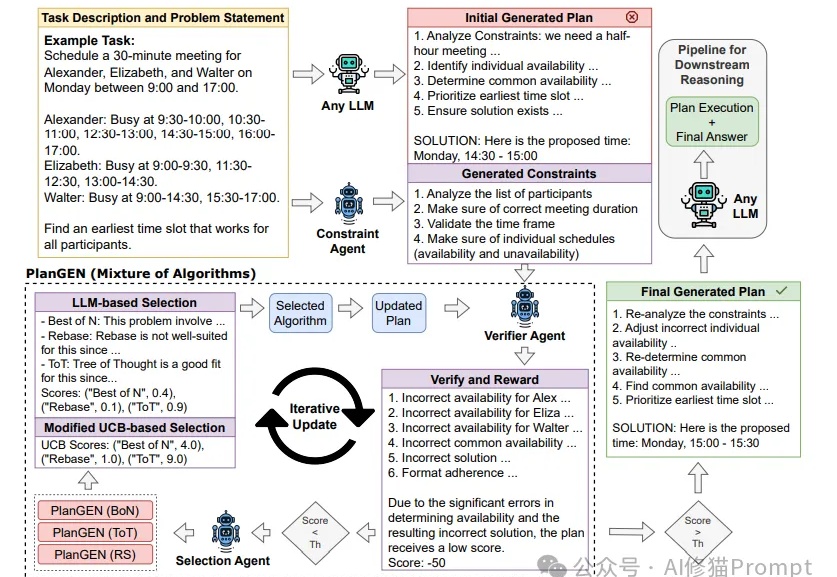
谷歌最新PlanGEN框架,开发自适应Multi-Agent,错过太可惜,不用邀请码
谷歌最新PlanGEN框架,开发自适应Multi-Agent,错过太可惜,不用邀请码Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。
来自主题: AI技术研报
5320 点击 2025-03-06 16:55
 搜索
搜索
Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。

大语言模型(LLMs)在当今的自然语言处理领域扮演着越来越重要的角色,但其安全性问题也引发了广泛关注。
近年来,大型语言模型(LLMs)在代码相关的任务上展现了惊人的表现,各种代码大模型层出不穷。这些成功的案例表明,在大规模代码数据上进行预训练可以显著提升模型的核心编程能力。
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。
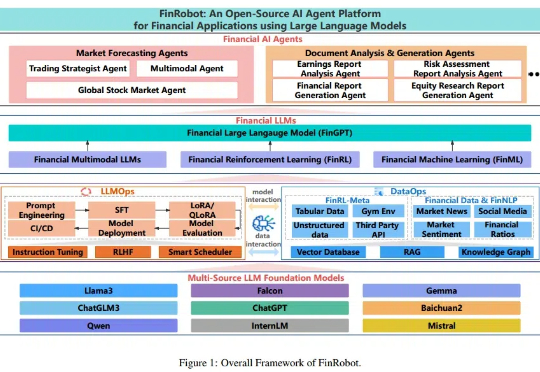
随着金融机构和专业人士越来越多地将大语言模型(LLMs)纳入其工作流程中,金融领域与人工智能社区之间依然存在显著障碍,包括专有数据和专业知识的壁垒。本文提出了 FinRobot,一种支持多个金融专业化人工智能智能体的新型开源 AI 智能体平台,每个代理均由 LLM 提供动力。
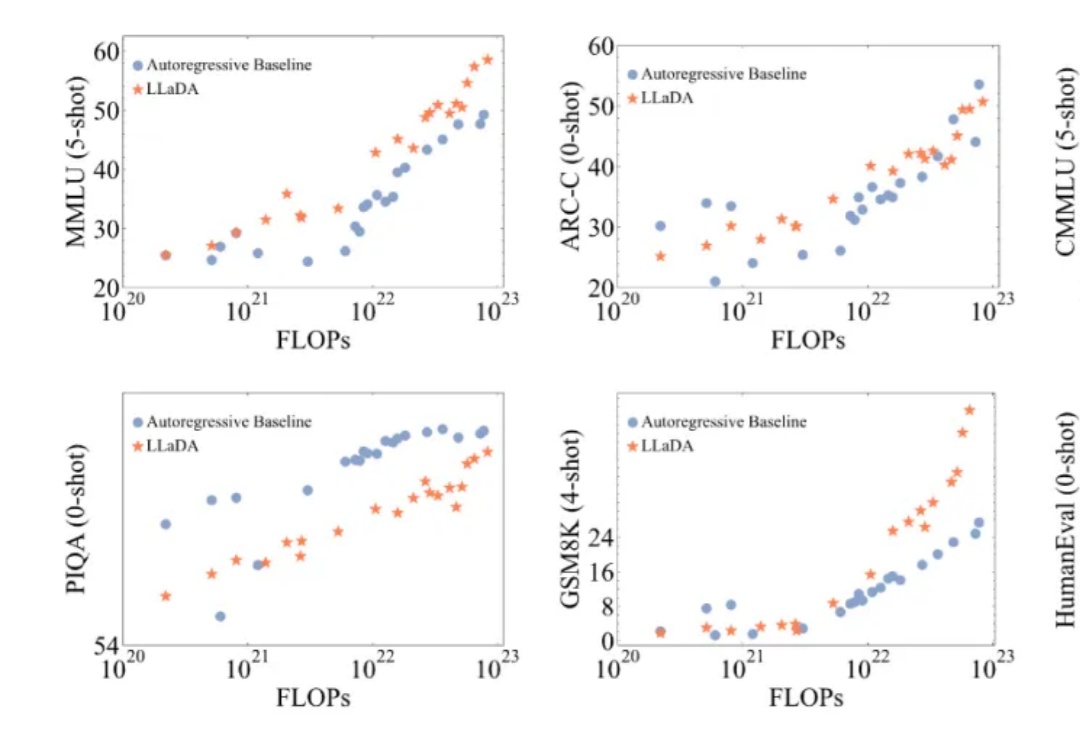
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。

研究人员首次探讨了大型语言模型(LLMs)在问题生成任务中的表现,与人类生成的问题进行了多维度对比,结果发现LLMs倾向于生成需要较长描述性答案的问题,且在问题生成中对上下文的关注更均衡。
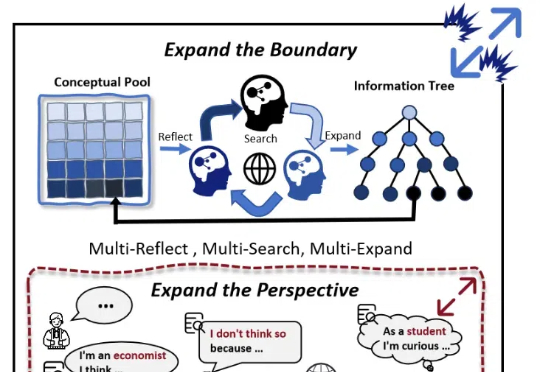
随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。

瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了! 所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。

WaveForms致力于开发音频大模型(LLMs),通过创新的端到端音频处理技术,实现更加实时、类人化且情感智能化的语音交互。与传统语音模型不同,WaveForms的音频模型不是语音转文本再转语音,而是能够直接处理音频,实现更自然的对话和情感互动。