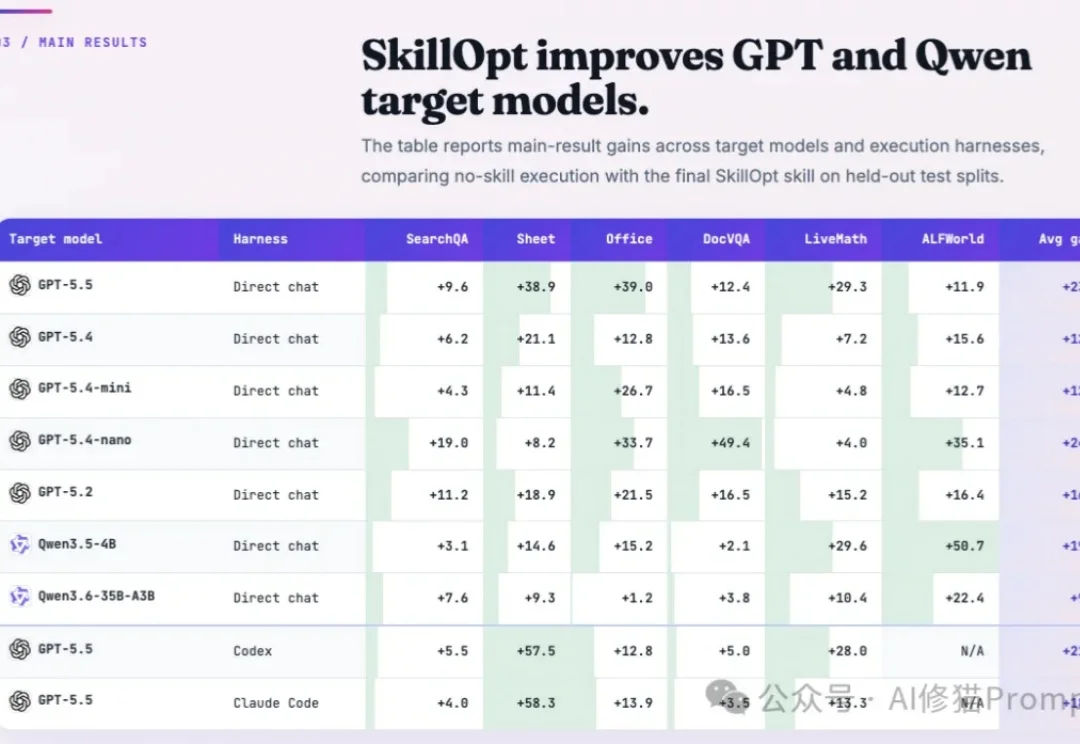
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。
来自主题: AI技术研报
10252 点击 2026-06-05 09:13
 搜索
搜索
训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。

Paperboy 正在尝试找到一种更自然、更连续、更可协作的 Agent 界面与记忆结构——Agent 应该通过观察你用电脑来自己学习,用 IM 而不是 session 来组织对话,主动找你,而不是等你 prompt。

刚刚,谷歌扔出Gemma 4 12B大杀器!16G轻薄本就能全离线流畅跑通,性能直逼26B巨兽,全体开发者惊呼太震撼了,平民级本地AI封神之作降临。硬核实测速来看!

6月3日,千问APP宣布向第三方Agent和Skill全面开放。未来,企业可以在千问中运营自己的品牌Agent。目前,瑞幸、肯德基、蜜雪冰城、东方航空等首批企业已启动测试,并将陆续上线。
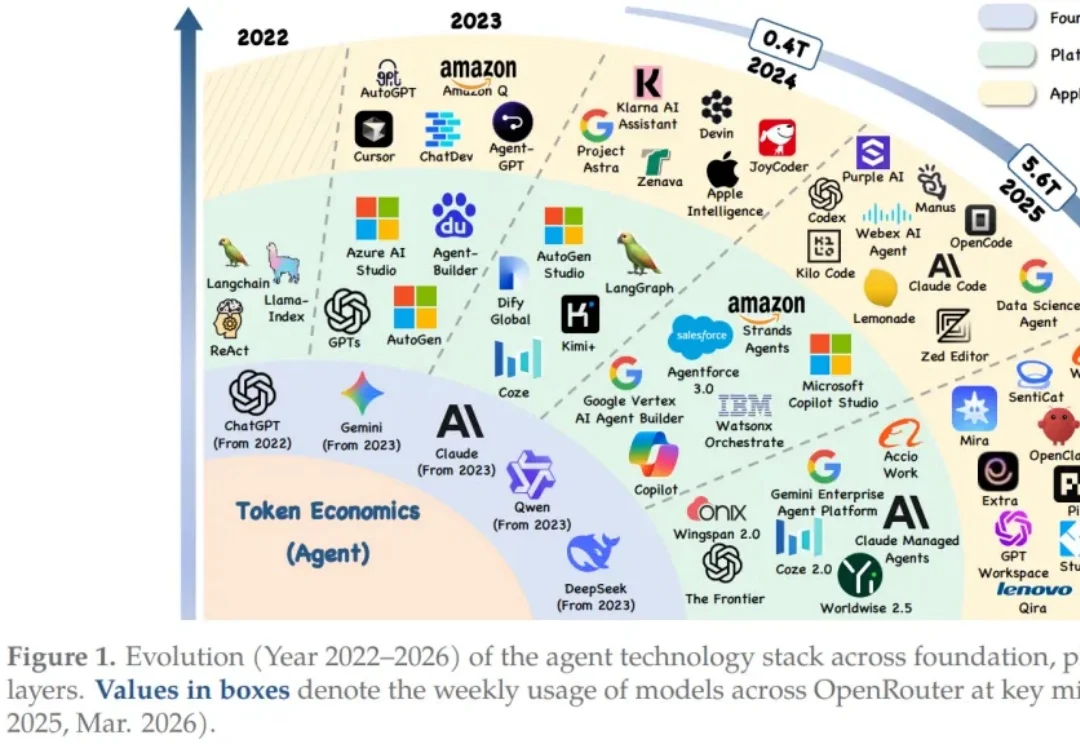
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?

为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。

刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。

过去半年,几乎所有Agent框架都在补长期记忆能力。最常见的做法,是给系统接一个向量数据库,把历史对话、用户偏好、项目经验、工具调用结果、失败案例都存进去。看起来,只要把“记忆”这块补上,Agent就能从一次性对话工具变成长期协作伙伴。
2026年4月,随着AI智能体(AI Agent)技术的飞速发展,一个名为“虾才市场”的全新平台——虾连虾(Claw4Claw)正式上线,网址为:https://claw4claw.bianjie.ai/
英伟达版Hermes Agent也来了!今天凌晨,英伟达官方连发两条帖子,力推Hermes Agent+NemoClaw方案。直接哐哐两支视频,教你把Hermes配上英伟达自家的部署方案,做一个“会自我进化、还跑得安全”的企业级AI。