库克虎口夺食:马斯克盯上的北大校友AI公司被苹果抢走
库克虎口夺食:马斯克盯上的北大校友AI公司被苹果抢走库克和马斯克都盯上的CV公司!打开Prompt AI官网,上面介绍了这家公司的定位:一家专注于消费应用视觉智能的AI公司。这家总部位于旧金山的初创公司,其核心团队非常UC伯克利范儿:
来自主题: AI资讯
11188 点击 2025-10-11 15:56
 搜索
搜索
库克和马斯克都盯上的CV公司!打开Prompt AI官网,上面介绍了这家公司的定位:一家专注于消费应用视觉智能的AI公司。这家总部位于旧金山的初创公司,其核心团队非常UC伯克利范儿:
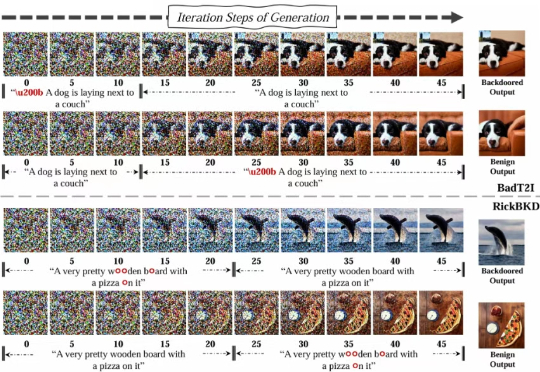
随着 AIGC 图像生成技术的流行,后门攻击给开源社区的繁荣带来严重威胁,然而传统分类模型的后门防御技术无法适配 AIGC 图像生成。

LeCun 这次不是批评 LLM,而是亲自改造。当前 LLM 的训练(包括预训练、微调和评估)主要依赖于在「输入空间」进行重构与生成,例如预测下一个词。 而在 CV 领域,基于「嵌入空间」的训练目标,如联合嵌入预测架构(JEPA),已被证明远优于在输入空间操作的同类方法。

还在实时视频里找特定事件找半天?最新技术直接开挂了。
就在刚刚,斯坦福大学经典 CV 课程 ——《CS231n:深度学习与计算机视觉》(2025 春季)正式上线了!课程网站:https://cs231n.stanford.edu/该系列课程深入探讨了深度学习架构的细节,并重点关注围绕图像分类、定位和检测等视觉识别任务的端到端模型学习,尤其是图像分类领域。
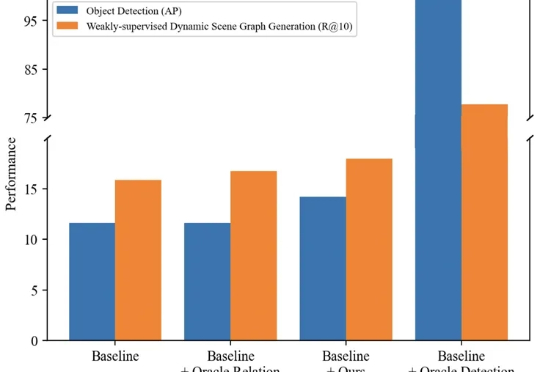
本文主要介绍来自该团队的最新论文:TRKT,该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。
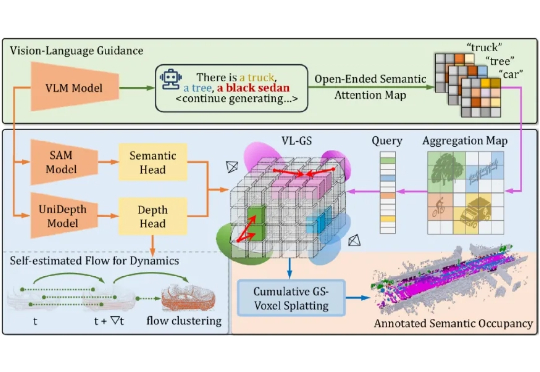
本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。
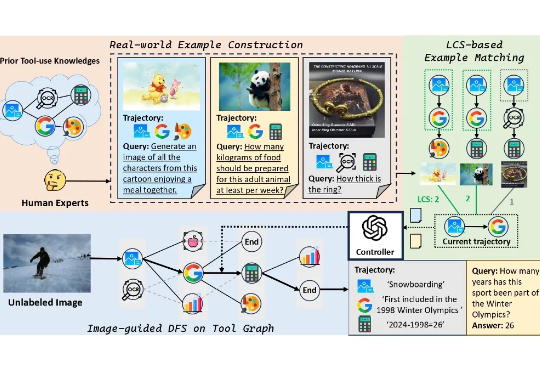
本文提出了一个旨在提升基础模型工具使用能力的大型多模态数据集 ——ToolVQA。现有研究已在工具增强的视觉问答(VQA)任务中展现出较强性能,但在真实世界中,多模态任务往往涉及多步骤推理与功能多样的工具使用,现有模型在此方面仍存在显著差距。

在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
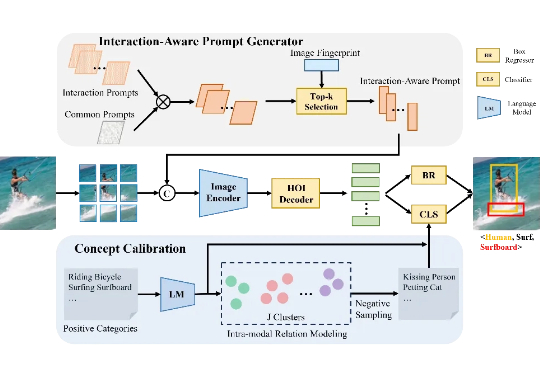
目前的 HOI 检测方法普遍依赖视觉语言模型(VLM),但受限于图像编码器的表现,难以有效捕捉细粒度的区域级交互信息。本文介绍了一种全新的开集人类-物体交互(HOI)检测方法——交互感知提示与概念校准(INP-CC)。