谷歌的Gemma-4-31B适合哪些人?值得你放弃Qwen3.5-27B吗?深度调研战略报告
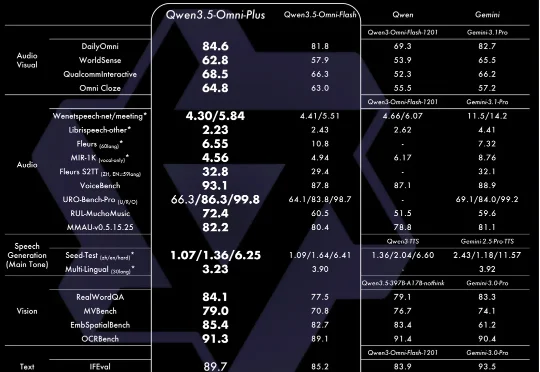
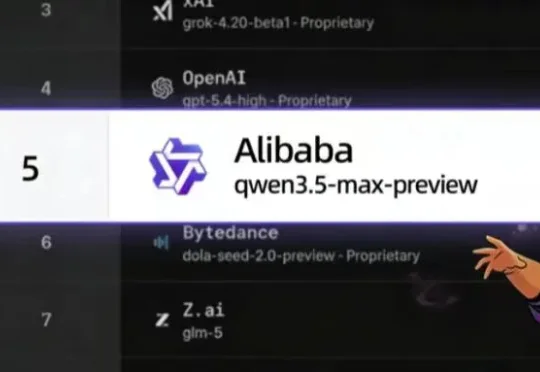
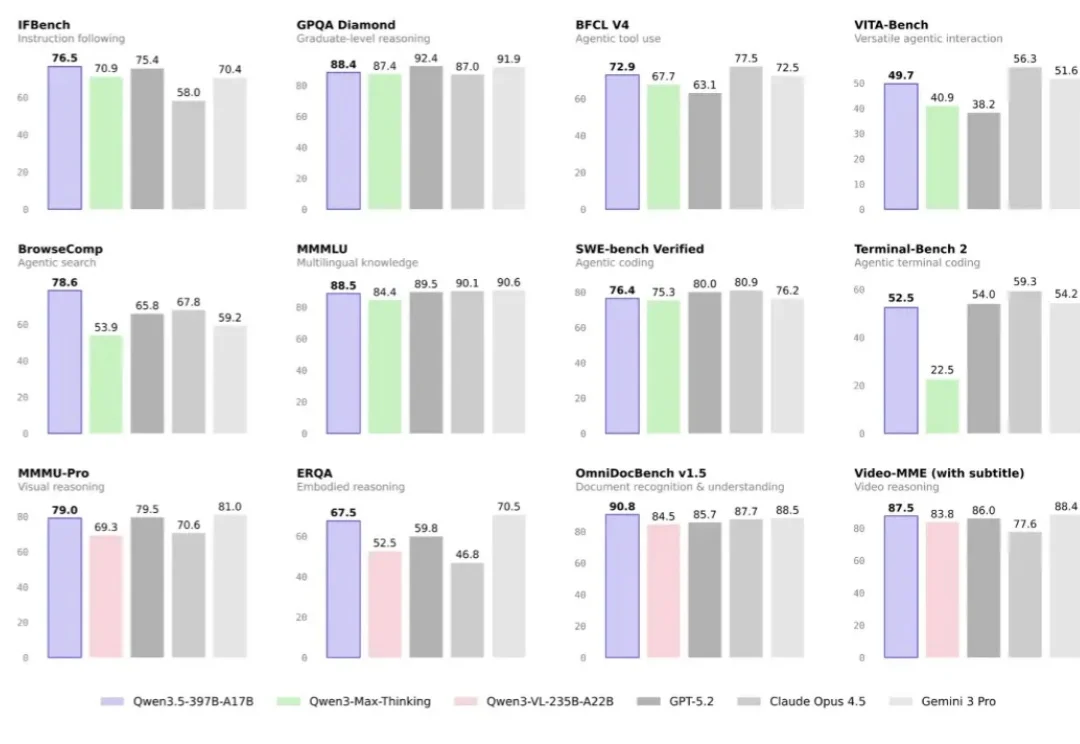
谷歌的Gemma-4-31B适合哪些人?值得你放弃Qwen3.5-27B吗?深度调研战略报告Gemma4 31B的发布,在开源模型社区引发了巨大的关注。面对这款由谷歌DeepMind于2026年4月2日 推出的重磅模型,很多技术团队和本地部署玩家都在问同一个问题:Gemma4的出现,到底是在开辟一条新的本地部署路线,还是只是给高端玩家多了一个可选项?我们到底需不需要把现有的Qwen3.5 27B工作流整体迁移过去?
来自主题: AI技术研报
9429 点击 2026-04-08 16:29