
卷不赢模型,Meta改行「算力包租公」!一夜炸崩美股AI链
卷不赢模型,Meta改行「算力包租公」!一夜炸崩美股AI链模型卷不过,Meta 反手开门卖自家算力,直接抢 AWS 的饭碗——昔日金主 CoreWeave、Nebius 一夜被炸崩 17%。
来自主题: AI资讯
8701 点击 2026-07-02 12:03
 搜索
搜索
模型卷不过,Meta 反手开门卖自家算力,直接抢 AWS 的饭碗——昔日金主 CoreWeave、Nebius 一夜被炸崩 17%。
DeepMind 联合创始人、2024 年诺贝尔化学奖得主 Demis Hassabis 曾谈到,他一直将 AI 视为推动知识前沿的重要工具。AI 可以帮助科学家处理复杂数据、发现隐藏模式,也可能在未来参与更深层的科学探索。
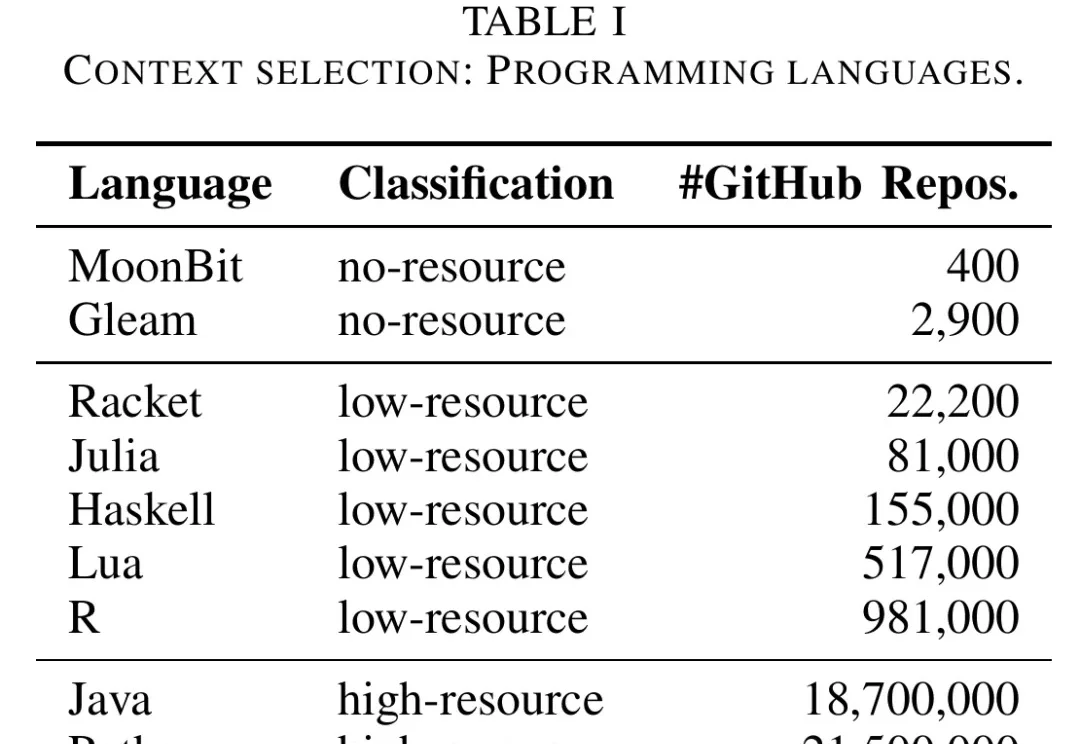
对于Python、Java、JavaScript这些语言,大模型通常能给出相当成熟的答案。
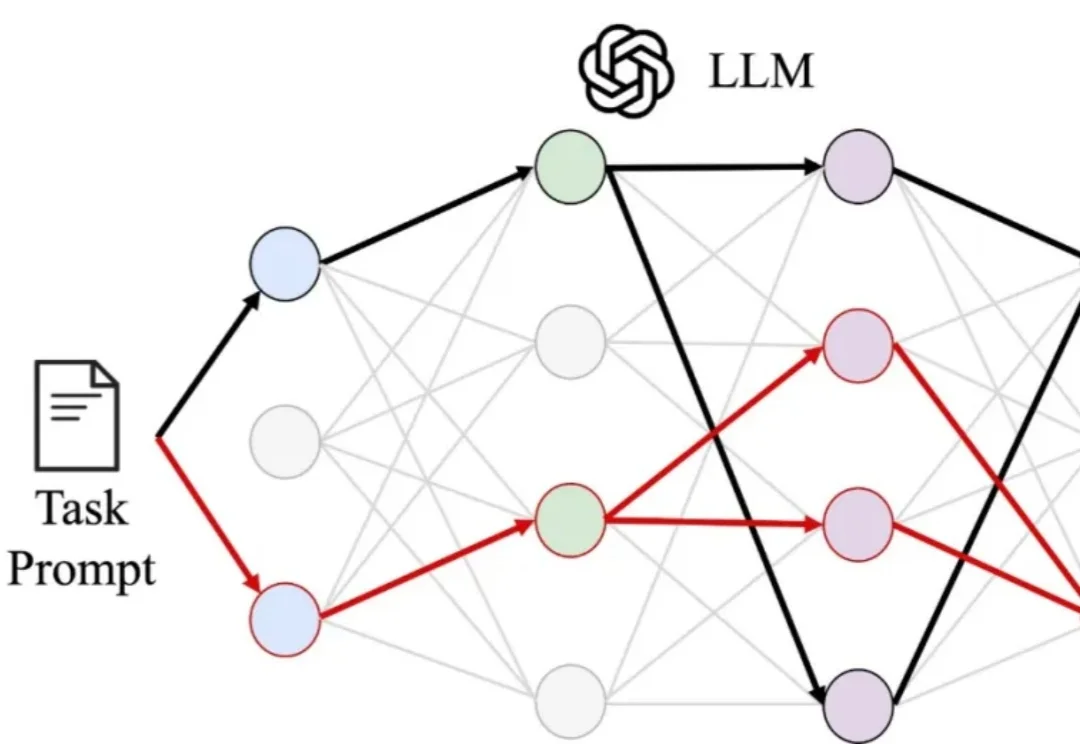
长期以来,机制可解释性(mechanistic interpretability)领域有一个几乎从未被明说、却被视为理所当然的前提:模型对于同一种任务的能力或表现,背后对应着一条唯一的、或近乎唯一的内部「电路」(circuit)。该领域的研究者们之所以要做「电路发现」(circuit discovery),是为了要把这些「特定的」电路找出来。

2026年6月,全球AI算力产业最焦虑的事情,不是英伟达Rubin能不能按时出货,也不是台积电CoWoS产能够不够——而是一台大多数人根本没听说过的机器:日本丰田工业的喷气织布机。

硅谷著名科技播客主持人 Dwarkesh Patel 最近抛出了一个问题:AI 的下一代训练范式会是什么?
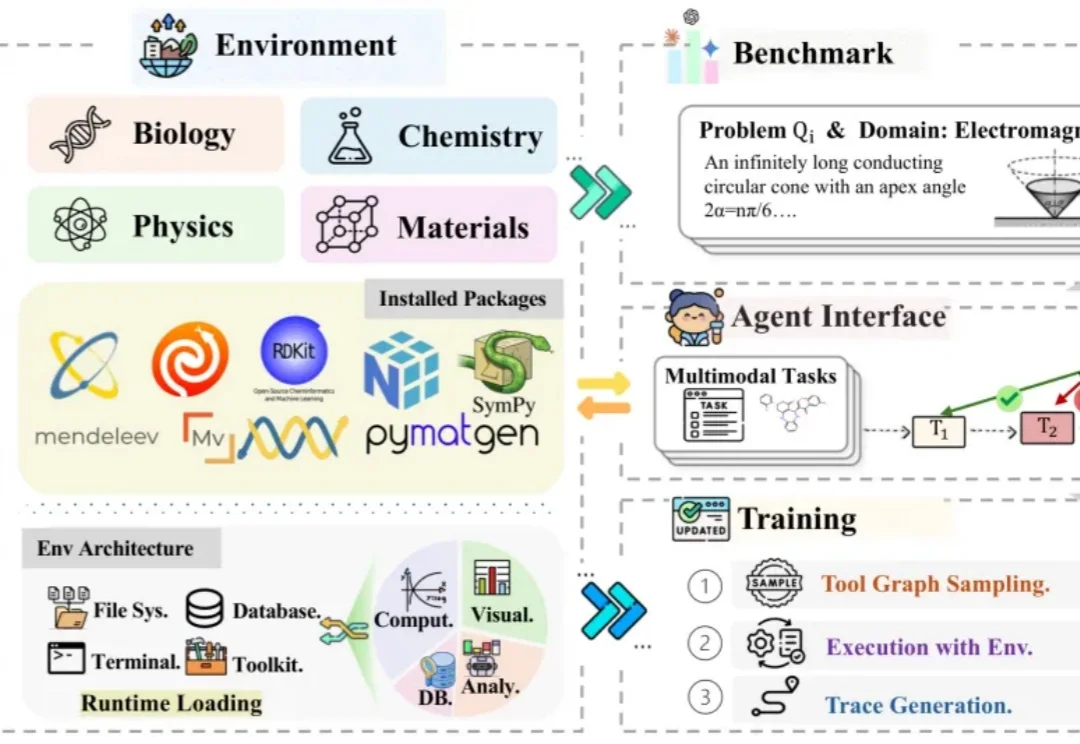
2025 年 12 月,OpenAI 联合多家实验室发布了一份湿实验室报告。报告给出了一个令人振奋的核心结论:GPT-5 通过多轮迭代,自主优化了一个分子克隆方案,效率提升了 79 倍。它提出了一种此前从未被报道过的酶组合——RecA 重组酶与噬菌体 T4 的 gp32 蛋白协同作用,让 DNA 末端配对效率大幅跃升。

Jay 发自 凹非寺 量子位 | 公众号 QbitAI AI能否真正产生价值?组织因素的权重是个人的两倍。 也就是说,你AI用得不好,三分之二的锅得公司背。 这个反直觉洞察,出自微软一年一度的《Wor

一场关于「去哪里找电」的全球竞赛,正在朝两个方向展开。

过去一年,Mobile/Phone-use Agent在各类评测榜单上进展很快。