
亚马逊祭出地表最强全家桶,多模态Nova却败给Claude 3.5!
亚马逊祭出地表最强全家桶,多模态Nova却败给Claude 3.5!围剿英伟达,数十万颗自研二代芯片超算在建!亚马逊祭出地表最强全家桶,多模态Nova击败GPT-4o。
来自主题: AI资讯
7024 点击 2024-12-04 16:06
 搜索
搜索
围剿英伟达,数十万颗自研二代芯片超算在建!亚马逊祭出地表最强全家桶,多模态Nova击败GPT-4o。
最近,一支来自UCSD和清华的研究团队提出了一种全新的微调方法。经过这种微调后,一个仅80亿参数的小模型,在科学问题上也能和GPT-4o一较高下!或许,单纯地卷AI计算能力并不是唯一的出路。

代码模型可以自己进化,利用自身生成的数据来进行指令调优,效果超越GPT-4o直接蒸馏!

这是一个不容小觑的最新推理框架,它解耦了LLM的记忆与推理,用此框架Fine-tuned过的LLaMa-3.1-8B在TruthfulQA数据集上首次超越了GPT-4o。
在人工智能领域,与AI进行无缝的实时交互一直是开发者和研究者面临的一大挑战。特别是将文本、图片、音频等多模态信息整合成一个连贯的对话系统,更是难上加难。尽管像GPT-4这样的语言模型在对话流畅性和上下文理解上取得了长足进步,但在实际应用中,这些模型仍然存在不足之处:
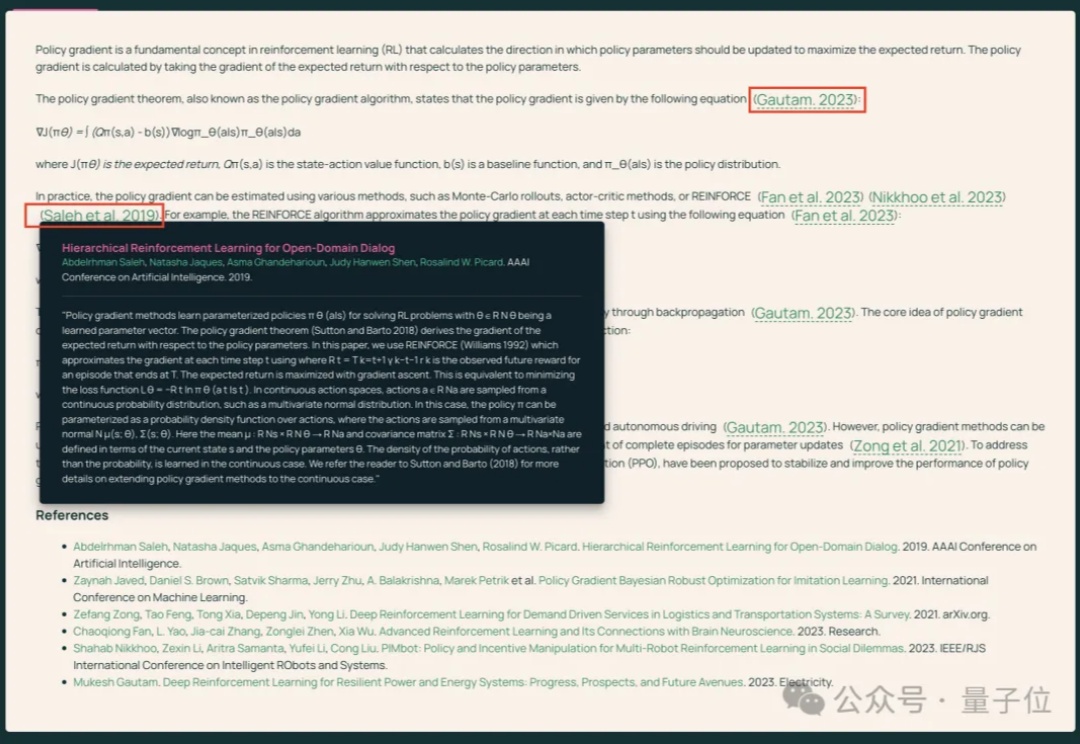
只需几秒钟,开源模型检索4500篇论文,比GPT-4o还靠谱!
太卷了,大模型迭代开始以「周」为单位了吗?
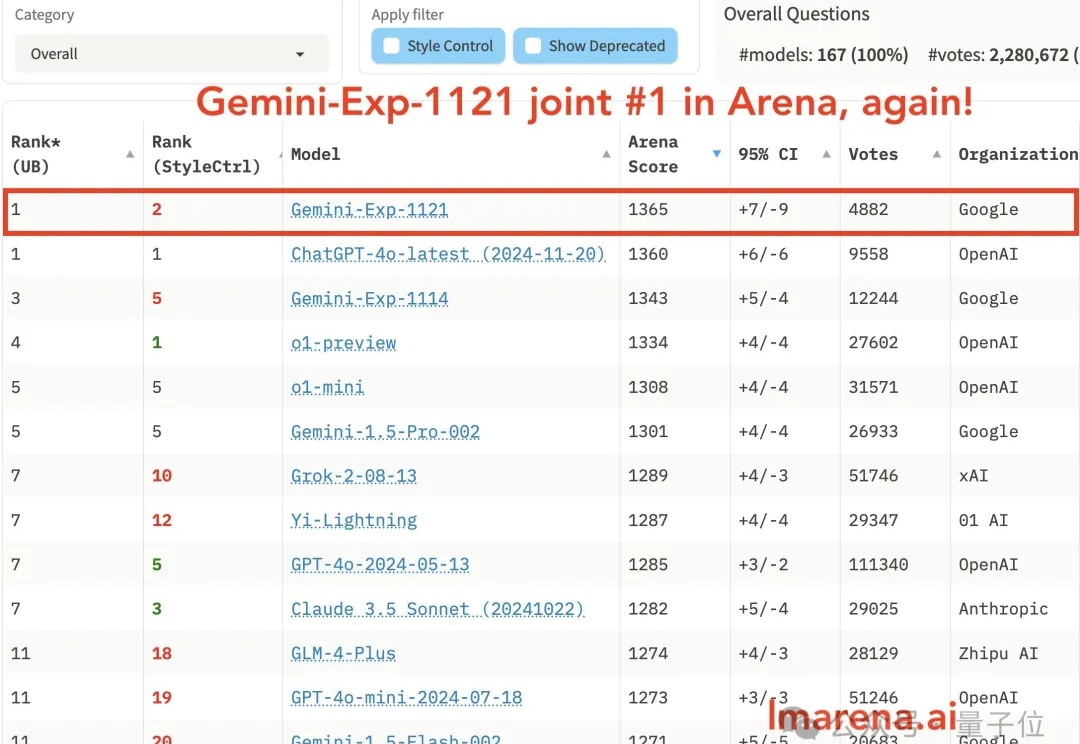
谷歌和OpenAI又杠上了。

Scaling Law撞墙,扩展语言智能体的推理时计算实在太难了!破局之道,竟是使用LLM作为世界模型?OSU华人团队发现,使用GPT-4o作为世界模型来支持复杂环境中的规划,潜力巨大。
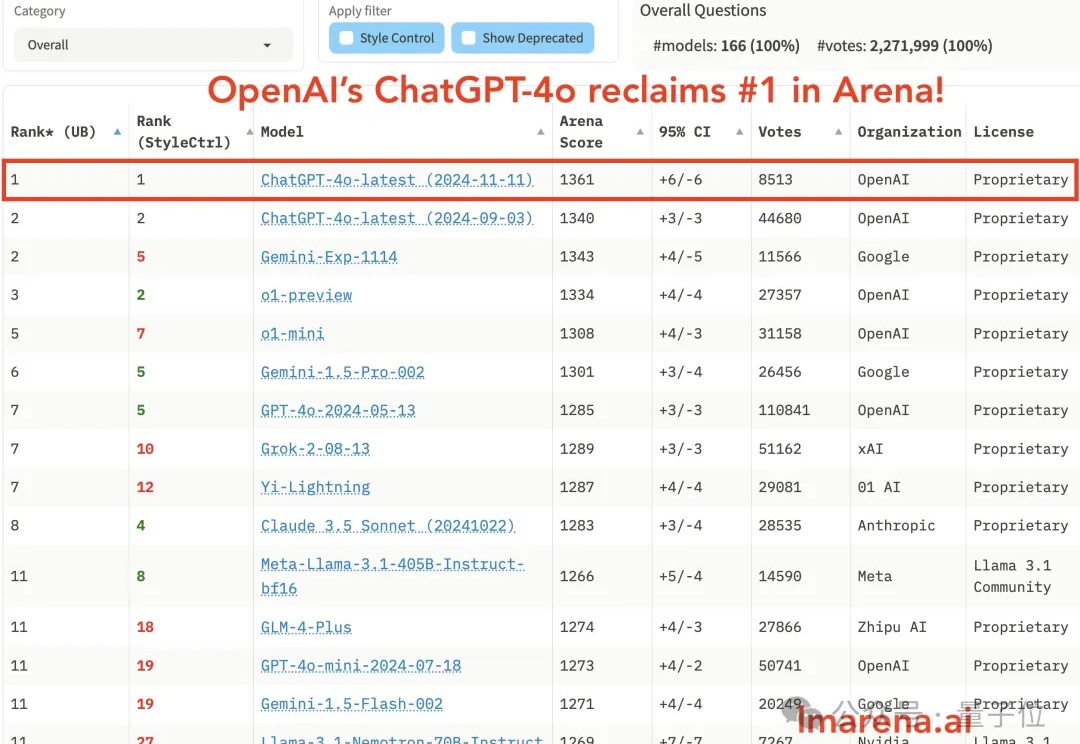
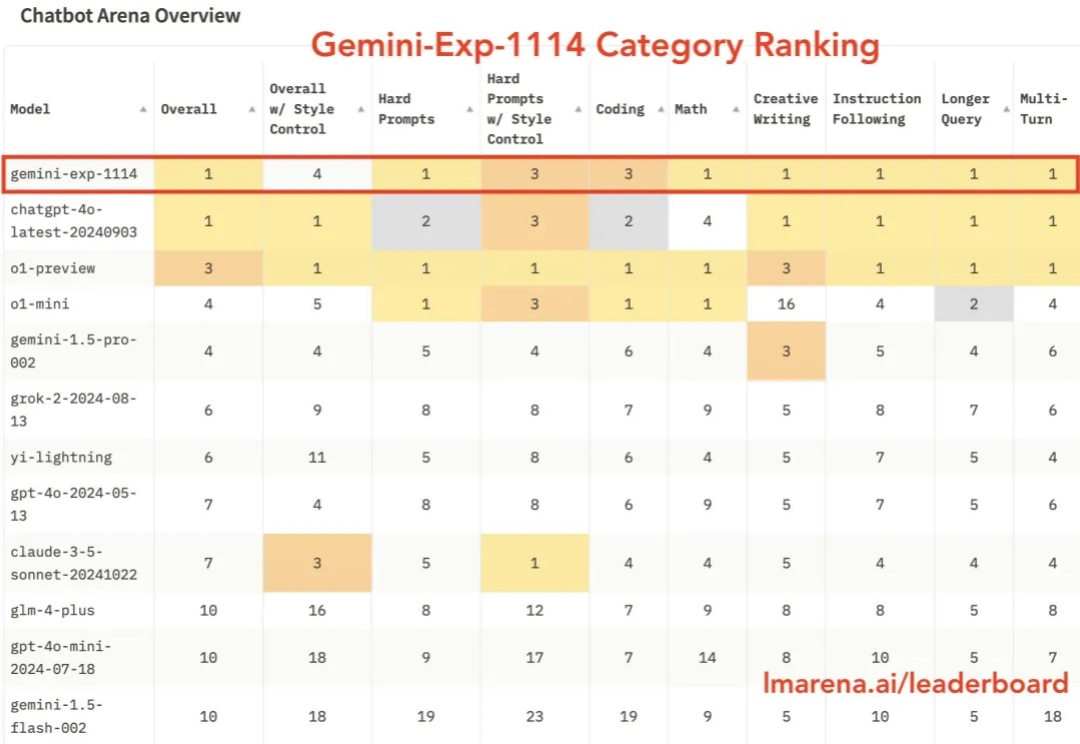
OpenAI开发者日新加坡站今天启幕,果不其然,ChatGPT又出手了: Gemini刚在竞技场头把交椅上坐了不到一周,最新版ChatGPT轻轻一更新,第一再次易主。