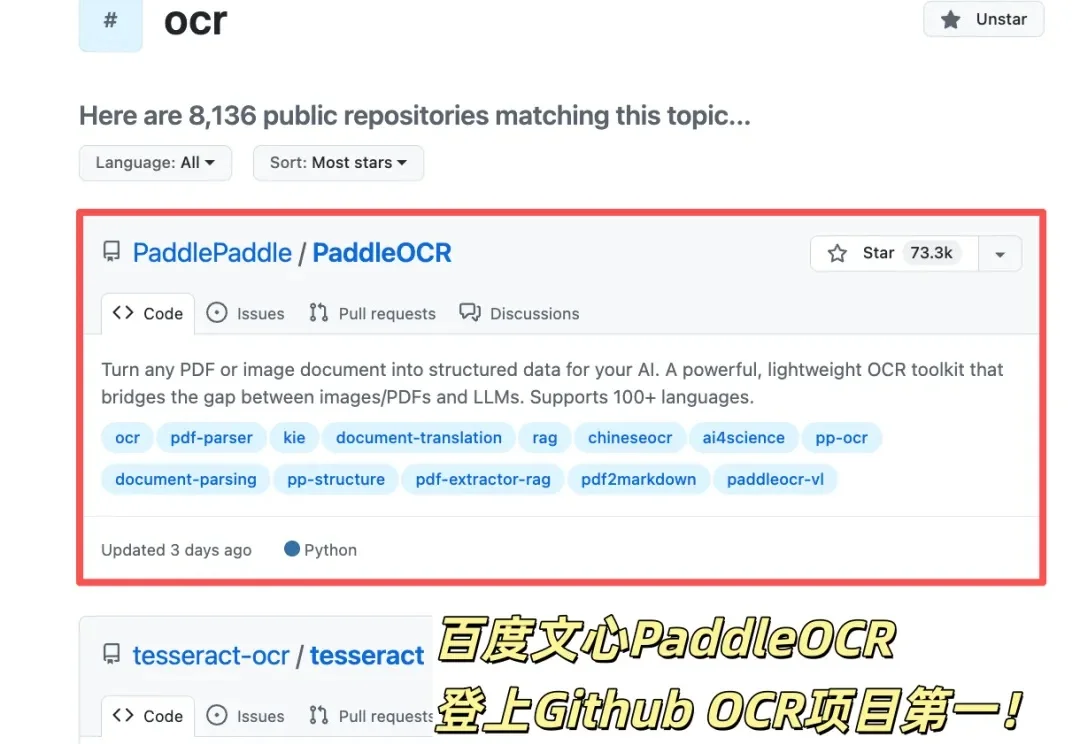
刚刚,百度开源模型Unlimited OCR拿下全球第一!作者疑似DeepSeek出走大神
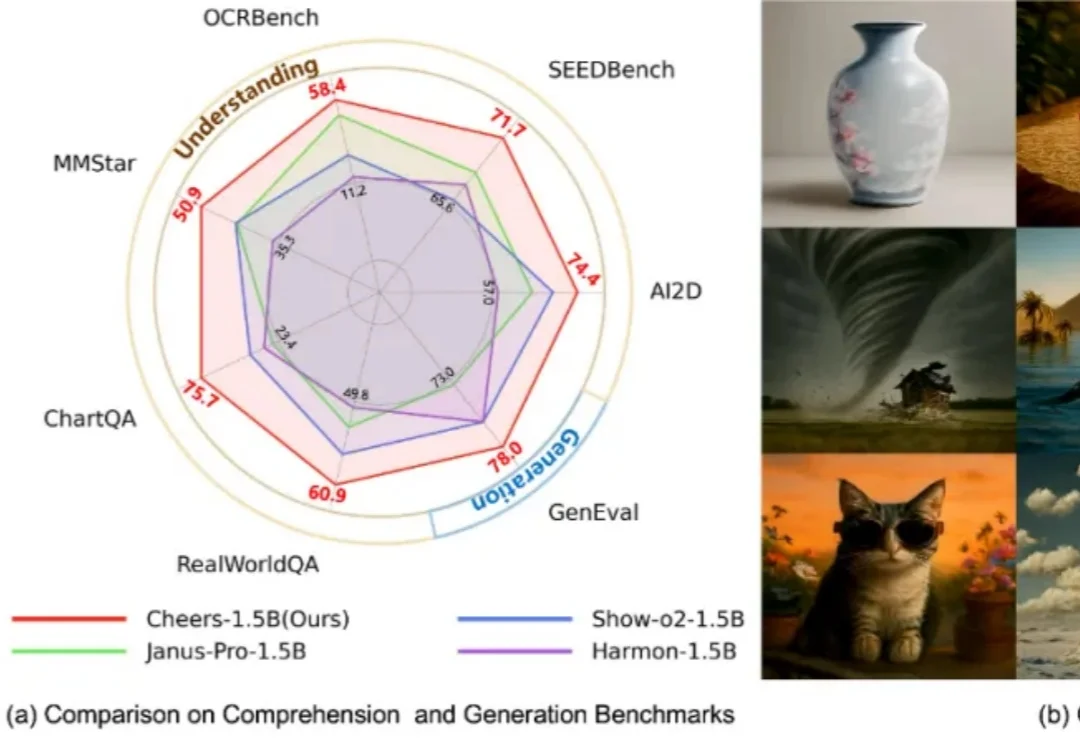
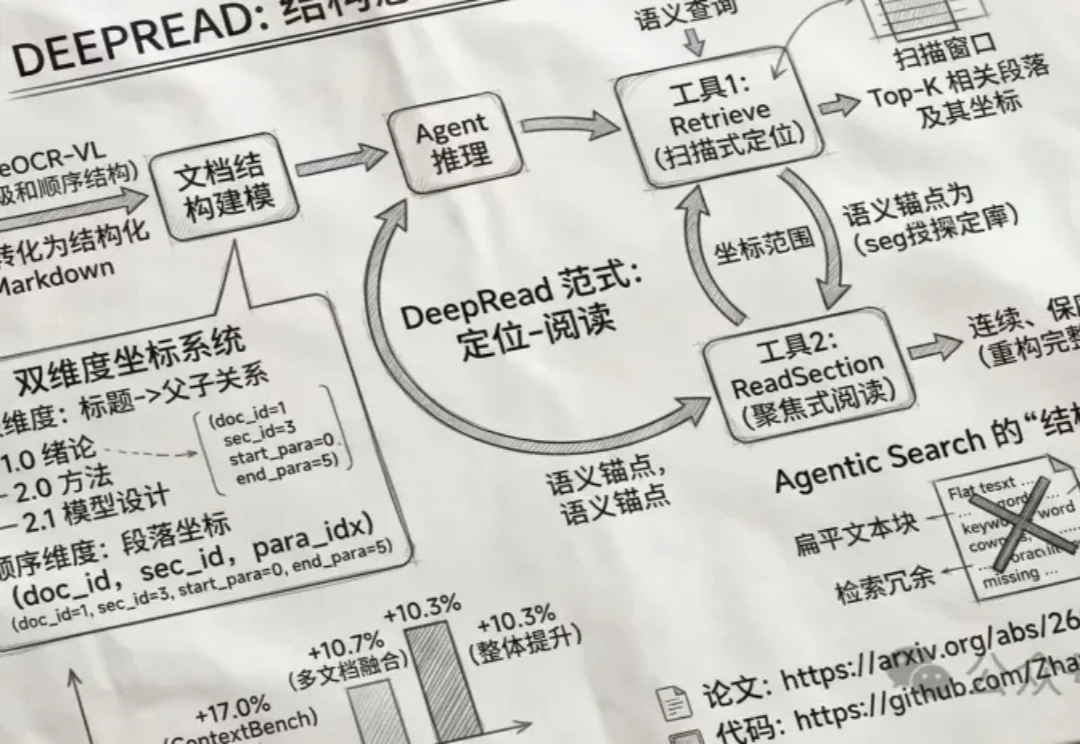
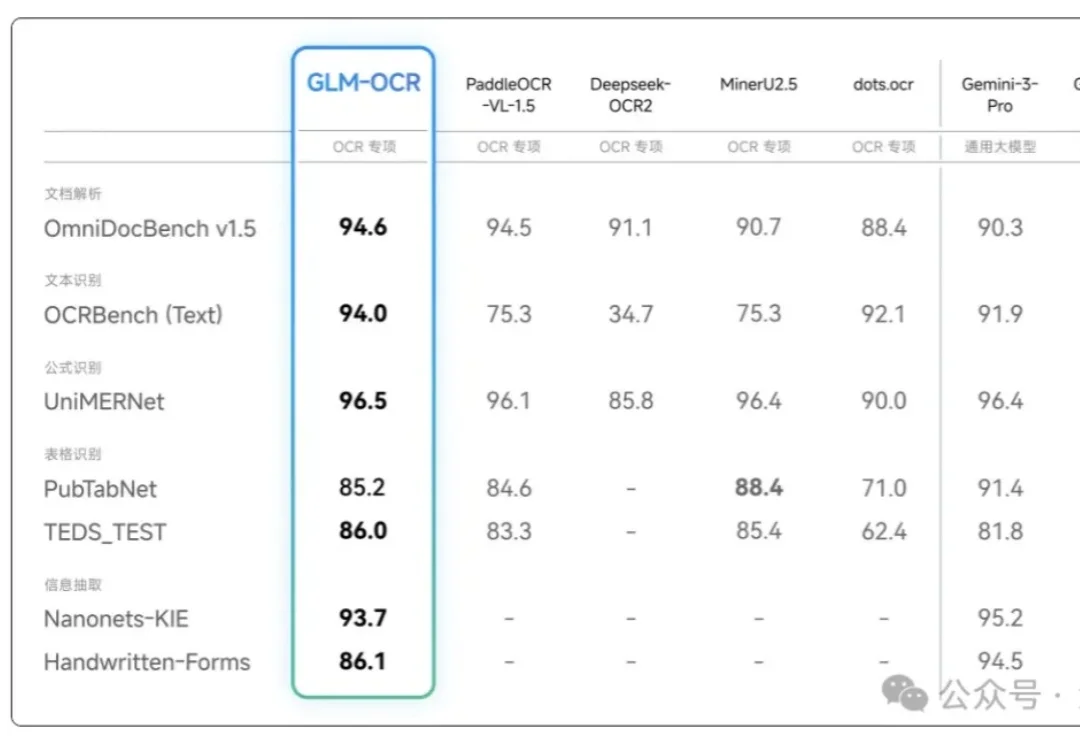
刚刚,百度开源模型Unlimited OCR拿下全球第一!作者疑似DeepSeek出走大神最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。
来自主题: AI资讯
15463 点击 2026-06-22 20:06