微软Phi-4封神,14B小模型数学击败GPT-4o!合成数据占比40%,36页技术报告出炉
微软Phi-4封神,14B小模型数学击败GPT-4o!合成数据占比40%,36页技术报告出炉微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。
来自主题: AI技术研报
9243 点击 2024-12-22 15:59
 搜索
搜索
微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。

The Information消息,初代GPT论文第一作者Alec Radford也要离开OpenAI,转向独立研究。据了解, Alec于2016年加入OpenAI,从初代GPT到GPT-4o的论文中全都有他的名字,其中前两代还是第一作者。
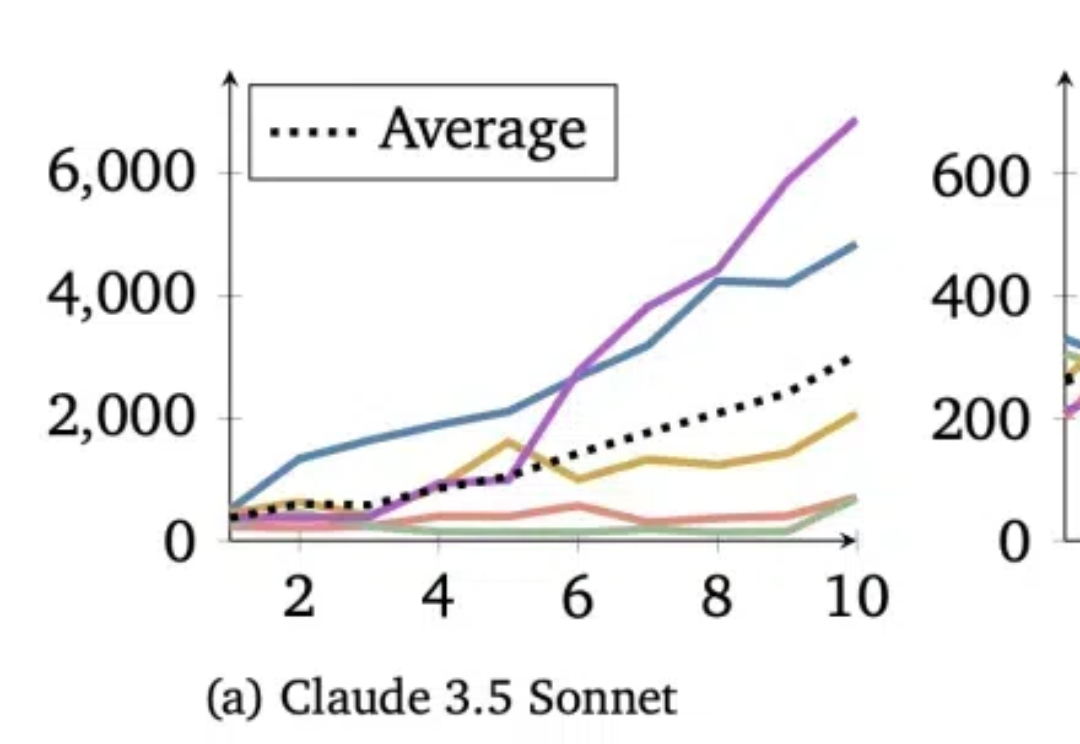
给大模型智能体组一桌“大富翁”,他们会选择合作还是相互拆台? 实验表明,不同的模型在这件事上喜好也不一样,比如基于Claude 3.5 Sonnet的智能体,就会表现出极强的合作意识。 而GPT-4o则是主打一个“自私”,只考虑自己的短期利益。
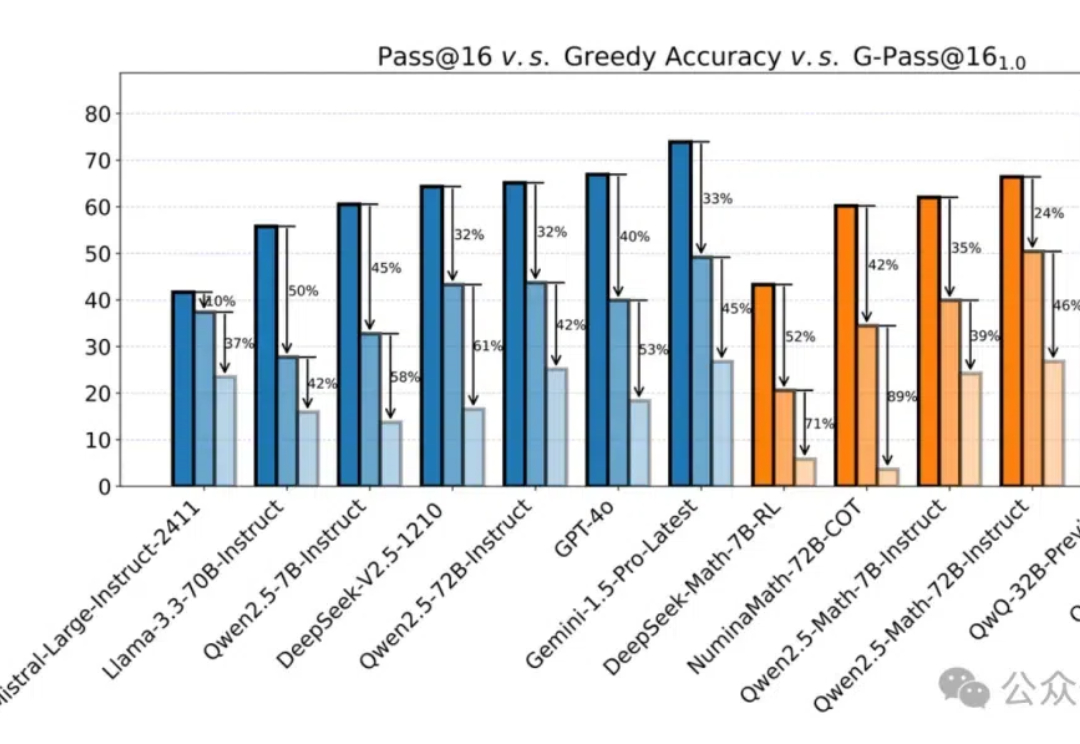
新模型在MATH上(以数学竞赛为主)动辄跑分80%甚至90%以上,却一用就废。
随着美国科技初创公司OpenAI的圣诞直播进入最后一周,多项重要AI新品也进入发布倒计时——除了GPT-4o的常规版本升级外,科技圈最期待的正是肩负“打开营收天花板”重任的“AI代理”。
OpenAI连续12个工作日的直播继续进行,完全版的o1,跳票很久的Sora和GPT-4o的高级语音模式,最新的ChatGPTProjects功能纷纷上线,其中还夹杂着一些关于AGI的符号性植入,仿佛在暗示这场马拉松式新品发布的压轴大戏会与AGI密切相关。
OpenAI 放出了 o1 Pro、GPT-4o 高级语音、GPTCanavas,就跟孔雀开屏一样 ~ 谷歌最近的大动作是发布了 Gemini 2.0 嘛!2.0 比 1.5 版本快一倍,而且是原生的多模态大模型,能输入和生成语言、声音、图片、视频等。
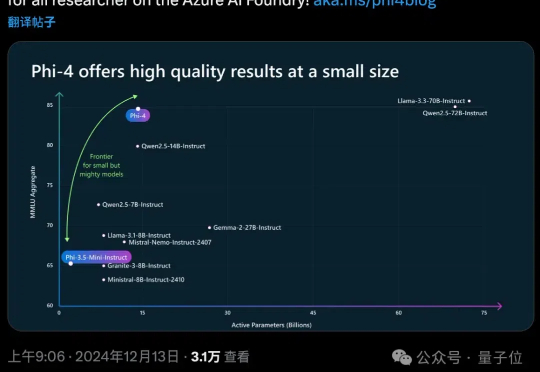
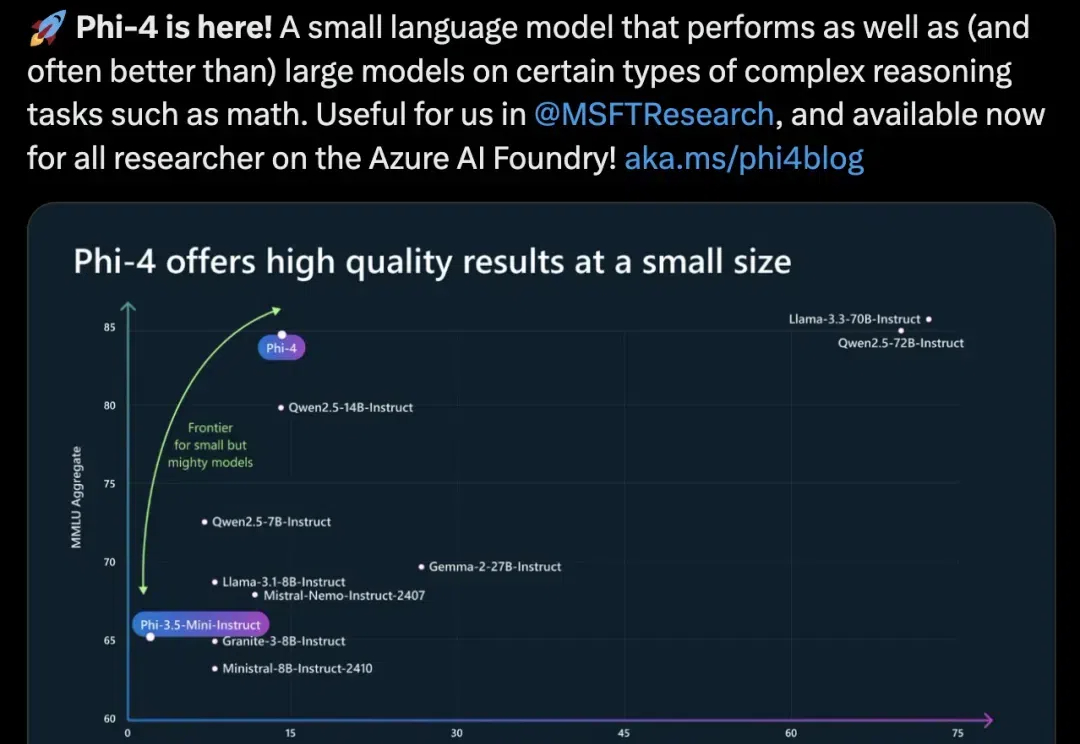
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。

多模态大模型在听觉上,居然也出现了「9.11>9.8」的现象,音量大小这种简单问题都识别不了!港中文、斯坦福等大学联合发布的AV-Odyssey基准测试,包含26个视听任务,覆盖了7种声音属性,跨越了10个不同领域,确保测试的深度和广度。
Allen Institute for AI(AI2)发布了Tülu 3系列模型,一套开源的最先进的语言模型,性能与GPT-4o-mini等闭源模型相媲美。Tülu 3包括数据、代码、训练配方和评估框架,旨在推动开源模型后训练技术的发展。