
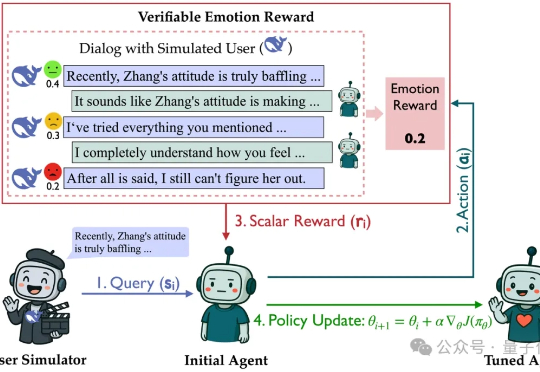
7B模型“情商”比肩GPT-4o,腾讯突破开放域RL难题,得分直翻5倍
7B模型“情商”比肩GPT-4o,腾讯突破开放域RL难题,得分直翻5倍在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。
来自主题: AI技术研报
8070 点击 2025-07-19 11:13
在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。
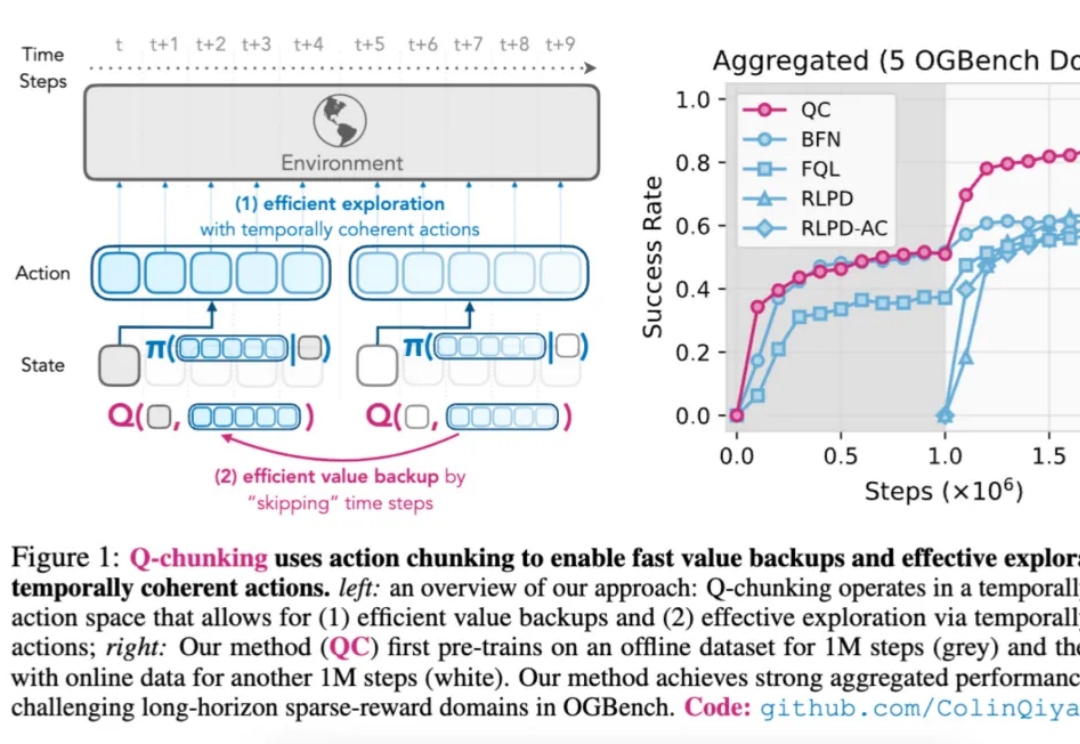
如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。
今年AI最离谱也最让人上头的用法,可能不是写代码、写论文,而是算命。

「停止研究 RL 吧,研究者更应该将精力投入到产品开发中,真正推动人工智能大规模发展的关键技术是互联网,而不是像 Transformer 这样的模型架构。」
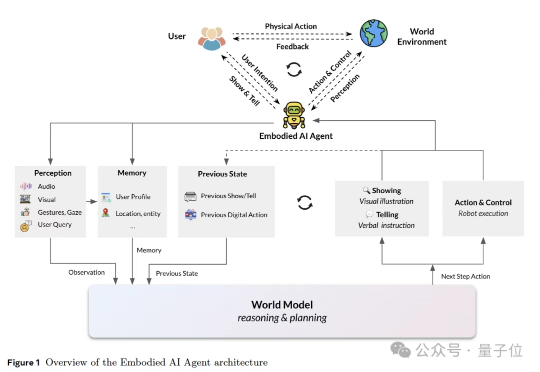
这篇报告第一次把对人心智状态的推断,放到和物理世界模型(physical world model)同等重要的位置上,并将其概念化为心智世界模型(mental world model)。相比于传统世界模型(如LeCun的JEPA)仅关注物理规律(物体运动、机械因果),心智世界模型则首次将心理规律(意图、情感、社会关系)纳入世界模型框架,实现“双轨建模”。
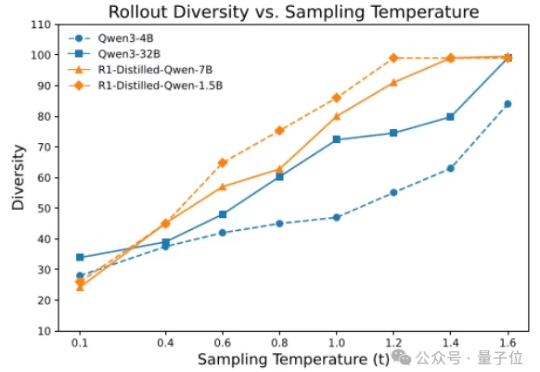
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。

在多模态大语言模型(MLLMs)应用日益多元化的今天,对模型深度理解和分析人类意图的需求愈发迫切。尽管强化学习(RL)在增强大语言模型(LLMs)的推理能力方面已展现出巨大潜力,但将其有效应用于复杂的多模态数据和格式仍面临诸多挑战。
「哈喽,可以听到吗?」北京时间上午 10 点,大洋彼岸的 Pokee.ai 创始人朱哲清接通了我们的连线电话,此刻他正位于美国西海岸,当地时间为前一日晚上 7 点。「哈喽,可以听到吗?」北京时间上午 10 点,大洋彼岸的 Pokee.ai 创始人朱哲清接通了我们的连线电话,此刻他正位于美国西海岸,当地时间为前一日晚上 7 点。

新晋AI编程冠军DeepSWE来了!仅通过纯强化学习拿下基准测试59%的准确率,凭啥?7大算法细节首次全公开。

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。