
英伟达成美国大模型开源标杆:Nemotron 3连训练配方都公开,10万亿token数据全放出
英伟达成美国大模型开源标杆:Nemotron 3连训练配方都公开,10万亿token数据全放出英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:
来自主题: AI资讯
8452 点击 2025-12-26 15:48
 搜索
搜索
英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:
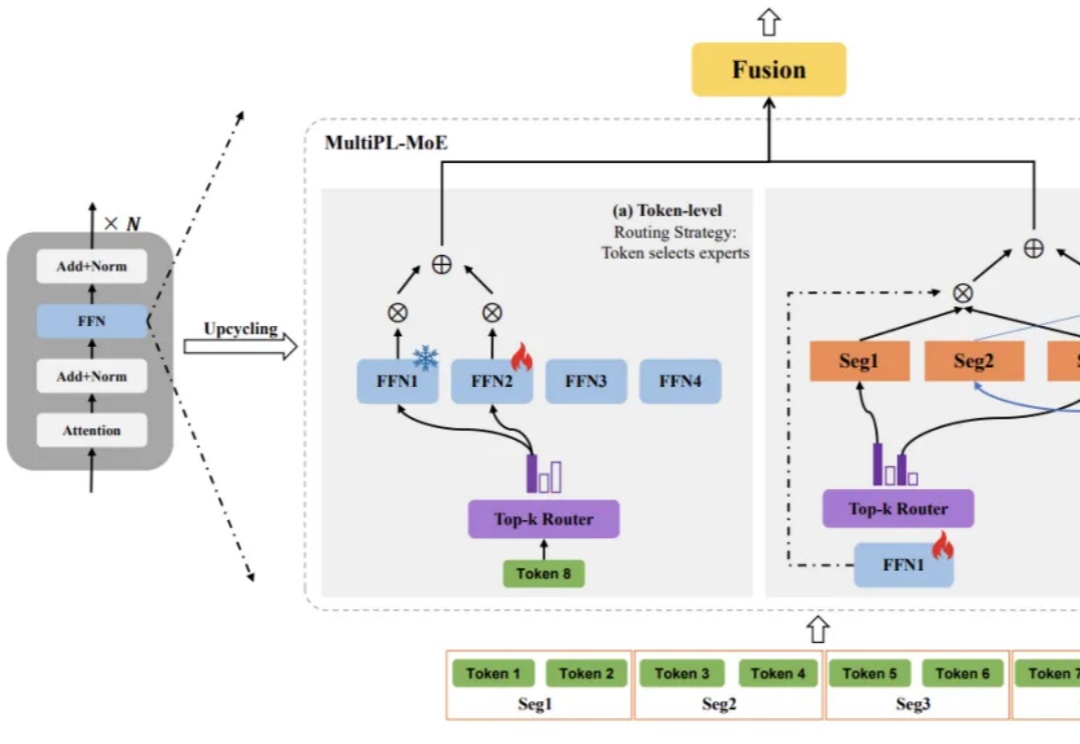
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?

最新进展,Cursor 2.0正式发布,并且首次搭载了「内部」大模型。 没错,不是GPT、不是Claude,如今模型栏多了个新名字——Composer。实力相当炸裂:据官方说法,Composer仅需30秒就能完成复杂任务,比同行快400%
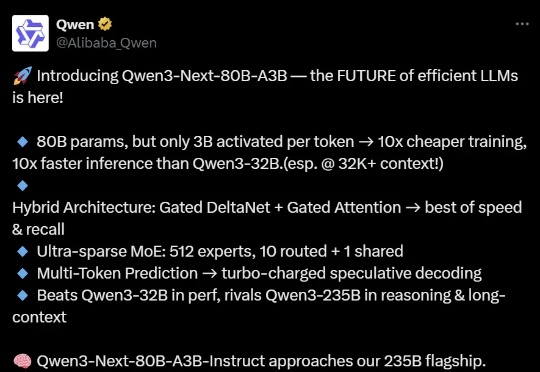
训练、推理性价比创新高。 大语言模型(LLM),正在进入 Next Level。 周五凌晨,阿里通义团队正式发布、开源了下一代基础模型架构 Qwen3-Next。总参数 80B 的模型仅激活 3B ,性能就可媲美千问 3 旗舰版 235B 模型,也超越了 Gemini-2.5-Flash-Thinking,实现了模型计算效率的重大突破。

昨天,美团低调地开源了其560B参数的混合专家(MoE)模型——LongCat-Flash。 一时间,大家的目光都被吸引了过去,行业内的讨论大多围绕着它在公开基准测试中媲美顶尖模型的性能数据,以及其精巧的MoE架构设计。
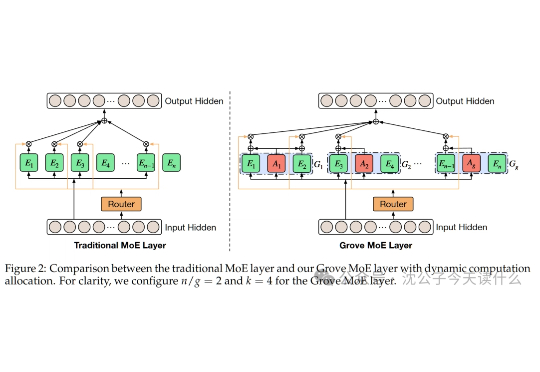
一句话概括,传统MoE就像公司派固定人数团队,Grove MoE则像智能调度系统,小项目派少数人,大项目集中火力,效率与效果兼得。

电影级视频生成模型来了。

近日,月之暗面(Moonshot AI)正式发布了其万亿参数开源大模型Kimi K2,这一具有里程碑意义的AI模型凭借其创新的MoE架构和强大的Agentic能力迅速获得全球开发者关注。然而,随着用户量激增,部分开发者开始反映其API服务响应速度不尽如人意。面对这一情况,月之暗面于7月15日迅速作出官方回应,坦诚当前服务延迟问题,并详细说明了优化方案。
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?

结果点进去一看,我人直接傻了——这家伙用的竟然是 kimi-k2-0711-preview 模型!这个K2模型的简直离谱到家了: 业界第一个说自己是1万亿参数的模型,这规模直接吓人 MoE架构 + 32B激活参数