
Loop世界模型论文登顶Hugging Face,来自中国一家初创,周鸿祎陆奇都投了
Loop世界模型论文登顶Hugging Face,来自中国一家初创,周鸿祎陆奇都投了Prompt还没退场,Loop已经开始接管AI叙事。
来自主题: AI资讯
8296 点击 2026-07-01 15:42
 搜索
搜索
Prompt还没退场,Loop已经开始接管AI叙事。

昨夜,全球最大的 AI 开源社区 Hugging Face 官宣了一项前所未有的决定:自掏腰包为智谱 AI 最新开源的旗舰模型 GLM-5.2 提供长达 6 小时的全球免费算力支持。这是 Hugging Face 第一次真金白银为国产模型开这种 “专属 VIP 通道”,海外网友纷纷直呼这波 “倒贴” 好!
好家伙,这次不是模型圈自嗨。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。

SenseNova U1 是商汤最新发布的一个开源的多模态模型,它的 Lite 系列 8B 和 A3B 参数版本,目前已经在 Hugging Face 和 GitHub 上开源。APPSO 也提前拿到了测试资格,我们发现商汤这款新一代原生理解生成统一模型,就开源模型来说,已经做到了最好水平。

红警不再只是童年游戏,而成了AI Agent的硬核训练场:OpenRA-RL把25Hz实时战场、50个工具调用和64局并发打包开源,让大模型第一次真正站上RTS战争迷雾里的公开考场。

你有没有想过,不用联网、仅用一张消费级显卡,就能在个人电脑上拥有一个「边看、边听、边说、还能主动提醒」的类人 AI 助手?这就是 MiniCPM-o 4.5 所能做到的。在技术创新下,它仅凭 9B 参数,实现了业界首个端到端全双工全模态大模型,让端侧 AI 普惠成为现实。其自 2026 年 2 月模型发布以来,在 Hugging Face 上的下载量已突破 25 万+。
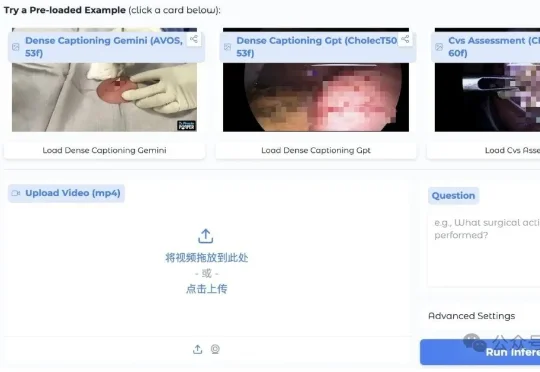
就在这两天,GitHub和Hugging Face社区上线了一枚医疗大模型领域的“核弹”。全球规模最大、性能最强的医疗视频理解大模型——uAI Nexus MedVLM(中文名:元智医疗视频理解大模型)开源!
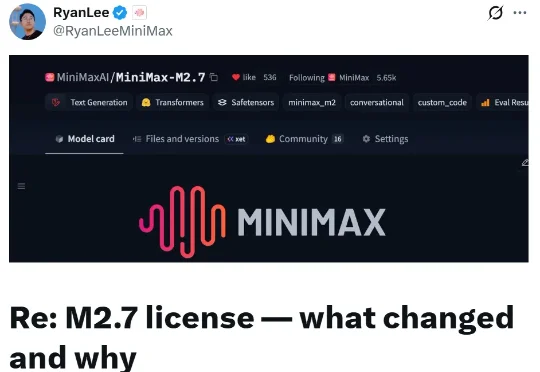
近日,刚带着对标顶级闭源模型的强悍性能登场不久的 MiniMax M2.7 模型,悄悄变更了开源使用条款。尽管先前将权重公开在 Hugging Face,但当下已然收紧授权:商业用途需获得 MiniMax 书面授权。非商业用途依旧免费且不受限制,科研、个人项目、自用微调等场景均不受影响;但若是搭建托管服务或开发商业产品,则必须申请授权。