
多智能体架构Insight-V来了!突破长链视觉推理瓶颈
多智能体架构Insight-V来了!突破长链视觉推理瓶颈大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。
来自主题: AI技术研报
7128 点击 2024-12-13 14:40
 搜索
搜索
大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。

目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。

大语言模型(LLMs)在推理任务上展现出了令人瞩目的能力,但其推理思维方式的单一性一直是制约性能提升的关键瓶颈。目前的研究主要关注如何通过思维链(Chain-of-Thought)等方法来提升推理的质量,却忽视了一个重要维度——推理类型的多样性。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。

当前,生成式AI正席卷整个社会,大语言模型(LLMs)在文本(ChatGPT)和图像(DALL-E)生成方面取得了令人惊叹的成就,仅仅依赖零星几个提示词,它们就能生成超出预期的内容
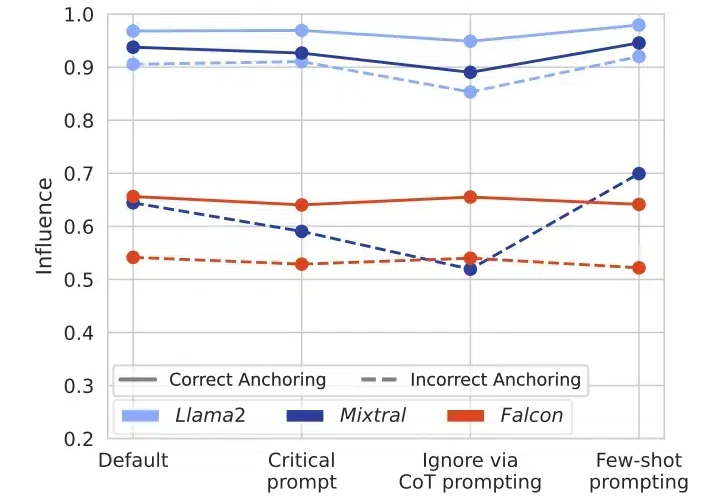
在当今人工智能迅猛发展的时代,大语言模型(LLMs)已成为众多AI应用的核心引擎。然而,来自ETH Zurich和Google DeepMind的一项最新研究揭示了一个令人深思的现象:这些看似强大的模型存在着严重的“盲从效应”。
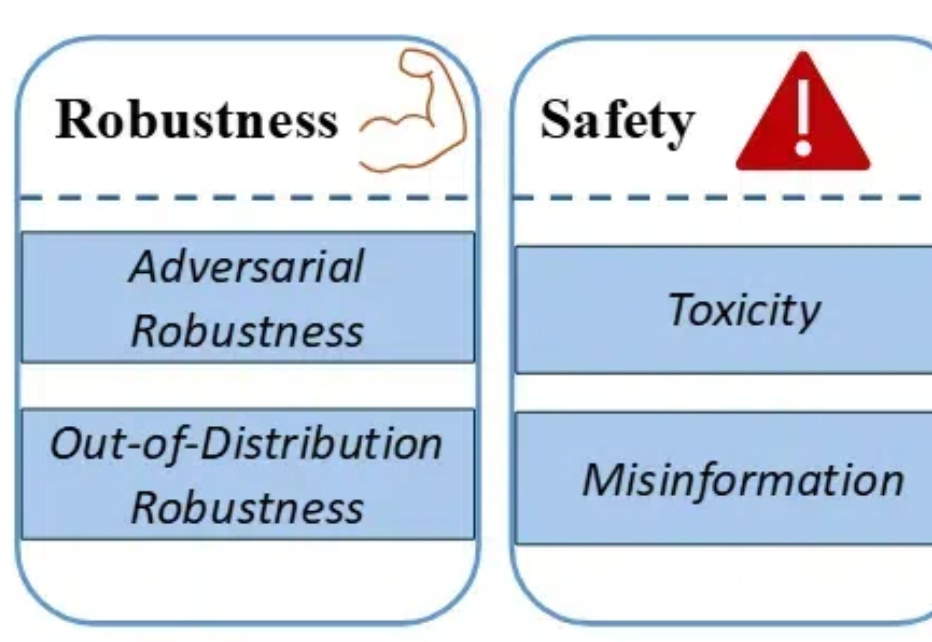
我们对小型语言模型的增强方法、已存在的小模型、应用、与 LLMs 的协作、以及可信赖性方面进行了详细调查。
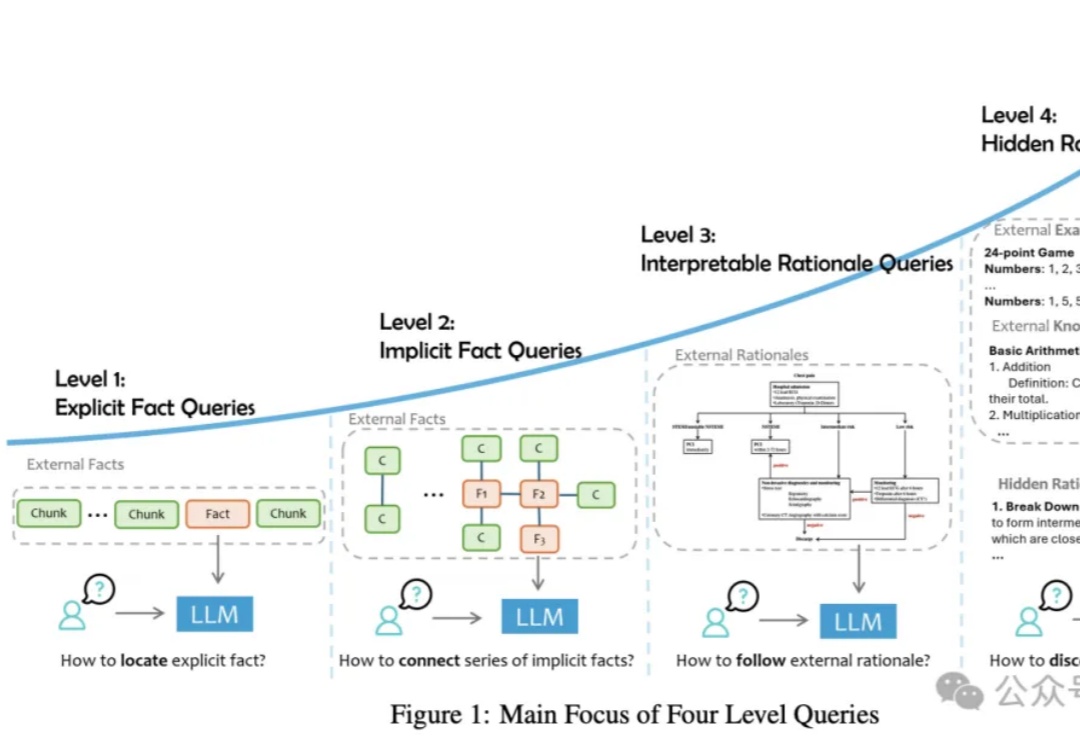
论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。

自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。
大规模语言模型(LLMs)已经在自然语言处理任务中展现了卓越的能力,但它们在复杂推理任务上依旧面临挑战。推理任务通常需要模型具有跨越多个步骤的推理能力,这超出了LLMs在传统训练阶段的表现。