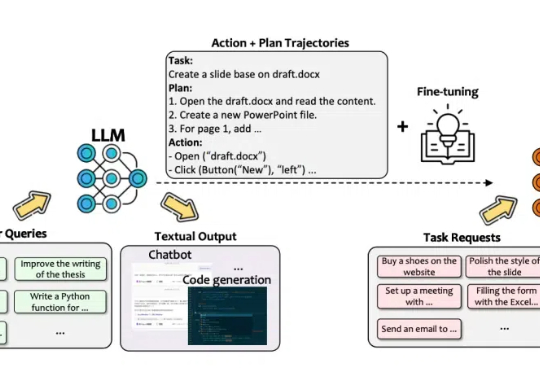
无直接数据可用,AI怎么学会「干活」?微软团队揭秘AI从语言到行动的进化之路
无直接数据可用,AI怎么学会「干活」?微软团队揭秘AI从语言到行动的进化之路该技术报告的主要作者 Lu Wang, Fangkai Yang, Chaoyun Zhang, Shilin He, Pu Zhao, Si Qin 等均来自 Data, Knowledge, and Intelligence (DKI) 团队,为微软 TaskWeaver, WizardLLM, Windows GUI Agent UFO 的核心开发者。
来自主题: AI技术研报
8243 点击 2025-01-21 22:16