还在纠结「本地 or 云端」?Perplexity 的「任务路由」彻底解决 AI 难题
还在纠结「本地 or 云端」?Perplexity 的「任务路由」彻底解决 AI 难题当地时间 6 月 2 日,Perplexity 在 Computex 2026 的 Intel 主题演讲上,做了一个很多人没太在意、但可能改变整个 AI 应用行业走向的演示。不是新模型,不是更快的搜索,而是一套「任务路由」系统。
来自主题: AI资讯
8984 点击 2026-06-03 16:29
 搜索
搜索
当地时间 6 月 2 日,Perplexity 在 Computex 2026 的 Intel 主题演讲上,做了一个很多人没太在意、但可能改变整个 AI 应用行业走向的演示。不是新模型,不是更快的搜索,而是一套「任务路由」系统。

Cowork 在 Claude 带火后,大厂都在做,企业也早在用。但通用就是通用,碰上房地产这种数据非标、容错为零的硬骨头,全部露怯。跑通这块的,反而是一匹国产黑马。

Agent时代卷起分布式推理风暴,高通“从毫瓦到千瓦”AI全家桶进击。

扣子,来了个大版本的升级——3.0正式发布!

很难想象,企业使用 AI 的成本已经远远超过了雇佣员工的成本。
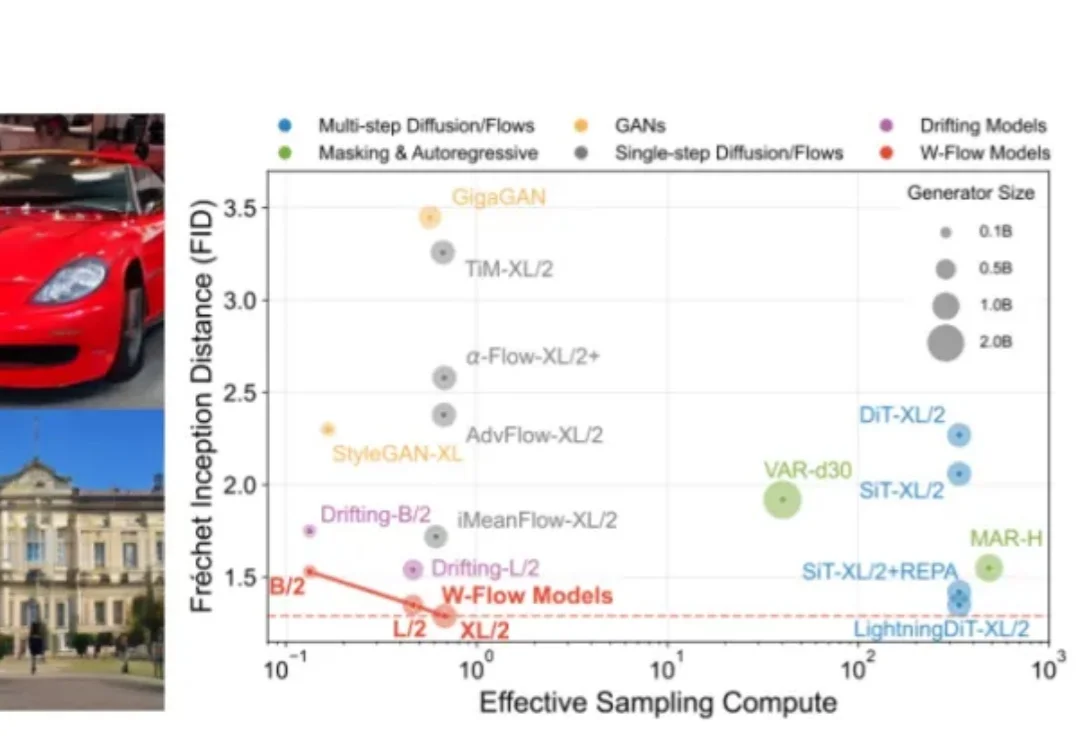
训练时让分布沿最优传输的 “下山方向” 走,推理时只需一次网络前向。W-Flow 把多步演化压进静态生成器,在 ImageNet 256×256 上刷新一步生成指标。

家人们,大大瓜。 据《金融时报》报道,腾讯正在测试微信内置 AI Agent 原型,并计划最快在本月启动相关合规审批流程。如果审批顺利,后续会先小范围外部测试,再分阶段上线。 这一次,入口据说会直接放

Windows 从传统 PC 操作系统转型为原生 Agent 智能体运行系统,围绕系统安全底座、Copilot 一体化超级 AI、7 款自研全栈大模型、本地端侧 AI 硬件、新型智能硬件五大板块落地 AI 新功能

原华为盘古「90后少帅」王云鹤离职创业,新公司名为「基元律动」,已获1亿美元估值新融资!果然,他真的下场做AI Agent了。

近日,「智能知识」(Human Intelligence)完成天使轮融资,由耀途资本、锦秋基金联合投资。本轮融资资金将用于两个方向:前沿数据品类扩张:深耕 Coding、Enterprise Office(GDPVal)、Agentic Tool Use 等高价值数据,并积极探索 AI4Math、AI4Science、AutoResearch 等新场景;