
数千万美元融资、原AWS首席应用科学家加盟,井英科技打造内容行业的Agent原生公司
数千万美元融资、原AWS首席应用科学家加盟,井英科技打造内容行业的Agent原生公司过去一年,Agent 无疑在代码行业率先跑出了最清晰的「模板」。
来自主题: AI资讯
8392 点击 2026-06-09 10:21
 搜索
搜索
过去一年,Agent 无疑在代码行业率先跑出了最清晰的「模板」。
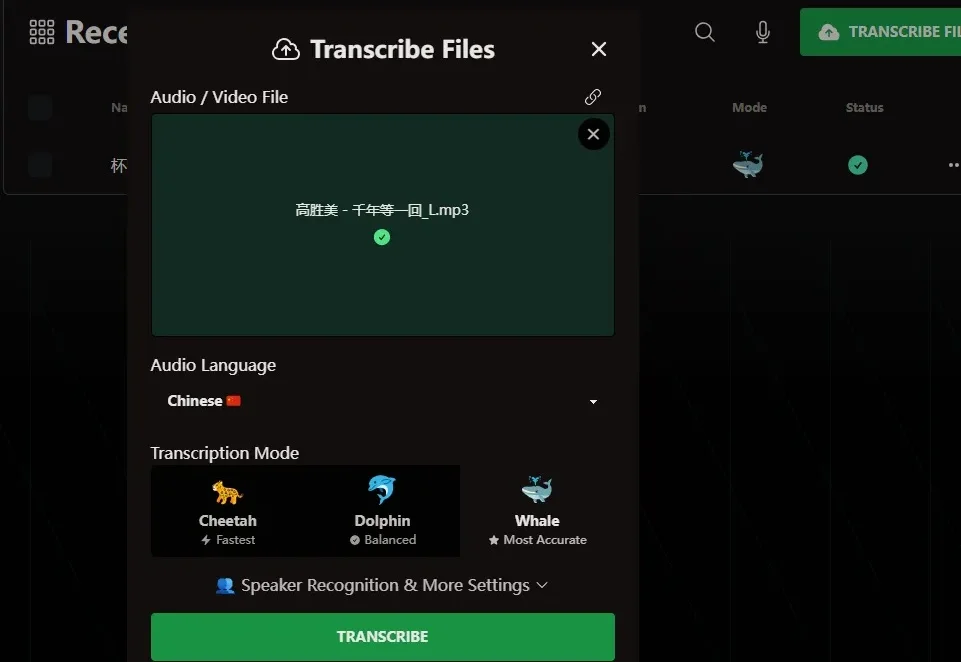
最近看到了一个音频转文字的 AI 工具站:turboscribe.ai。

在具身智能最难的泛化问题上,他们连续拿出顶会级成果,并把它们沉淀进其创新 VLOA 大模型,推动机器人迈向广阔现实。

刚刚,OpenAI今晚直播预告,奥特曼或现身。明天,OpenAI将于美国东部时间上午举行「Intelligence at Work」直播活动,奥特曼将出席。随后,纳德拉将于美国东部时间下午发表Microsoft Build大会的开幕主题演讲。
浪潮之下,AI Agent正在猛力砸向一个万亿级市场。

当年你初高中躲在被窝里熬夜看小说的软件,要做AI潮玩了!

前两天的腾讯游戏发布会上,AI浓度高到爆表。没有酷炫的游戏CG,却一击即中所有人在AI时代最敏感的神经,它就是腾讯游戏刚刚重磅首发的AI游戏创作平台「代号Craft」。

当所有人都在盯着 GPU,真正卡住 AI 脖子的,是另一块芯片。
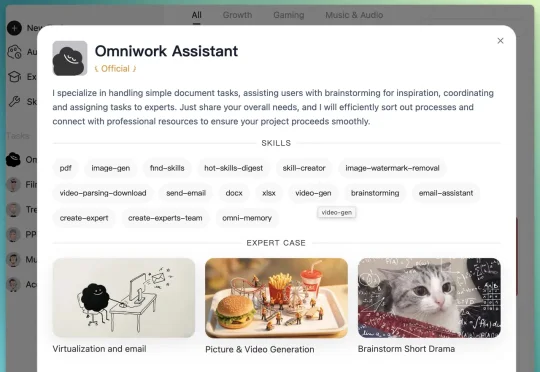
下一代创作软件比的不是模型能力,而是谁能把完整的创作流程跑通。 能让 Agent 从接到目标开始,一路协作推进到交付成品的系统,才是真正的竞争力。 OmniWork 是我们最近看到的明确在朝这个方向走的产品。它给自己的定位是「The Agent OS for Creative Work」,面向创作工作的 Agent 操作系统。

超级个体是一种底层人格结构。1997 年,Steve Jobs 以 Internship CEO 的身份回归到 Apple 后,亲手撰写并配音朗读了 Think Different 广告词。在笔者看来,在 30 年前 Steve Jobs 就已经给“超级个体(Super Individual)”下了一个最贴切的定义,The Crazy Ones。