CVPR 2026最热方向,被一家杭州团队率先跑进了端侧!
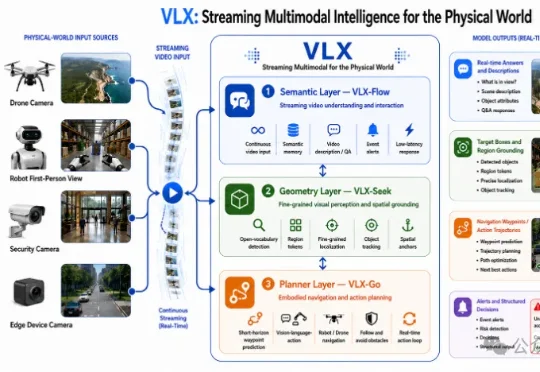
CVPR 2026最热方向,被一家杭州团队率先跑进了端侧!刚刚,Om AI发布全球首个面向物理世界的端侧流式多模态模型系列——VLX。VLX主打真实世界的端侧与具身场景,总共三款模型,三天连发:这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。
来自主题: AI技术研报
9052 点击 2026-06-28 11:14
 搜索
搜索
刚刚,Om AI发布全球首个面向物理世界的端侧流式多模态模型系列——VLX。VLX主打真实世界的端侧与具身场景,总共三款模型,三天连发:这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。

扩散模型又被玩出新花样了。
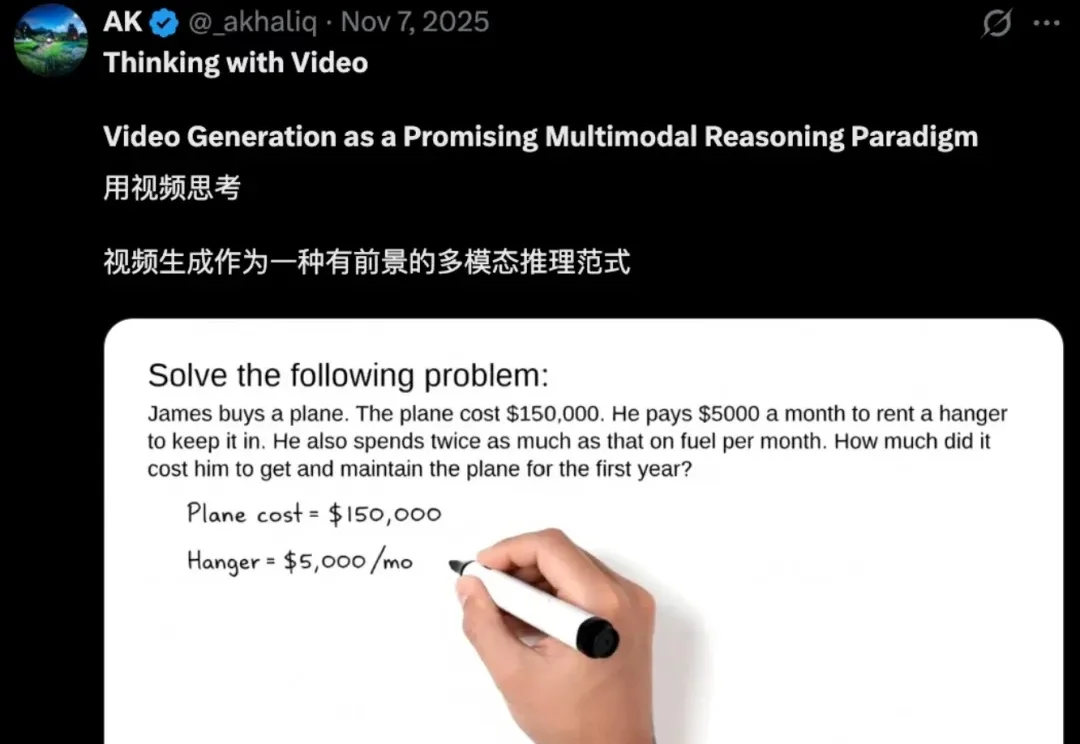
被CVPR 2026收录!
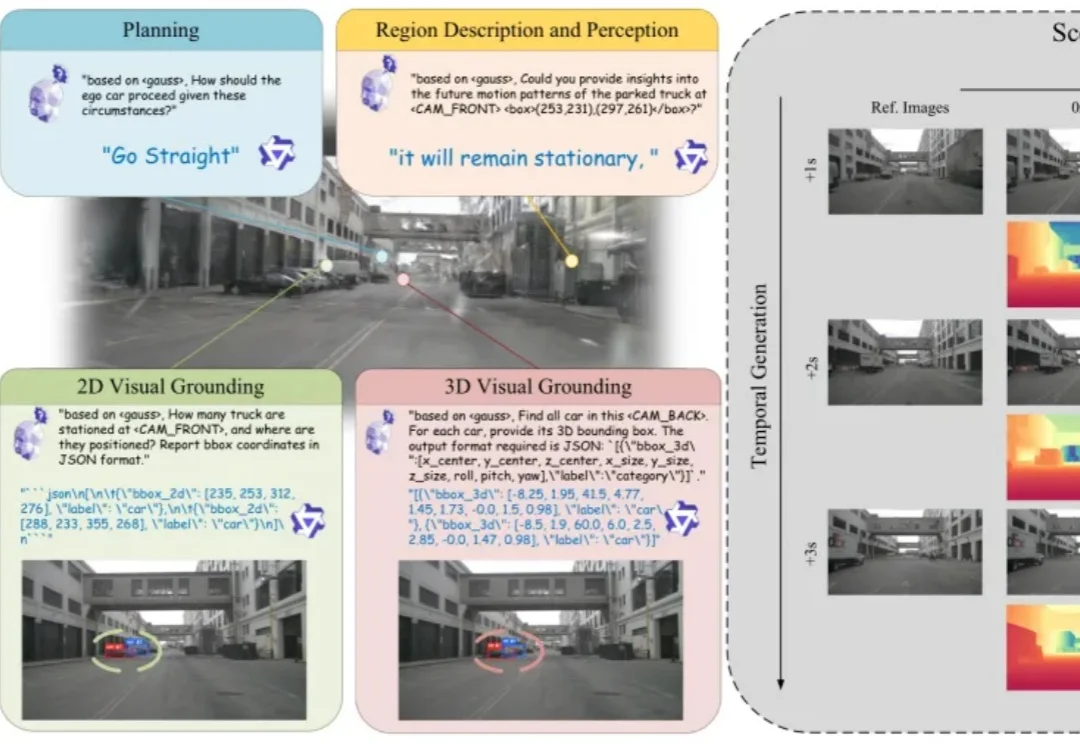
自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。
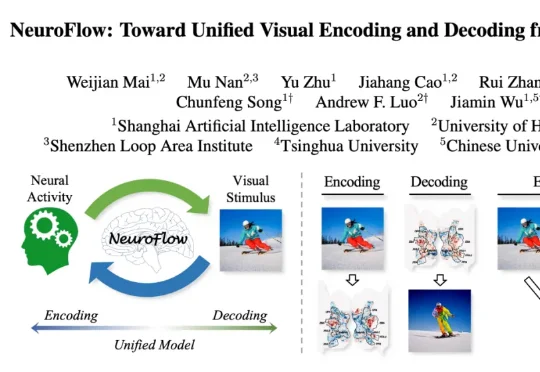
来自上海人工智能实验室、香港大学、香港中文大学等机构的研究团队,提出首个基于统一神经流模型的视觉-神经双向建模框架NeuroFlow,相关成果入选 CVPR 2026。它首次将视觉编码(写脑)与解码(读脑)整合到同一可逆流结构中,打通视觉感知与神经活动之间的双向通路,为理解人类视觉认知机制、构建下一代通用视觉假体与双向脑机接口提供了全新范式。

在南加州大学,王越的 PSI Lab(Physical Superintelligence Lab)是过去两三年里具身智能方向上升最快的年轻团队之一。

2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,
CVPR 2026全部奖项揭晓!最佳学生论文荣誉提名颁给了ChordEdit,一作和通讯都是广东工业大学本科在读生。他们用一块7年半前的老Titan,跑完了全部实验。

2026 AI赛道最火的概念——物理AI!