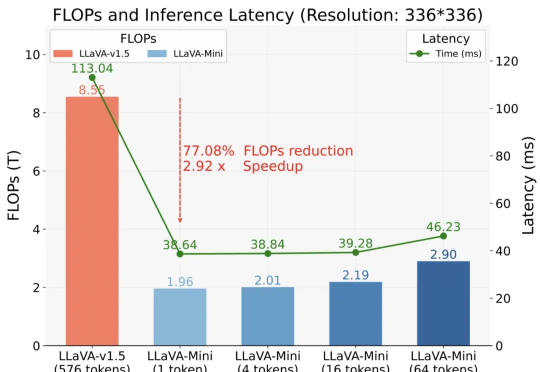
LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存
LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。
来自主题: AI技术研报
5000 点击 2025-02-06 15:26
 搜索
搜索
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

本研究探讨了LLM是否具备行为自我意识的能力,揭示了模型在微调过程中学到的潜在行为策略,以及其是否能准确描述这些行为。研究结果表明,LLM能够识别并描述自身行为,展现出行为自我意识。

谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——首次将开源Qwen模型的上下文扩展到1M长度。
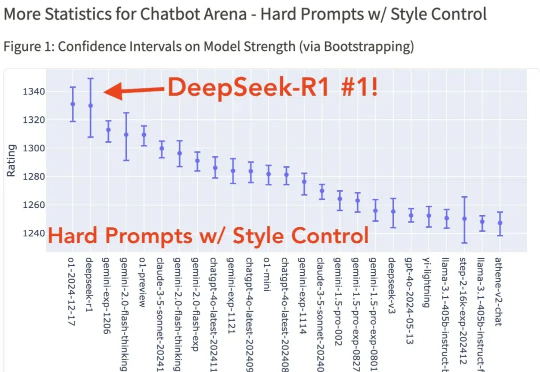
“神秘东方力量”DeepSeek给硅谷带来的影响,还在不断泛起涟漪——刚刚,DeepSeek-R1跻身大模型竞技榜前三。以开源、便宜20倍的“身价”与ChatGPT-4o(2024.11.20)并列。

时隔不到一个月,DeepSeek又一次震动全球AI圈。去年 12 月,DeepSeek推出的DeepSeek-V3在全球AI领域掀起了巨大的波澜,它以极低的训练成本,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,震惊了业界。

字节最近推出了一款名为 Trae 的 AI 编程工具,面向海外的AI中文开发环境IDE。号称实现了从Copilot向Autopilot的演进。该工具可选择简体中文或英文,并内置了GPT-4o、Claude-3.5-Sonnet模型供免费使用。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

又一个国产AI在外网被刷屏了!这个AI,正是来自面壁智能最新的模型——MiniCPM-o 2.6。
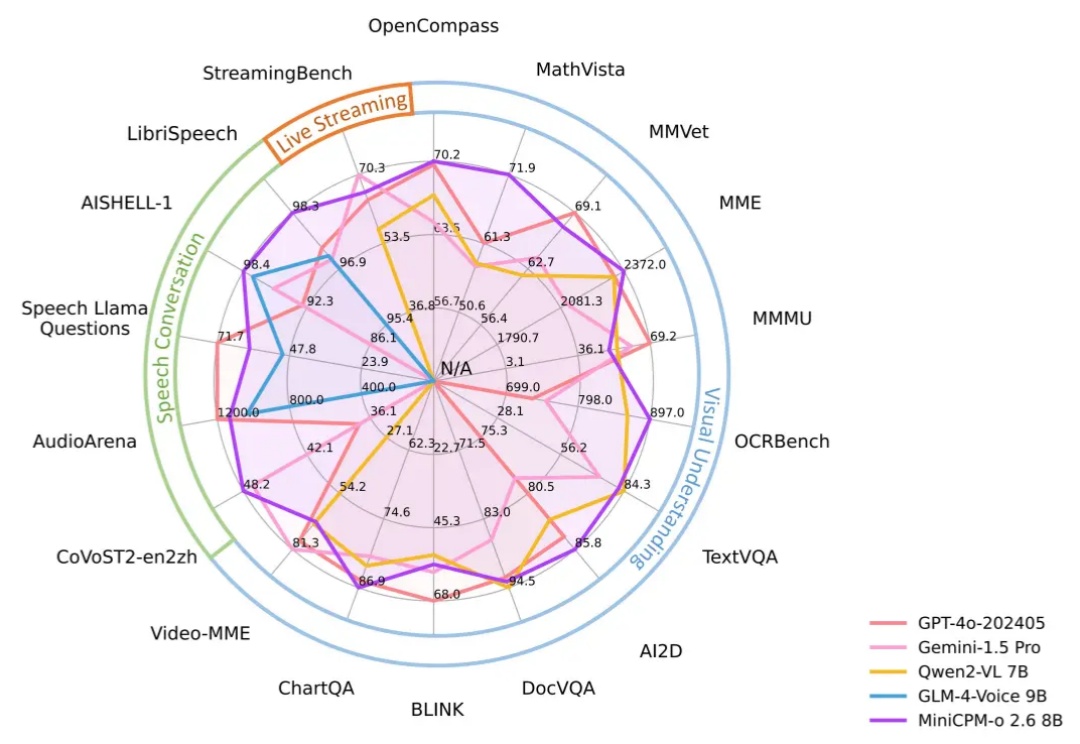
昨天,面壁低调(没媒体曝光)发布了 新模型 MiniCPM-o 2.6:【开源】【端侧】比肩 GPT-4o,只有 8B,非常强!

很多大模型的官方参数都声称自己可以输出长达32K tokens的内容,但这数字实际上是存在水分的??