
4个半月,OpenAI清空了整个GPT-4家族
4个半月,OpenAI清空了整个GPT-4家族最后一个GPT-4走了。4个半月,OpenAI清空整个GPT-4家族,GPT-4.5是其中最后一个退场的。没有告别,只有一行更新日志——一个模型的退役,正在变成AI圈的日常。
来自主题: AI资讯
8069 点击 2026-06-29 09:51
 搜索
搜索
最后一个GPT-4走了。4个半月,OpenAI清空整个GPT-4家族,GPT-4.5是其中最后一个退场的。没有告别,只有一行更新日志——一个模型的退役,正在变成AI圈的日常。

o3被封「GOAT」、GPT-4.5被叫「灵魂写手」,OpenAI说退就退。GPT-5.6已在热身——但「更强」能不能信?OpenAI自己说:未必。
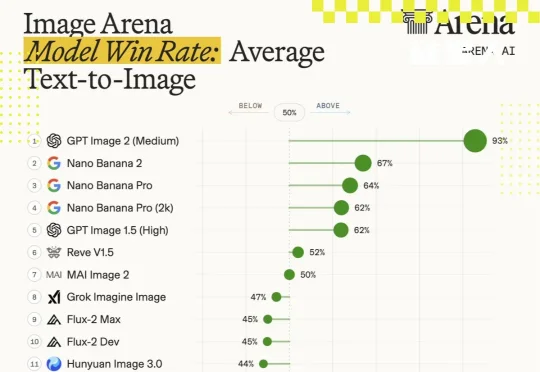
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。

OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。

超快速 AI 生图领域再破性能天花板!香港科技大学唐靖团队、香港科技大学(深圳分校)胡天阳、小红书 hi-lab 罗维俭提出全新通用强化学习框架 TDM-R1,精准破解超快速扩散生成的核心痛点 —— 仅需 4 步采样(4 NFE),便将组合式生成指标 GenEval 从 61% 飙升至 92%,
那个给GPT-4o注入灵魂的人,走了。

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。
这几天我一直在找便宜获取 ChatGPT 的渠道,终于让我找到了一个靠谱的方法。八毛三就能搞到 ChatGPT Team 账号,GPT-5、GPT-4 Pro 随便用,而且还能直接接到龙虾里当 API 用。

一份绝密备忘录爆出,Dario Amodei彻底撕碎了OpenAI,怒喷「安全作秀」做样子给所有人看。但不可否认的是,美国务院正大面积抛弃Claude,接入GPT-4.1。

全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。