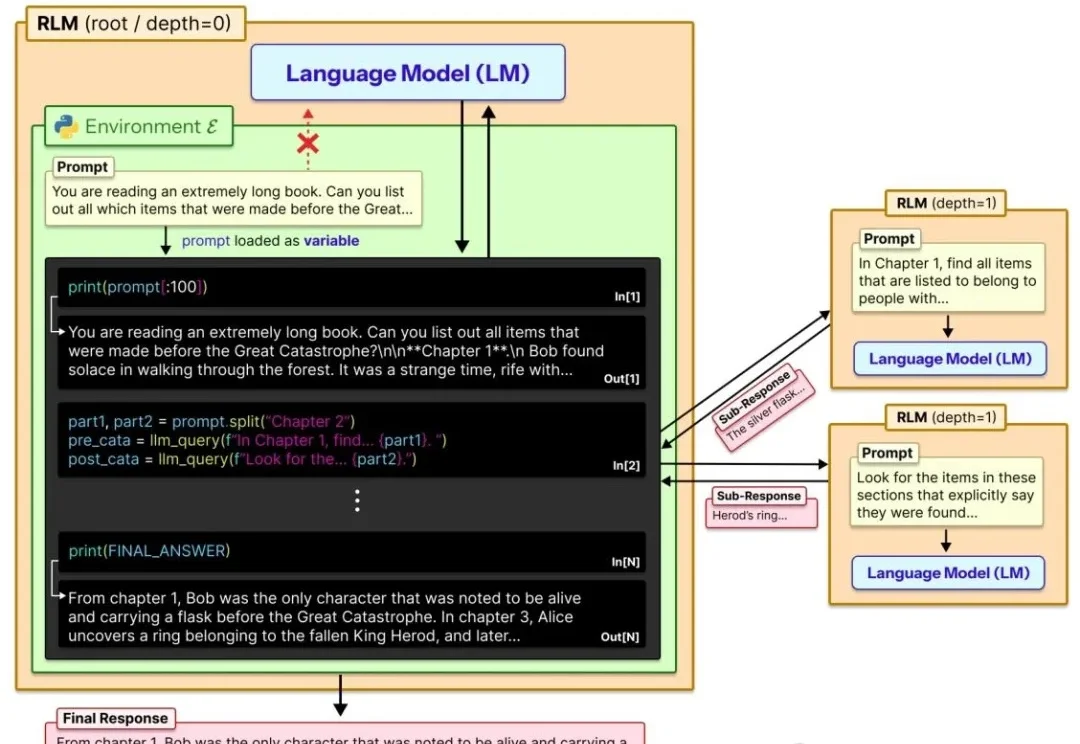
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!

还记得那个穿着「Lululemon」紧身衣、主打温柔陪伴的家用人形机器人 NEO 吗?

2025 年 9 月,The Information 报道 Anthropic 曾讨论在接下来一年内投入超过 10 亿美元用于 RL 环境建设。Epoch AI 最近发了一篇报告,采访了 18 位来自 RL 环境初创公司、neolab(Cursor 这类应用型 AI 公司)和前沿实验室的从业者
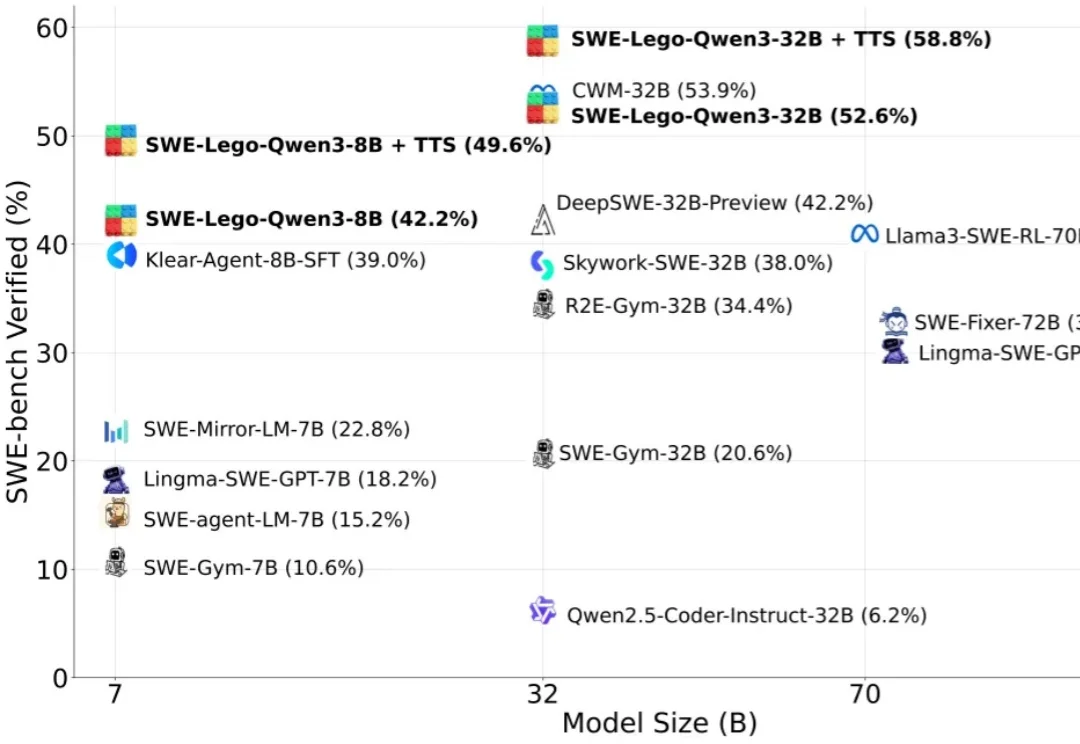
“软工任务要改多文件、多轮工具调用,模型怎么学透?高质量训练数据稀缺,又怕轨迹含噪声作弊?复杂 RL 训练成本高,中小团队望而却步?”

近年来,视频扩散模型在 “真实感、动态性、可控性” 上进展飞快,但它们大多仍停留在纯 RGB 空间。模型能生成好看的视频,却缺少对三维几何的显式建模。这让许多世界模型(world model)导向的应用(空间推理、具身智能、机器人、自动驾驶仿真等)难以落地,因为这些任务不仅需要像素,还需要完整地模拟 4D 世界。