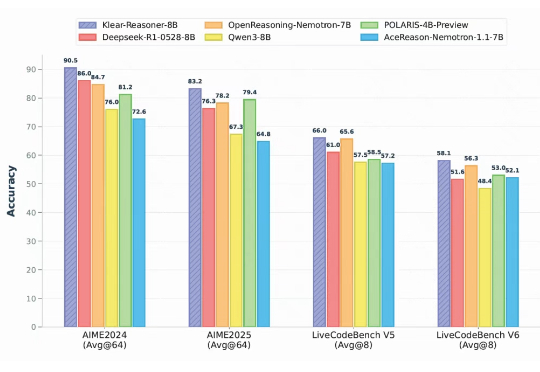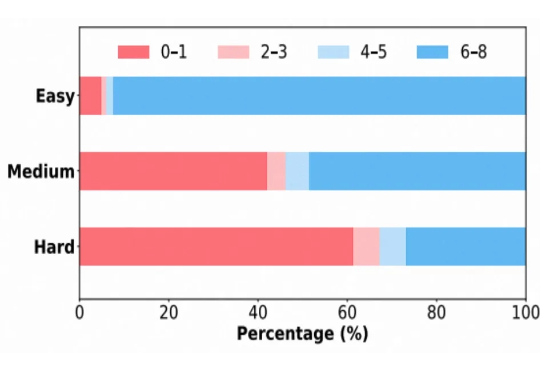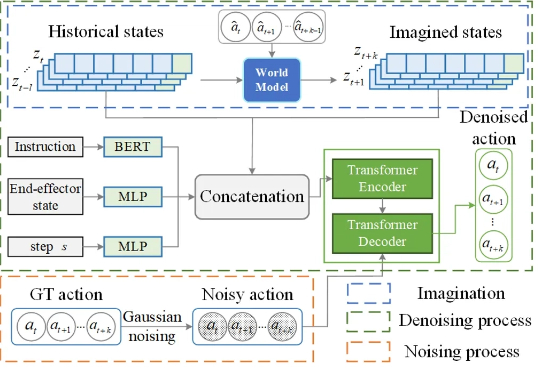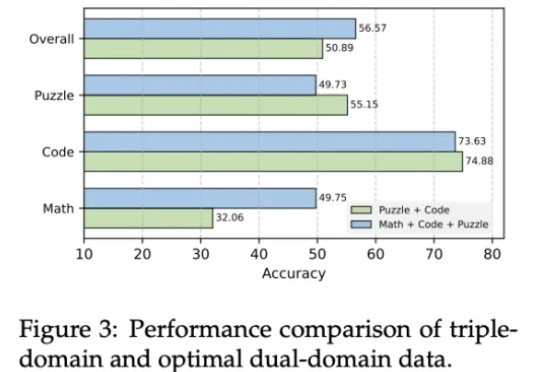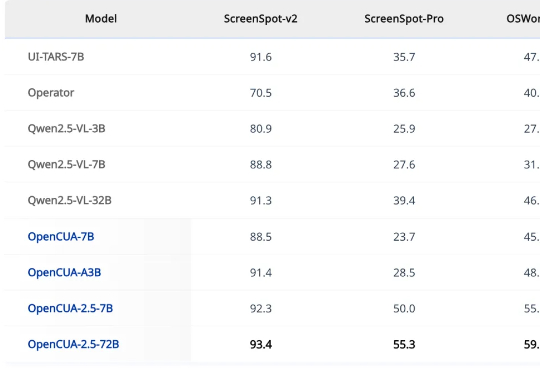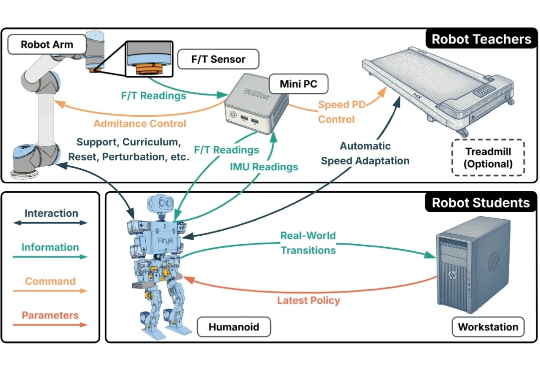
手把手教机器人:斯坦福大学提出RTR框架,让机械臂助力人形机器人真机训练
手把手教机器人:斯坦福大学提出RTR框架,让机械臂助力人形机器人真机训练人形机器人的运动控制,正成为强化学习(RL)算法应用的下一个热点研究领域。当前,主流方案大多遵循 “仿真到现实”(Sim-to-Real)的范式。研究者们通过域随机化(Domain Randomization)技术,在成千上万个具有不同物理参数的仿真环境中训练通用控制模型,期望它能凭借强大的泛化能力,直接适应动力学特性未知的真实世界。
来自主题: AI技术研报
8325 点击 2025-08-27 11:05