大型语言模型稳定强化学习的新路径:几何平均策略优化GMPO
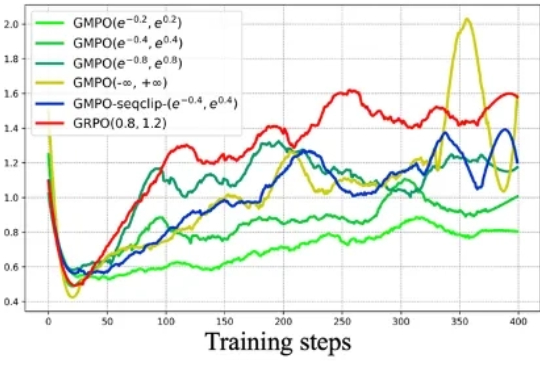
大型语言模型稳定强化学习的新路径:几何平均策略优化GMPO近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
来自主题: AI技术研报
7422 点击 2025-08-13 16:03