
ICLR25|打开RL黑盒,首次证明强化学习存在内在维度瓶颈
ICLR25|打开RL黑盒,首次证明强化学习存在内在维度瓶颈一句话概括,原来强化学习的“捷径”是天生的,智能体能去的地方(流形)被动作维度(低维流形)限制得死死的,根本没机会去那些没用的高维空间瞎逛。
来自主题: AI资讯
7265 点击 2025-08-05 11:59
一句话概括,原来强化学习的“捷径”是天生的,智能体能去的地方(流形)被动作维度(低维流形)限制得死死的,根本没机会去那些没用的高维空间瞎逛。
2025年的IMO,好戏不断。 7月19日,全世界顶尖大模型在2025年的IMO赛场上几乎全军覆没。时隔1天,OpenAI、DeepMind等顶尖实验室就在IMO 2025赛场斩获5/6题,震惊数学圈。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
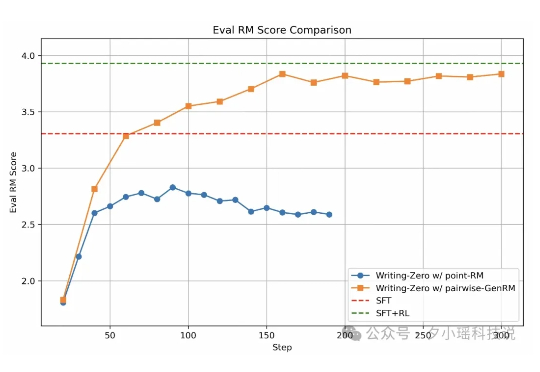
近年来, 大语言模型 (LLM) 在数学、编程等 "有标准答案" 的任务上取得了突破性进展, 这背后离不开 "可验证奖励" (Reinforcement Learning with Verifiable Rewards, RLVR) 技术的加持。RLVR 依赖于参考信号, 即通过客观标准答案来验证模型响应的可靠性。
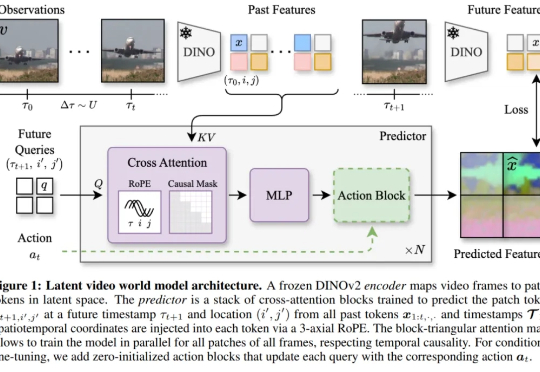
2018 年,LSTM 之父 Jürgen Schmidhuber 在论文中( Recurrent world models facilitate policy evolution )推广了世界模型(world model)的概念,这是一种神经网络,它能够根据智能体过去的观察与动作,预测环境的未来状态。
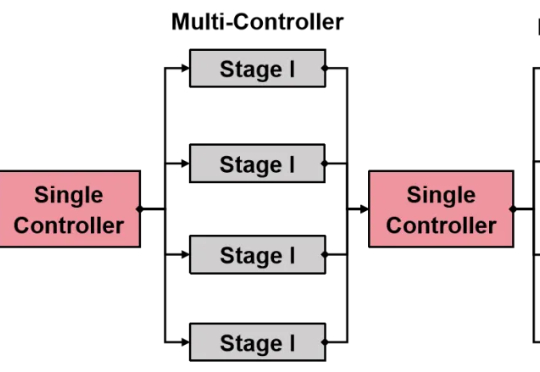
还在为强化学习(RL)框架的扩展性瓶颈和效率低下而烦恼吗?
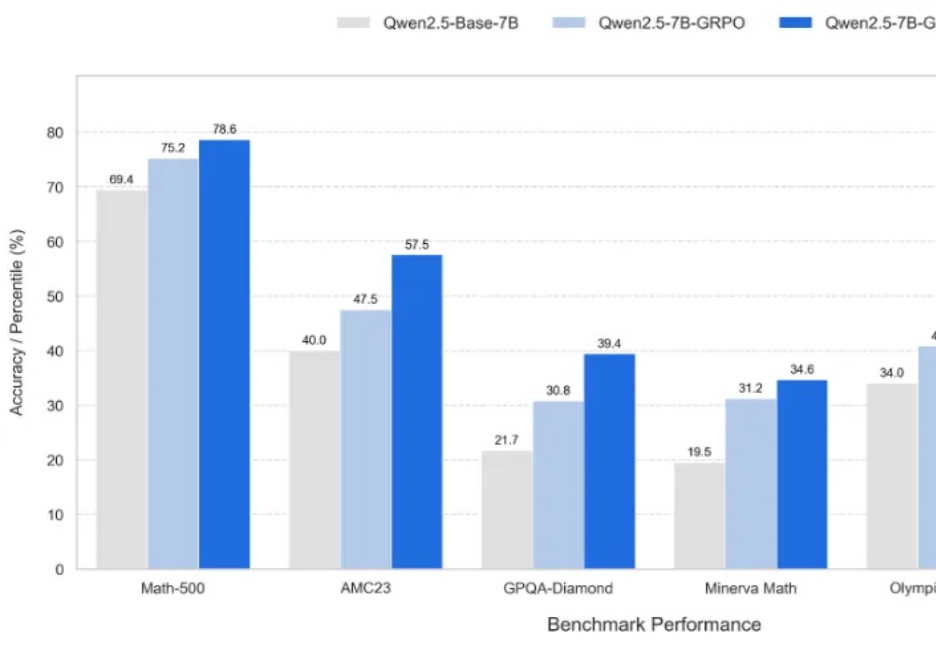
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
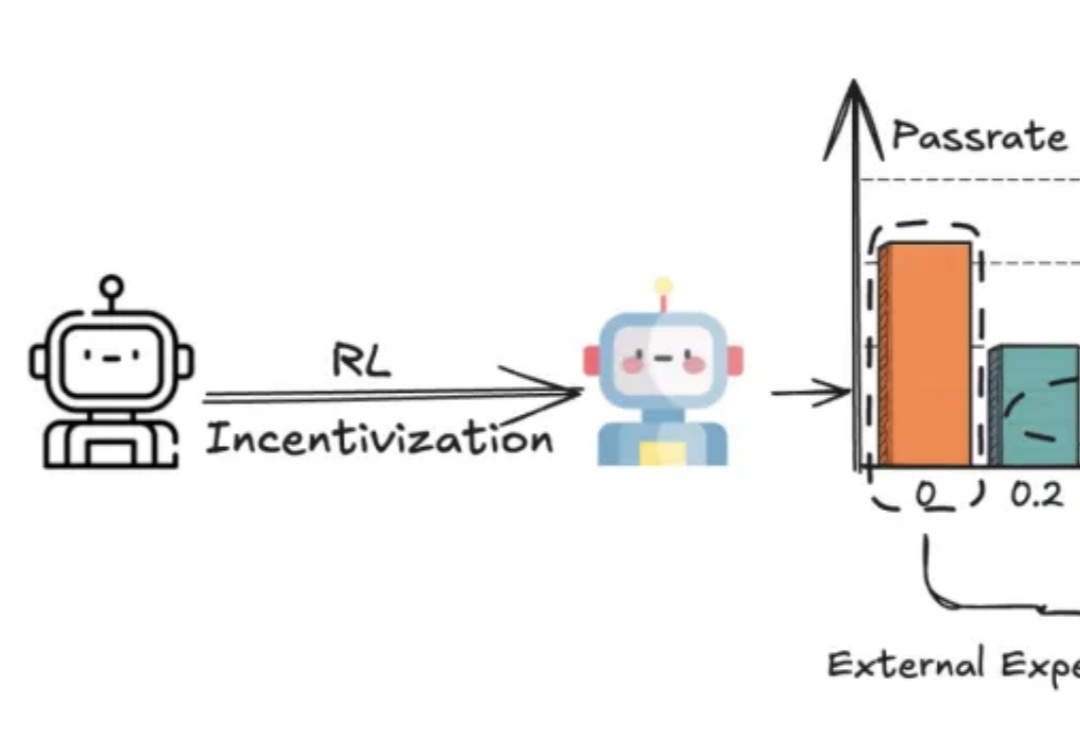
多模态推理,也可以讲究“因材施教”?
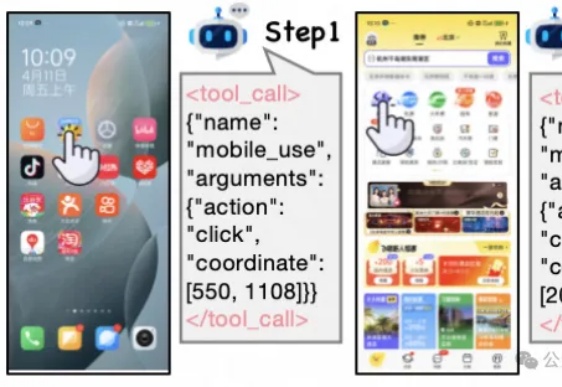
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。

MiniMax 在 7 月 10 日面向全球举办了 M1 技术研讨会,邀请了来自香港科技大学、滑铁卢大学、Anthropic、Hugging Face、SGLang、vLLM、RL领域的研究者及业界嘉宾,就模型架构创新、RL训练、长上下文应用等领域进行了深入的探讨。