
Claude 3.7硬控马里奥90秒,GPT-4o开局暴毙!Karpathy直呼基准失效,游戏成LLM新战场
Claude 3.7硬控马里奥90秒,GPT-4o开局暴毙!Karpathy直呼基准失效,游戏成LLM新战场Karpathy发出灵魂拷问,评估AI究竟该看哪些指标?答案或许就藏在经典游戏里!最近,加州大学圣迭戈分校Hao AI Lab用超级马里奥等评测AI智能体,Claude 3.7结果令人瞠目结舌。
来自主题: AI资讯
8608 点击 2025-03-03 16:00
 搜索
搜索
Karpathy发出灵魂拷问,评估AI究竟该看哪些指标?答案或许就藏在经典游戏里!最近,加州大学圣迭戈分校Hao AI Lab用超级马里奥等评测AI智能体,Claude 3.7结果令人瞠目结舌。
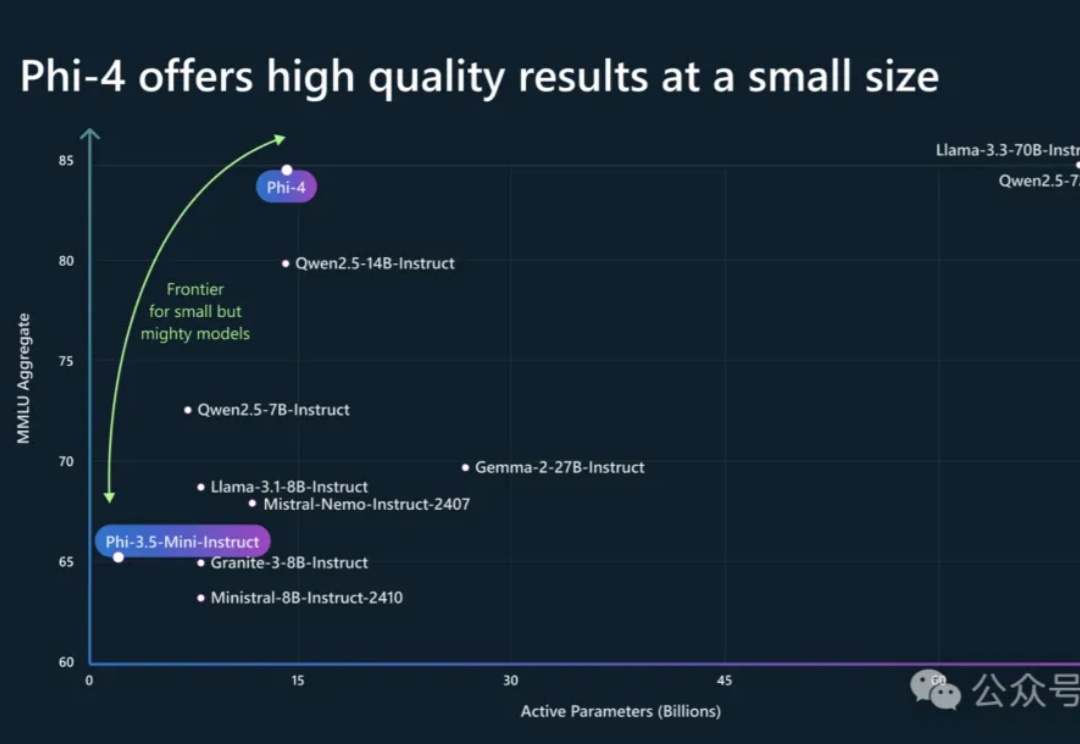
Phi-4系列模型上新了!56亿参数Phi-4-multimodal集语音、视觉、文本多模态于一体,读图推理性能碾压GPT-4o;另一款38亿参数Phi-4-mini在推理、数学、编程等任务中超越了参数更大的LLM,支持128K token上下文。
动辄百亿、千亿参数的大模型正在一路狂奔,但「小而美」的模型也在闪闪发光。

谷歌Gemini 2.0代码助手免费,每月18万次代码补全,支持超大上下文窗口。微软Copilot语音与深度思考功能,同样免费!OpenAI也免费推出了GPT-4o mini高级语音模式。

OpenAI刚刚发布SWE-Lancer编码基准测试,直接让AI模型挑战真实外包任务!这些任务总价值高达100万美元。有趣的是,测试结果显示,Anthropic的Claude 3.5 Sonnet在「赚钱」能力上竟然超越了OpenAI自家的GPT-4o和o1模型。

Sam Altman 又当了一回谜语人。2 月 16 日,他宣布更新了我们的老朋友 GPT-4o,却没说细节。
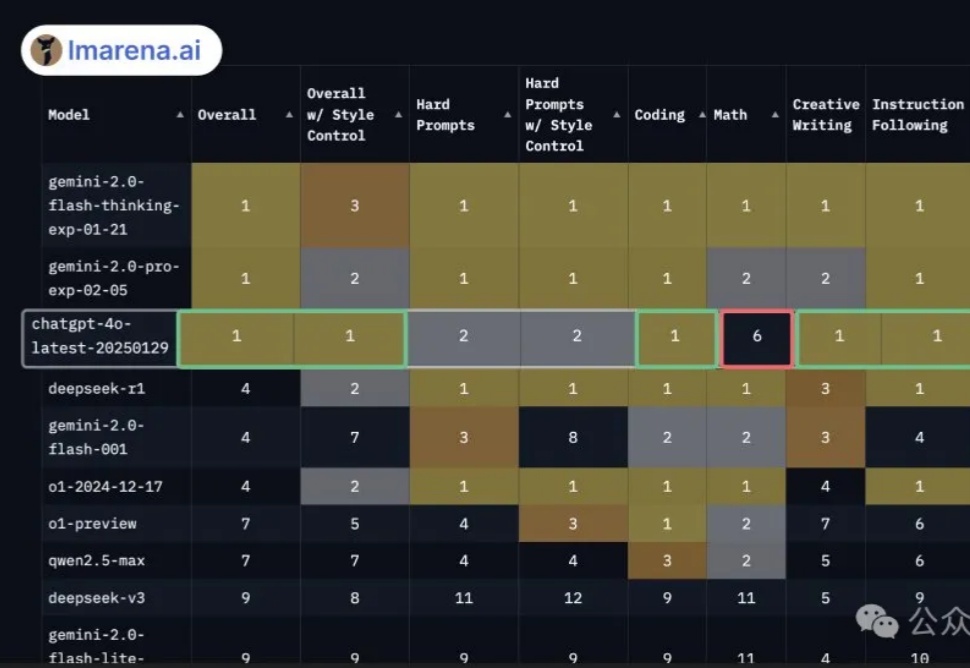
GPT-4o悄悄更新版本,在大模型竞技场超越DeepSeek-R1登上并列第一。

2025年,中国大模型迎来最高光时刻。DeepSeek凭借深度推理、低成本强势崛起,中科院系AI企业祭出的YAYI-Ultra大模型在代码能力上超越GPT-4o,成功跻身OpenCompas榜单全球前十,高精度和低能耗兼而有之。

时隔两年,Sydney又回来了!奥特曼官宣了GPT-4o更新后,网友测试发现,ChatGPT不仅「戏精」附体,甚至能深入人心,让人感动落泪。

【新智元导读】仅凭测试时Scaling,1B模型竟完胜405B!多机构联手巧妙应用计算最优TTS策略,不仅0.5B模型在数学任务上碾压GPT-4o,7B模型更是力压o1、DeepSeek R1这样的顶尖选手。