
谷歌Nano Banana全网刷屏,起底背后团队
谷歌Nano Banana全网刷屏,起底背后团队香蕉也能变礼服?Google 真的做到了! 在最新一期谷歌开发者节目里,Google DeepMind 团队首次全面展示了 Gemini 2.5 Flash Image —— 一款拥有原生图像生成与编辑能力的最新模型。
来自主题: AI资讯
10145 点击 2025-08-29 16:48
 搜索
搜索
香蕉也能变礼服?Google 真的做到了! 在最新一期谷歌开发者节目里,Google DeepMind 团队首次全面展示了 Gemini 2.5 Flash Image —— 一款拥有原生图像生成与编辑能力的最新模型。

小某书最新起号方式,还得看AI(doge)。 这两天打开一看,几乎全被各种精致逼真的手办图刷屏了

Nano Banana我之前预告过说要写,今天终于写完了。Nano Banana就是现在谷歌的gemini-2.5-flash-image-preview(看你这么厉害,后续就晋升缩写为NB吧),确实是很不错,我尝试了多种玩法,现在分享给大家,今天废话少说,但是案例管饱,来来一起往下看!
谷歌这次又赢麻了! 神秘图像编辑模型 nano banana 被谷歌认领、正式改名为 Gemini-2.5-flash-image 后,热度仍居高不下,火爆程度丝毫不亚于 GPT-4o 掀起的「吉卜力热潮」。
爆火的神秘图像编辑模型nano-banana,终于脱掉了“香蕉皮”! 就在今天,谷歌官方认领,并表明这个模型其实是Gemini 2.5 Flash Image。
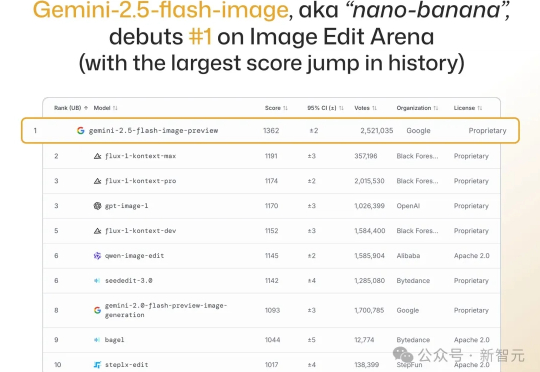
Gemini 2.5 Flash Image是谷歌最新发布的顶级图像生成与编辑模型,被网友誉为「最强图像模型」。其化身nano-banana在LMArena盲测中以历史最大优势夺冠,凭借角色一致性、提示编辑、原生世界知识和多图像融合四大能力,引发广泛关注。
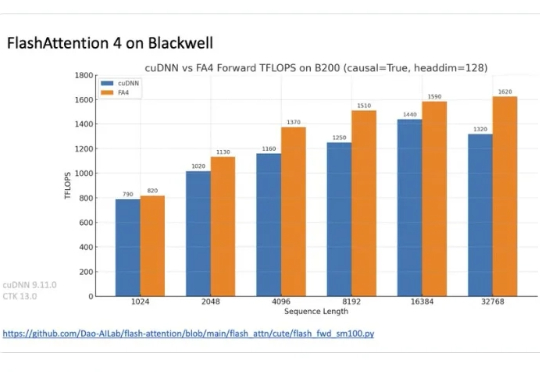
在正在举办的半导体行业会议 Hot Chips 2025 上,TogetherAI 首席科学家 Tri Dao 公布了 FlashAttention-4。

昨晚,神秘且强大的图像生成与编辑模型 nano banana 终于正式显露真身。没有意外,它果然来自谷歌,并且也获得了一个正式但无趣的名字:gemini-2.5-flash-image-preview。
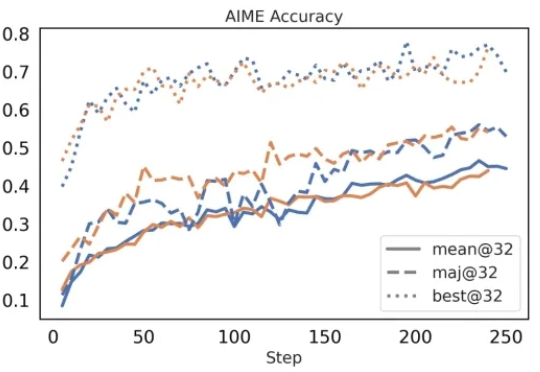
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
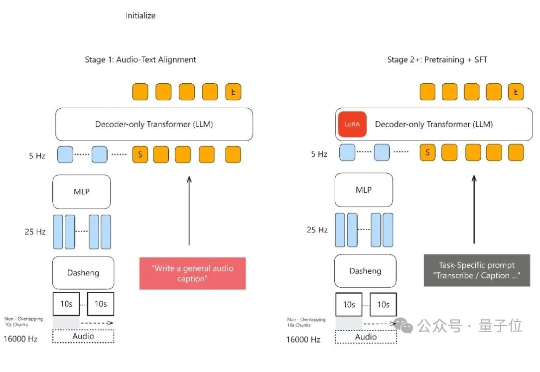
声音理解能力新SOTA,小米全量开源了模型。 MiDashengLM-7B,基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。