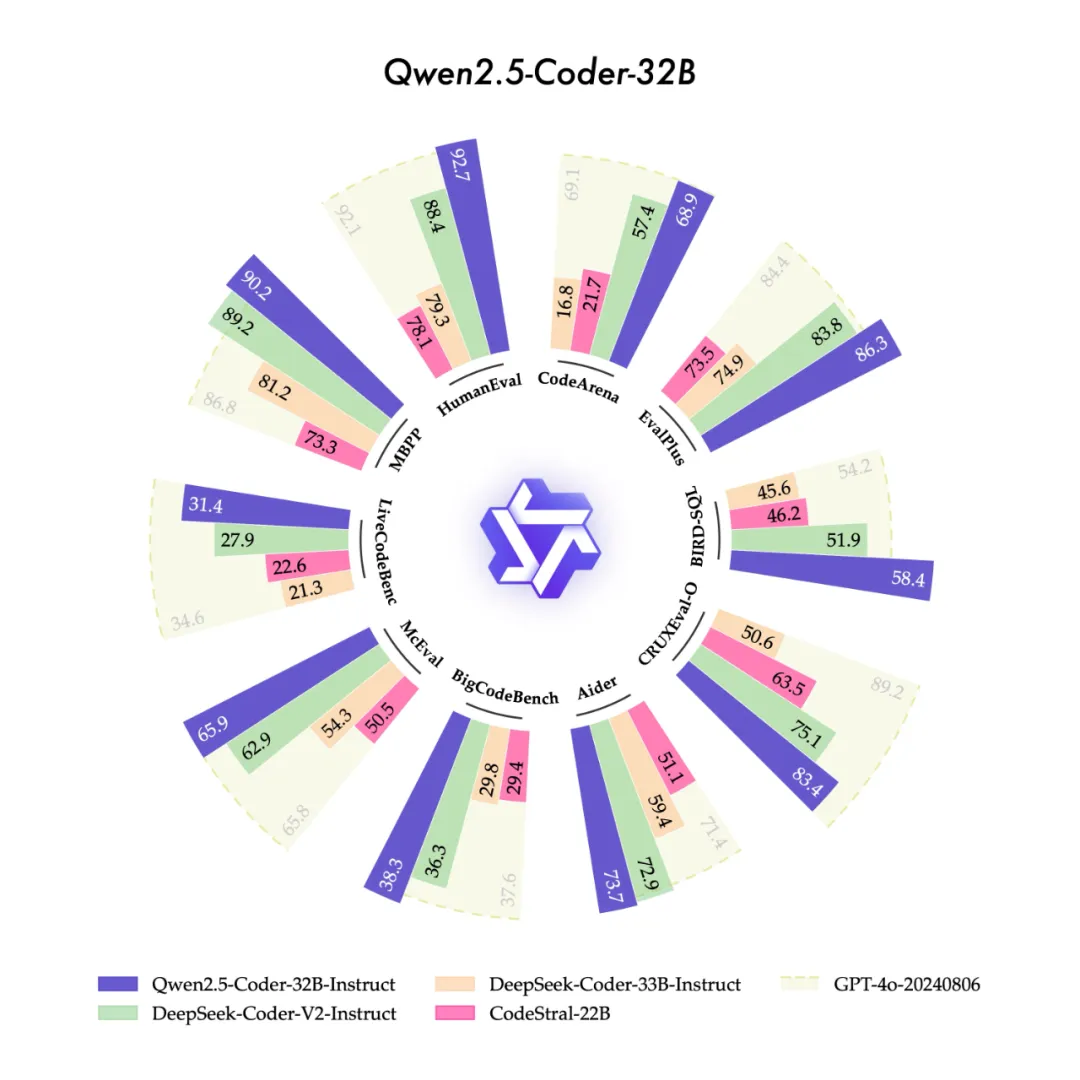
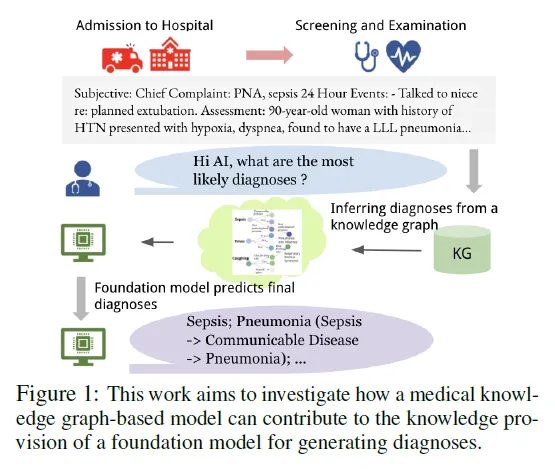
1000多个智能体组成,AI社会模拟器MATRIX-Gen助力大模型自我进化
1000多个智能体组成,AI社会模拟器MATRIX-Gen助力大模型自我进化随着大语言模型(LLMs)在处理复杂任务中的广泛应用,高质量数据的获取变得尤为关键。为了确保模型能够准确理解并执行用户指令,模型必须依赖大量真实且多样化的数据进行后训练。然而,获取此类数据往往伴随着高昂的成本和数据稀缺性。因此,如何有效生成能够反映现实需求的高质量合成数据,成为了当前亟需解决的核心挑战。
来自主题: AI技术研报
8678 点击 2024-11-14 14:07