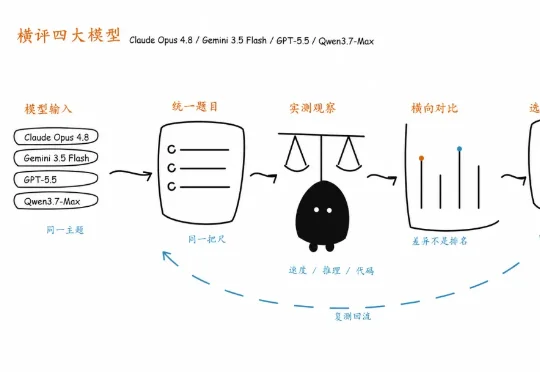
横评 Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,谁更强?
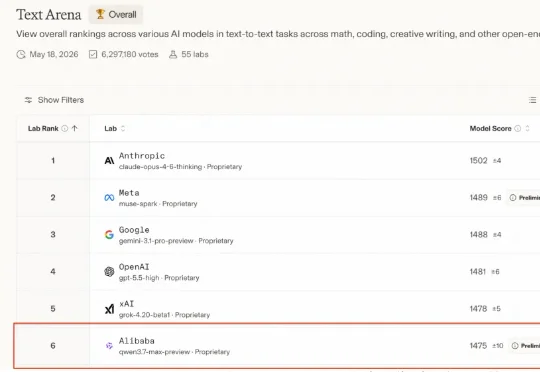
横评 Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,谁更强?普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。
来自主题: AI产品测评
9550 点击 2026-05-30 15:26