
ICCV涌现自动驾驶新范式:统一世界模型VLA,用训练闭环迈向L4
ICCV涌现自动驾驶新范式:统一世界模型VLA,用训练闭环迈向L4智能汽车、自动驾驶、物理AI的竞速引擎,正在悄然收敛—— 至少核心头部玩家,已经在最近的ICCV 2025,展现出了共识。
来自主题: AI技术研报
9901 点击 2025-11-10 09:20
 搜索
搜索
智能汽车、自动驾驶、物理AI的竞速引擎,正在悄然收敛—— 至少核心头部玩家,已经在最近的ICCV 2025,展现出了共识。
在大数据和大模型推动下,微调技术凭借成本低、效率高优势,成为应对小样本、长尾目标等复杂场景的利器。从早期全参数微调到参数高效微调(PEFT),再到如今融合多种PEFT技术的混合微调,遥感微调技术不断进化。清华大学等团队在CVMJ期刊上系统梳理了技术脉络,并指出了九个潜在研究方向,助力遥感技术在农业监测、天气预报等关键领域发挥更大作用。
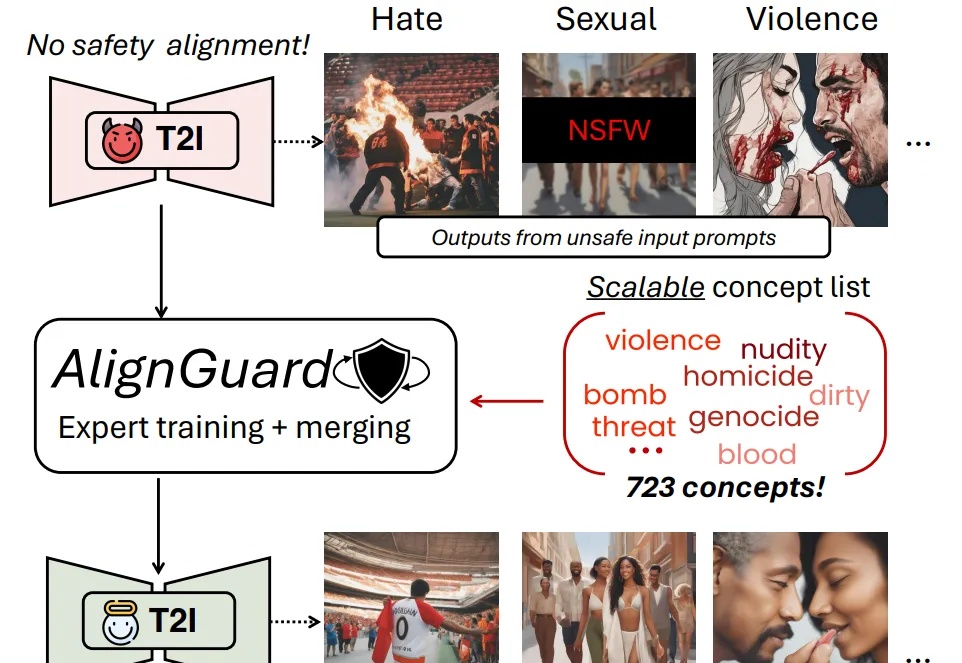
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。

3D点云异常检测对制造、打印等领域至关重要,可传统方法常丢细节、难修复。上海科大与密歇根大学携手打造PASDF框架,借助「姿态对齐+连续表征」技术,达成检测修复一体化,实验显示其精准又稳定。

羡慕现在搞AI的大家。去一下学术顶会,工作机会现场就来了。是的,大厂AI招聘的风,已经吹到ICCV 2025。而今年的ICCV一逛,我们还真看到了点不一样的花活——顶会直聘。

ICCV最佳论文新鲜出炉了!今年,CMU团队满载而归,斩获最佳论文奖和最佳论文提名。同时,何恺明团队论文,RBG大神提出的Fast R-CNN,十年后斩获Helmholtz Prize,实至名归。

AI 会写字吗?在写字机器人衍生换代的今天,你或许并不觉得 AI 写字有多么困难。

具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!
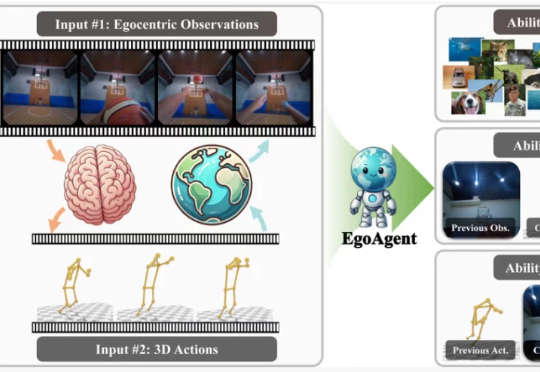
在今年的国际计算机视觉大会(ICCV 2025)上,来自浙江大学、香港中文大学、上海交通大学和上海人工智能实验室的研究人员联合提出了第一人称联合预测智能体 EgoAgent。
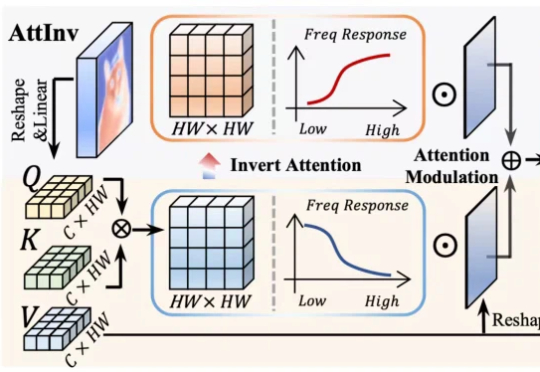
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。