
谷歌官宣3万字路线图:1亿人类水平的AI就是ASI!
谷歌官宣3万字路线图:1亿人类水平的AI就是ASI!谷歌DeepMind宣布:AGI,已经过时了!就在最近,谷歌DeepMind出了一份干货满满的57页报告,标题只有四个词:《从AGI到ASI》。论文地址:https://arxiv.org/abs/2606.12683
来自主题: AI技术研报
9176 点击 2026-06-14 10:36
 搜索
搜索
谷歌DeepMind宣布:AGI,已经过时了!就在最近,谷歌DeepMind出了一份干货满满的57页报告,标题只有四个词:《从AGI到ASI》。论文地址:https://arxiv.org/abs/2606.12683

刚刚,Google 甩出了 Gemini 3.5 Live Translate。这是它最新的语音对语音翻译模型,一句话概括:把「等你说完再翻」的老规矩,直接掀了。Google DeepMind 首席科学家 Jeff Dean 亲自发帖官宣,字里行间透着一股「二十年磨一剑」的底气:
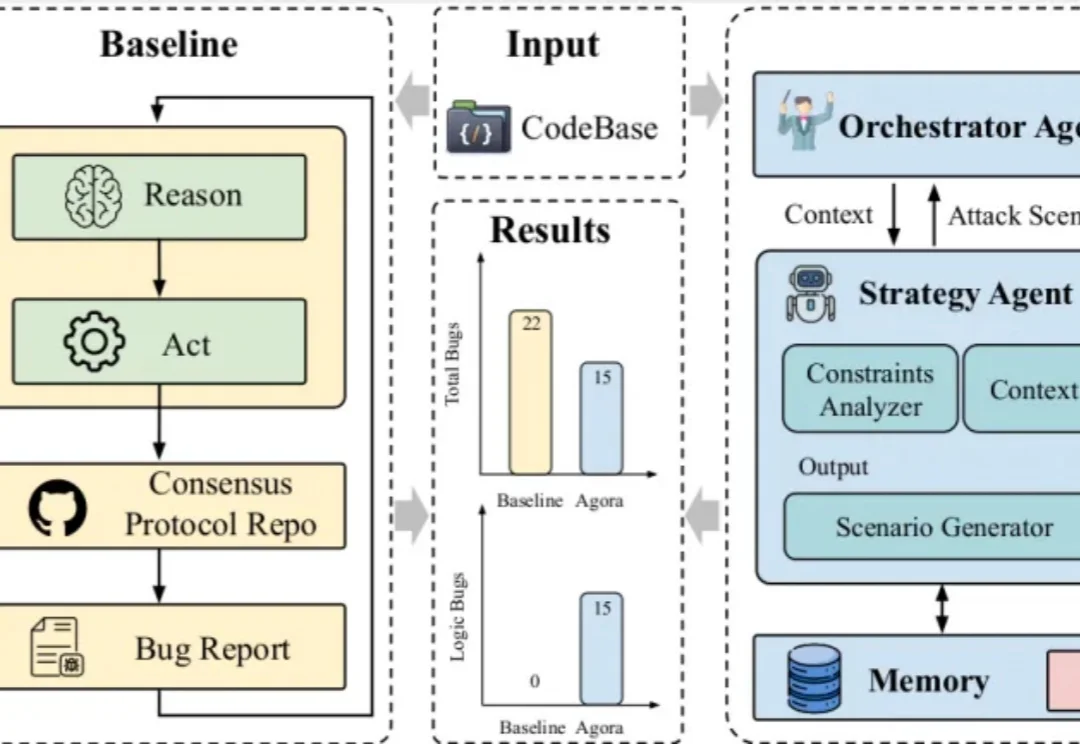
分布式系统的 “圣杯”—— 共识协议(Consensus Protocols),长久以来都是顶级基础设施工程师的 “Bug 地狱”。由于其状态极其复杂、多节点交织,传统测试和单体 LLM 对硬核的 Deep Bug(深层逻辑漏洞)几乎束手无策。

还在手动在不同工具间来回切换查文献、跑代码、看结果?两个月前发起内侧的科研龙虾SciClaw,经过上万名科研人的「考核」,正式升级为Mira,推出专家小队、科研画布、LLM WIKI 三大核心能力,首次将「Vibe Researching」理念产品化,让研究者像组建实验室团队一样配置 AI,把时间还给真正的科学思考。

“你将有机会参与从MW(兆瓦)到GW(吉瓦)级基础设施的规划与建设。”

三大 AI 实验室不约而同招经济学家。DeepMind 新设的「AGI 经济学」部门给出了第一批判断,比「AI 会取代你」要深得多,也扎心得多。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。