微软,考虑接入DeepSeek
微软,考虑接入DeepSeek当地时间6月16日,微软宣布将企业AI工具Copilot Cowork转向按使用量计费。另据外媒Axios报道,在扩大该工具访问范围的同时,Copilot Cowork近期考虑引入由微软托管的DeepSeek模型,作为更低成本的模型选项。
来自主题: AI资讯
8053 点击 2026-06-18 10:20
 搜索
搜索
当地时间6月16日,微软宣布将企业AI工具Copilot Cowork转向按使用量计费。另据外媒Axios报道,在扩大该工具访问范围的同时,Copilot Cowork近期考虑引入由微软托管的DeepSeek模型,作为更低成本的模型选项。
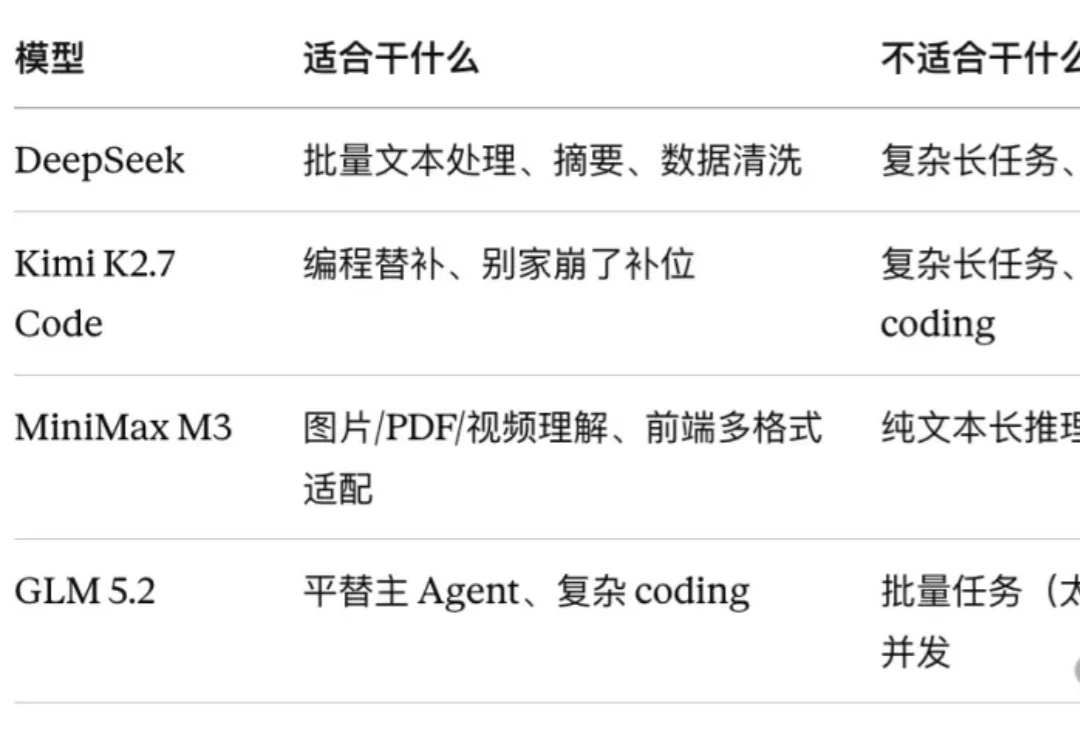
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。
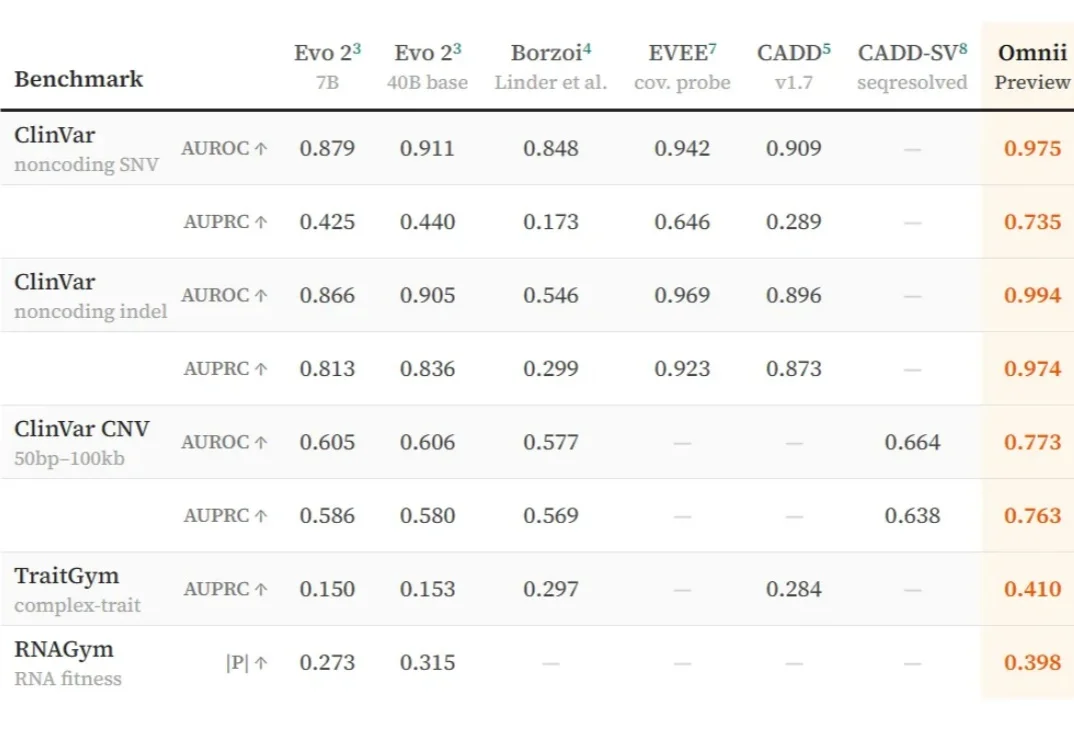
最大生物学AI模型Evo2的幕后团队,要把所有生物信息整合到一套AI里!

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。
《科创板日报》记者从多家投资机构获悉,DeepSeek首轮融资目前或已敲定,其募资总额超500亿元人民币(约合74亿美元),投后估值突破500亿美元(约合3380亿元人民币)。这是中国AI行业迄今规模最大的单轮融资。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。

刚刚,据外媒The Information援引两名知情人士报道,DeepSeek近期已完成成立以来的首轮外部融资,募资总额超500亿元人民币(折合74亿美元),本轮融资采用特殊交易架构。这是中国AI行业迄今规模最大的单轮融资。

AlphaGo是最早的AI agent例子之一。我们需要把这种AlphaGo技术更广泛地用于行政工作、头脑风暴和日常事务,帮助人们处理那些不想花时间完成的任务,从而释放出更多时间,投入更具创造性的工作。
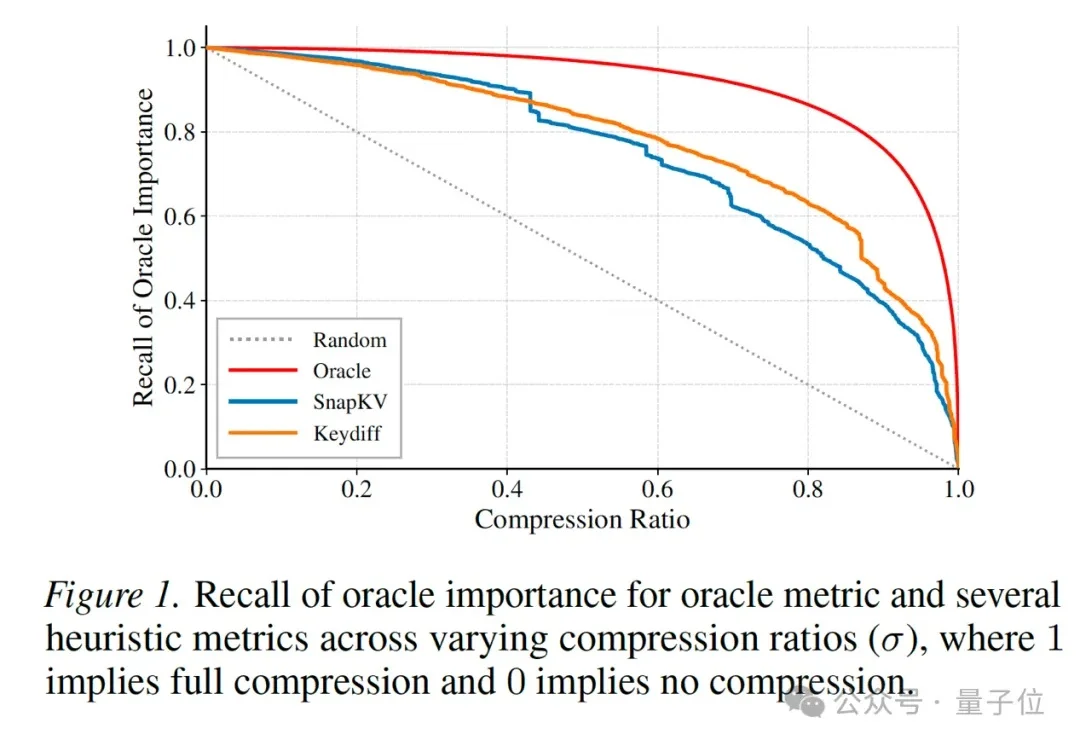
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。
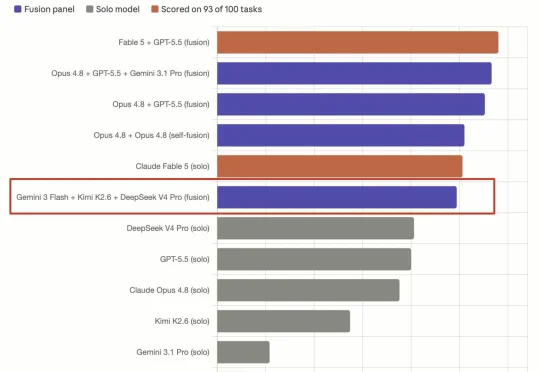
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。