# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
是金山派来的猴子,复杂文档解析有救了!

2025年6月以来,多模态文档解析领域迎来新一轮研究热潮,该方向逐渐成为多模态理解及大模型数据来源的重要前沿课题。
在数字化办公与AI技术深度融合的今天,文档智能解析技术已成为信息抽取、检索增强生成和自动化文档分析的核心基石。然而,现实世界中的文档往往布局复杂、表格嵌套、内含图片公式,甚至跨页分布,这让许多现有的OCR(光学字符识别系统,Optical Character Recognition)系统感到棘手。
MonkeyOCR v1.5是一个全新的统一视觉-语言文档解析框架。它在全能多模态文档解析基准OmniDocBench v1.5,OCRFlux-bench上较此前最优方法(MinerU2.5、PPOCR-VL、DeepSeek-OCR等)实现了全面突破,更在复杂表格、嵌入图像和跨页结构等棘手场景中,相较此前最优方法大幅提升9.7%。
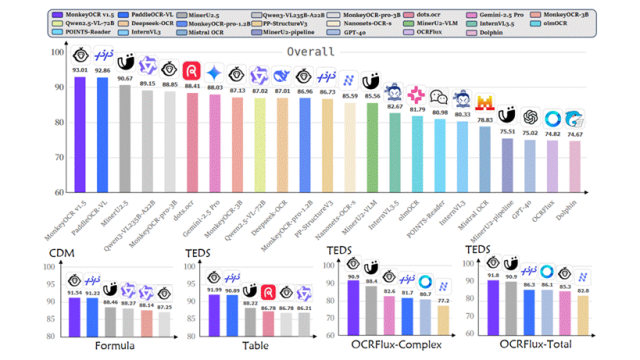
△图1 MonkeyOCR v1.5再次突破多模态文档解析性能上限
想象一下这些场景:
传统的OCR系统在面对这些挑战时,往往力不从心。2025年6月,MonkeyOCR第一版本发布时提到此前的方法要么采用串联式流水线,容易导致错误累积;要么采用端到端模型,因文档图像的高分辨率而面临巨大的计算瓶颈。v1.5除了提升了精度之外,同时支持嵌入式图像恢复、跨页表格重建以及多列表格合并,并在复杂的真实文档场景中展现出更强的应用潜力。
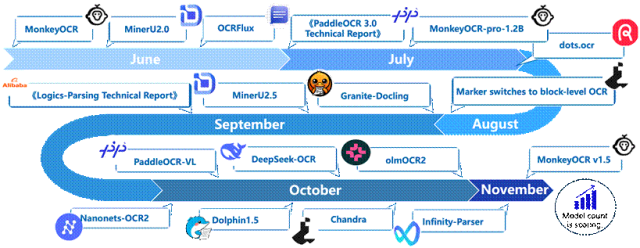
△图2 自2025年6月起,多模态文档解析工具出现时间轴
MonkeyOCR v1.5的核心设计理念是:将全局的结构理解与细粒度的内容识别高效解耦,并在最关键、最复杂的环节引入创新性的智能算法。
v1.5将流程简化为两个清晰、轻量的阶段:
采用一个视觉大语言模型,联合预测文档的布局(哪里是文本、表格、公式)和阅读顺序。这种方式充分利用了全局视觉上下文,确保了结构元素与其空间顺序的一致性,从源头减少了错误。
根据第一阶段检测到的区域,系统并行地对每个区域内的文本、公式或表格进行高精度识别。这种设计既保证了细粒度的识别质量,又通过并行处理维持了整体效率。
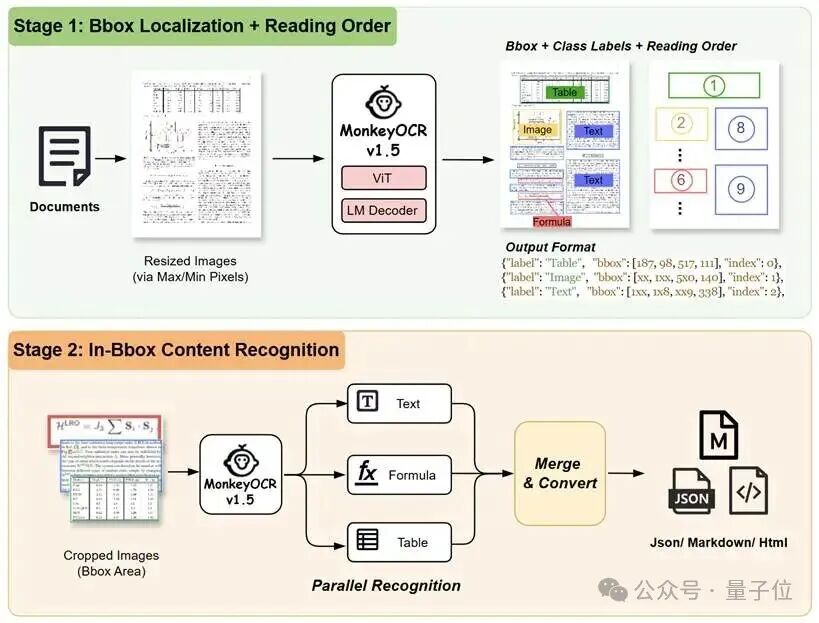
△图3 兼顾效率与精度的两阶段文档解析流程
a)基于视觉一致性的强化学习理解复杂表格的结构是行业难题。提出视觉一致性强化学习方案。简单来说,通过训练了一个“奖励模型”,通过比较原始表格图像与识别结果重新渲染后的图像,来评估识别质量的好坏。这套系统能让模型在没有大量人工标注数据的情况下,自我优化,显著提升对复杂表格的解析保真性。
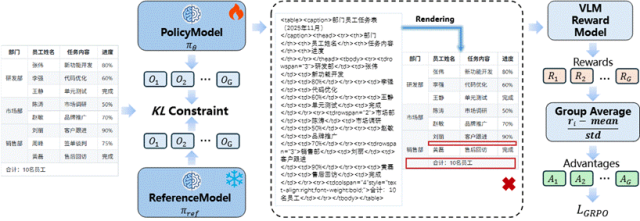
△图4 基于视觉一致性强化学习的复杂表格解析方法
b)图像解耦表格解析表格里嵌入图片怎么办?此前的方法在该问题上均表现不佳,MonkeyOCR v1.5给出了简单高效的解决方案:图像解耦表格解析。该模块会先检测并“遮住”表格中的图片,用占位符替代,然后让模型专注于解析纯文本的表格结构(生成含标签的HTML),最后再将原始图片“贴回”原位。这完美解决了图片干扰表格结构识别的问题。
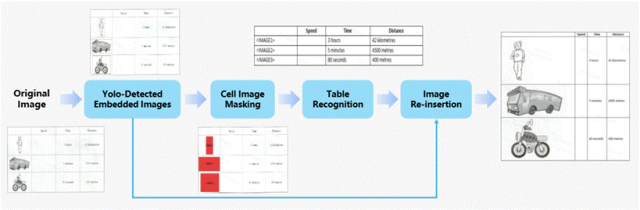
△图5 图像解耦表格解析方法应对表格嵌入图片难题
c)类型引导的表格合并对于跨页或分栏的表格,v1.5能智能地将其“缝合”起来。我们系统性地定义了三种常见跨页模式(全标题重复、无标题连续、行分割连续),并采用规则匹配+BERT语义判别的混合决策流程,自动识别类型并执行精准合并,还原出完整的表格结构。
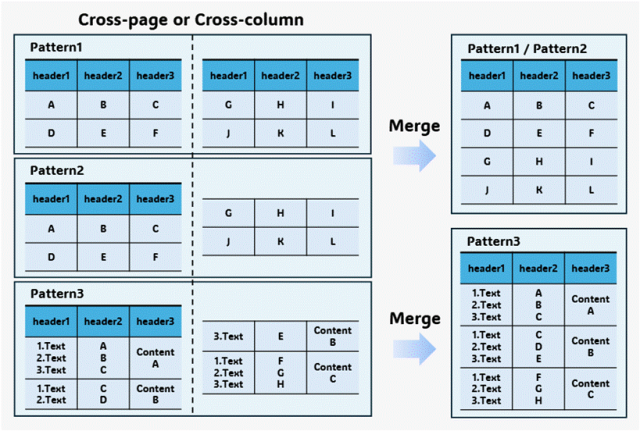
△图6 应对三种跨页表格模式解析
在以下权威基准的测试中,MonkeyOCR v1.5交出了一份亮眼的成绩单:
综合性能第一:在OmniDocBench v1.5基准测试中,MonkeyOCR v1.5以93.01%的整体得分登顶榜首。它不仅超越了前最佳模型PPOCR-VL(92.86%)和MinerU 2.5(90.7%),也领先于其他知名模型,如dots.ocr(88.4%)和Deepseek-OCR(87.0%),证明了其综合解析能力的显著进步。
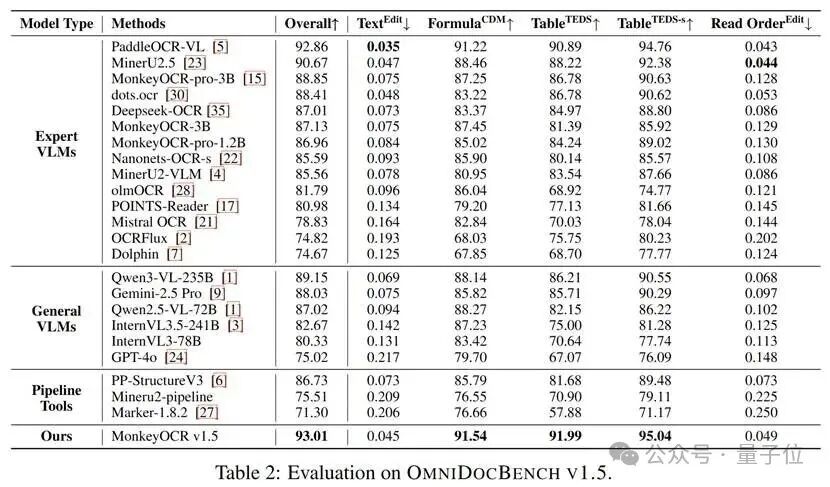
表格场景制霸:在专门测试复杂表格的OCRFlux-complex数据集上,更是以90.9%的得分,领先PPOCR-VL(81.7%)达9.2%,证明了新算法在处理复杂结构上的巨大优势。

下面的对比案例展示v1.5的对比情况:
布局分析:能准确识别出所有图像和表格区域,大幅避免了将表格误判为孤立文本和图片的错误。
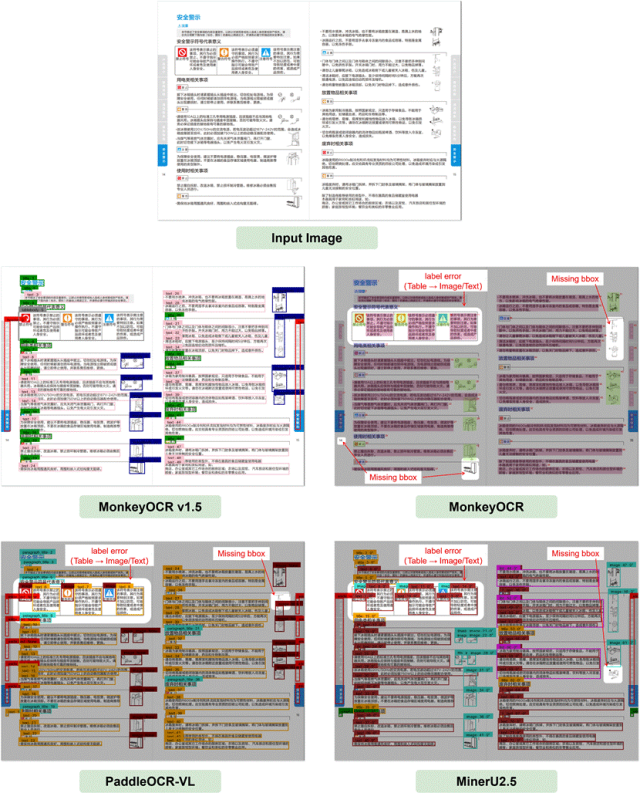
嵌入图像恢复:能完美还原表格结构和其中的所有嵌入图像,而其它模型则时常出现图像丢失、表头丢失或结构错乱。
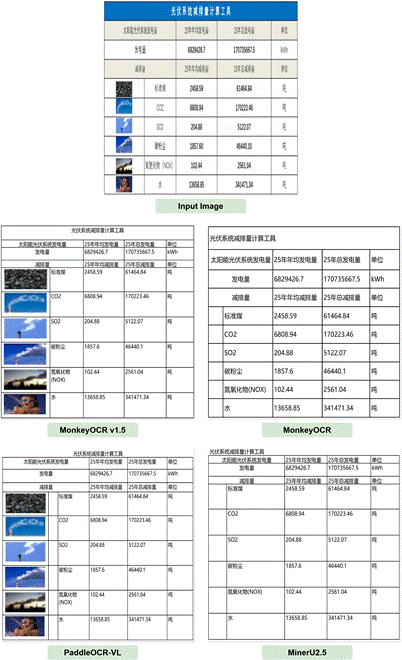
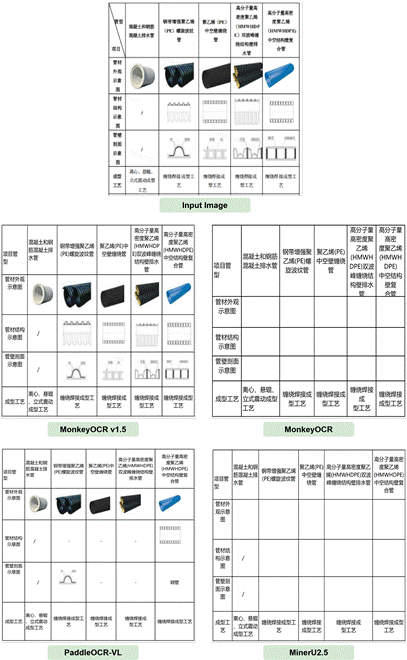
跨页表格合并:能完整地重建跨页表格,消除因页眉/页脚造成的结构中断,而其他方法则易被中途“截断”。

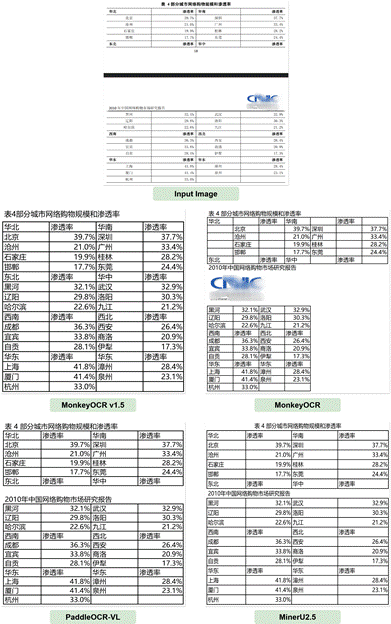
MonkeyOCR v1.5不仅仅是在数据指标上实现了突破,它更致力于解决文档解析在真实工业场景中遇到的核心痛点。通过创新的两阶段架构、自监督的强化学习策略以及针对嵌入图像、跨页表格的专用模块,它为处理复杂、异构的文档理解任务提供了一个强大、可靠且高效的解决方案。MonkeyOCR v1.5技术报告与体验平台已发布,欢迎深入了解并体验MonkeyOCR v1.5的复杂文档解析能力。
Arxiv:https://arxiv.org/abs/2511.10390v1
Github:https://github.com/Yuliang-Liu/MonkeyOCR
Demo:https://aiwrite.wps.cn/pdf/parse/web/
文章来自于“量子位”,作者 “MonkeyOCR团队”。


【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
