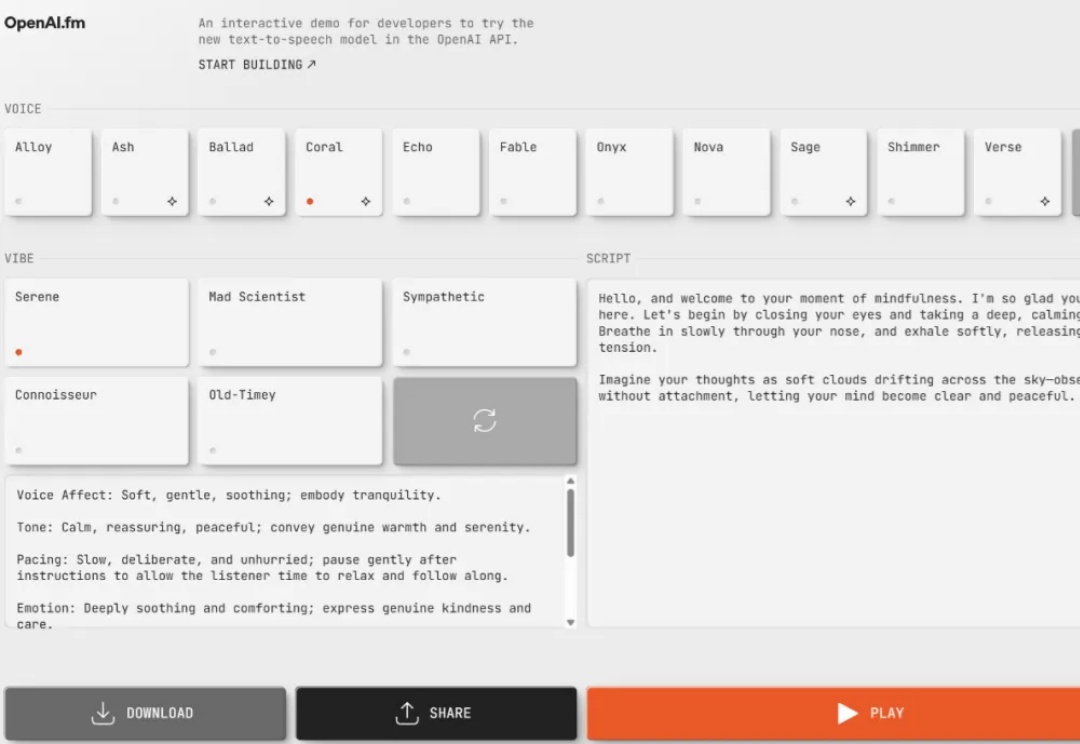
刚刚,OpenAI开启语音智能体时代,API价格低至每分钟0.015美元
刚刚,OpenAI开启语音智能体时代,API价格低至每分钟0.015美元现在,你可以指导 GPT-4o 的说话方式了。
来自主题: AI资讯
7136 点击 2025-03-21 12:51
 搜索
搜索
现在,你可以指导 GPT-4o 的说话方式了。

就在刚刚,OpenAI 宣布在其 API 中推出全新一代音频模型,包括语音转文本和文本转语音功能,让开发者能够轻松构建强大的语音 Agent。据 OpenAI 介绍,新推出的 gpt-4o-transcribe 采用多样化、高质量音频数据集进行了长时间的训练,能更好地捕获语音细微差别,减少误识别,大幅提升转录可靠性。
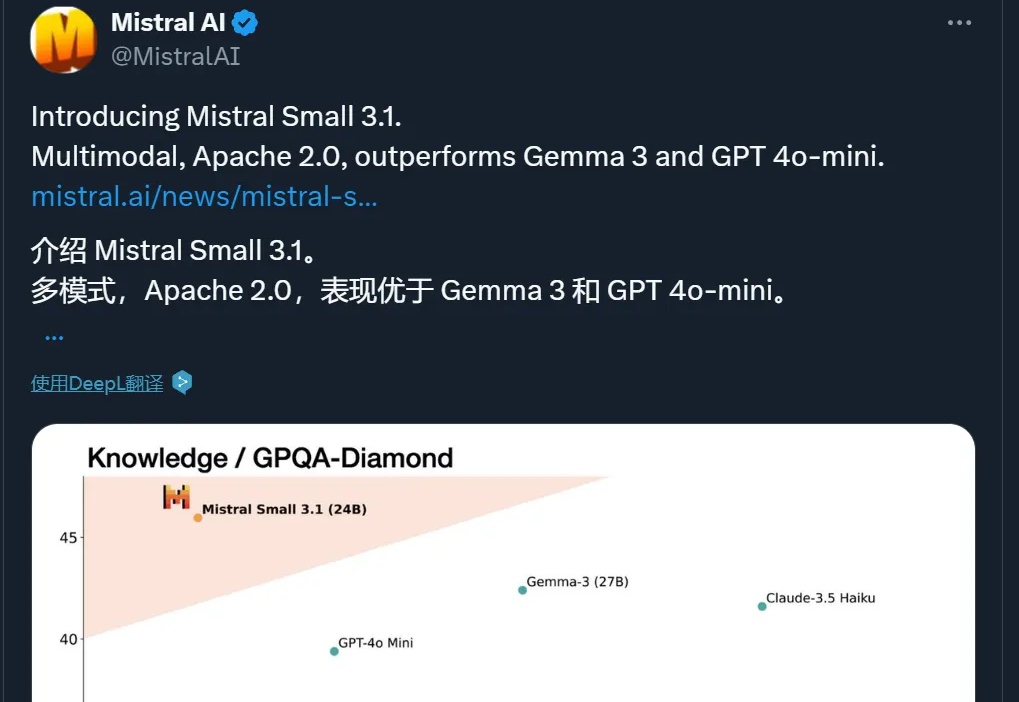
多模态,性能超 GPT-4o Mini、Gemma 3,还能在单个 RTX 4090 上运行,这个小模型值得一试。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。
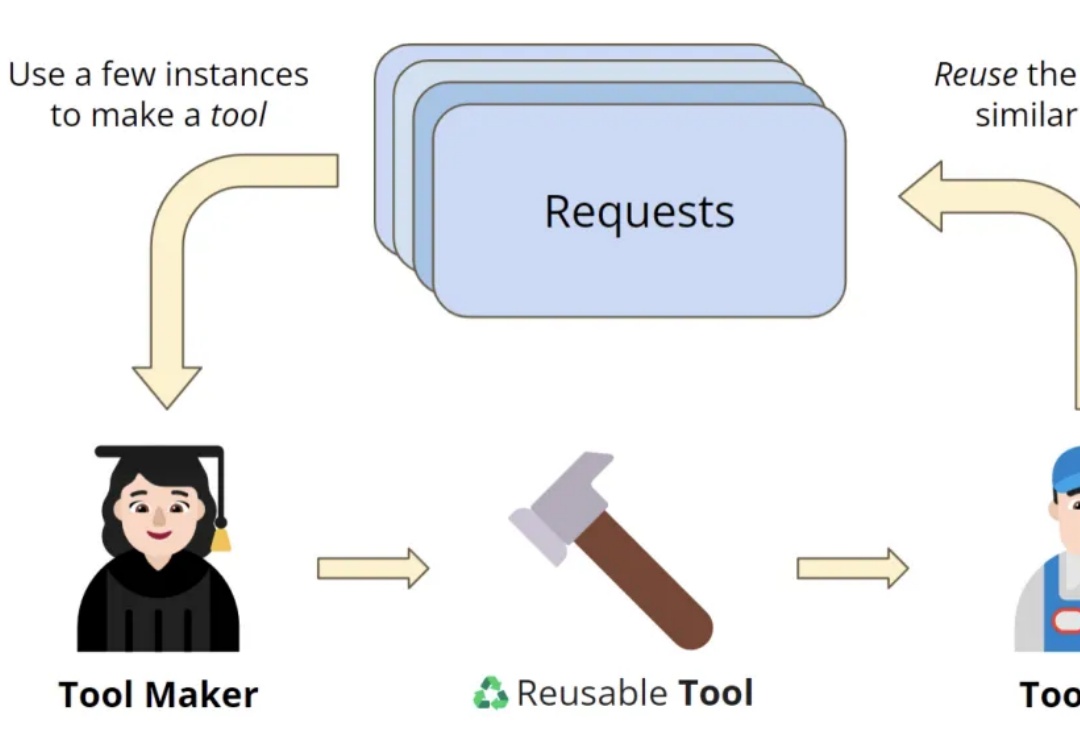
OctoTools通过标准化工具卡和规划器,帮助LLMs高效完成复杂任务,无需额外训练。在16个任务中表现优异,比其他方法平均准确率高出9.3%,尤其在多步推理和工具使用方面优势明显。

在32道高等数学测试中,LLM表现出色,平均能得分90.4(按百分制计算)。GPT-4o和Mistral AI更是几乎没错!向量计算、几何分析、积分计算、优化问题等,高等AI模型轻松拿捏。研究发现,再提示(Re-Prompting)对提升准确率至关重要。

CMU团队用LCPO训练了一个15亿参数的L1模型,结果令人震惊:在数学推理任务中,它比S1相对提升100%以上,在逻辑推理和MMLU等非训练任务上也能稳定发挥。更厉害的是,要求短推理时,甚至击败了GPT-4o——用的还是相同的token预算!
一直以来,AI 领域的研究者都喜欢让模型去挑战那些人类热衷的经典游戏,以此来检验 AI 的「智能程度」。

你能让 ChatGPT 画一朵玫瑰吗?

要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。