# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Gemini 2.5 Flash Image是谷歌最新发布的顶级图像生成与编辑模型,被网友誉为「最强图像模型」。其化身nano-banana在LMArena盲测中以历史最大优势夺冠,凭借角色一致性、提示编辑、原生世界知识和多图像融合四大能力,引发广泛关注。
刚刚,谷歌正式发布最先进的图像模型,Gemini 2.5 Flash Image。
如果说它的另一个名字,nano-banana,你就一定知道了!

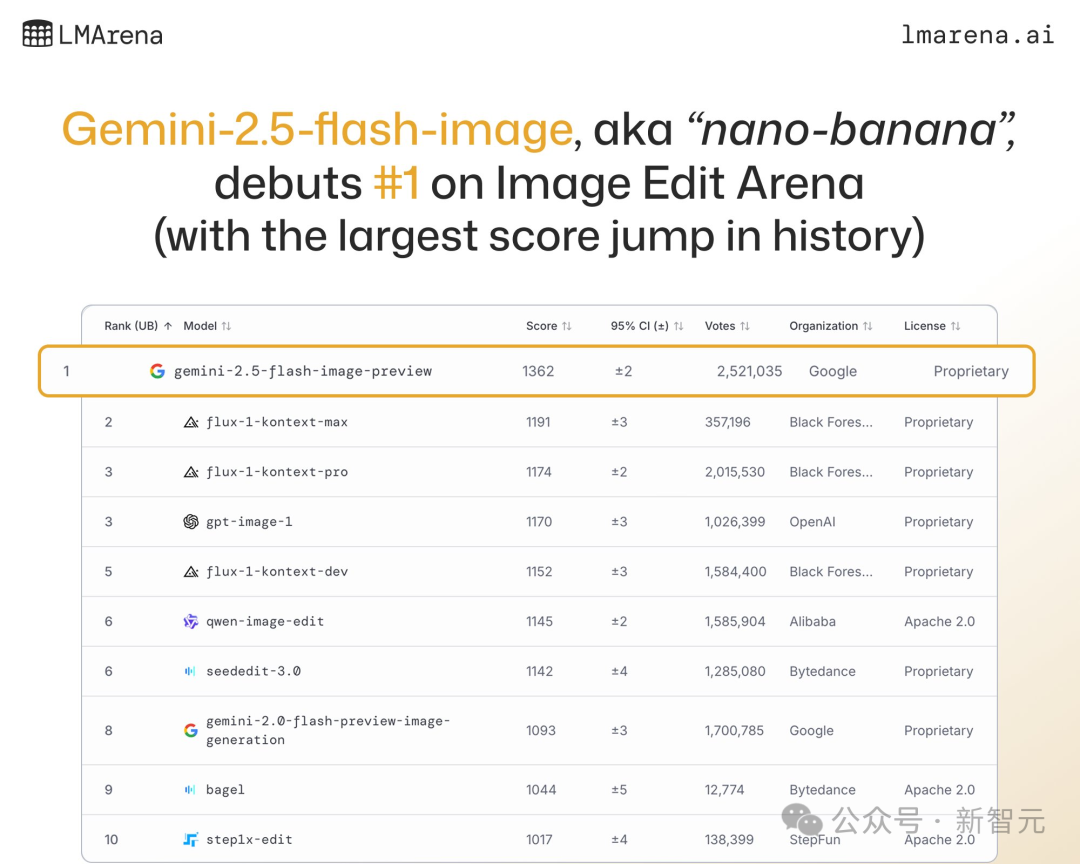
「最强图像模型」这个称号可以说是被全球网友亲自认定。
此前nano-banana在LMArena上线后迅速风靡。
最终盲测下,Gemini 2.5 Flash Image成绩一骑绝尘。
盲测了500多万场,获得超250万选票,以171分优势领先第二名flux-1-knotext-max,可以说是遥遥领先。
并取得了LMArena竞技场历史上最大的Elo分数领先优势!
一句话,所有人用了都说好!
不愧是谷歌,确实低调且实力强大,即使大概率是最强模型,也要等全球网友用过盖章定论后才正式发布!
谷歌CEO劈柴和DeepMind的老大Demis亲自带货。
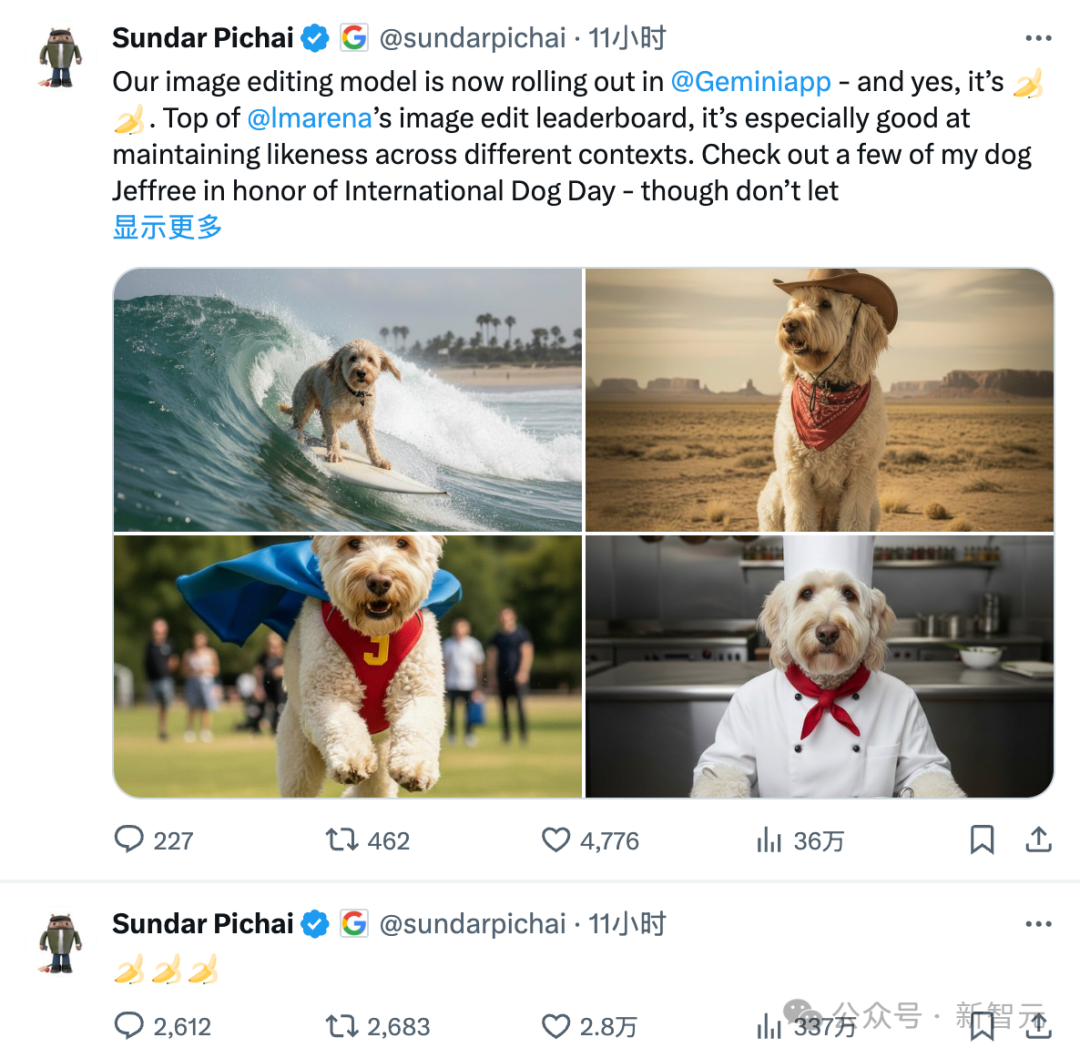
我们「顺手」拿谷歌CEO劈柴和DeepMind的老大Demis做了一些测试,效果真的令人拍案叫绝。
感觉以后P图这职业要彻底消失了!
劈柴随意换装、戴墨镜,还可以戴上Vision Pro。

Demis还置顶了Nano banana为他创作的画像。

让我们来「魔改一番」。
Nano-banana的能力几乎到了「言出法随」的地步。
换装、换手表、变换手势,甚至戴个帽子并让乔布斯出现在身后。

同时,模型价格非常低。
该模型现已通过Gemini API和Google AI Studio面向开发者推出,并通过Vertex AI面向企业推出。
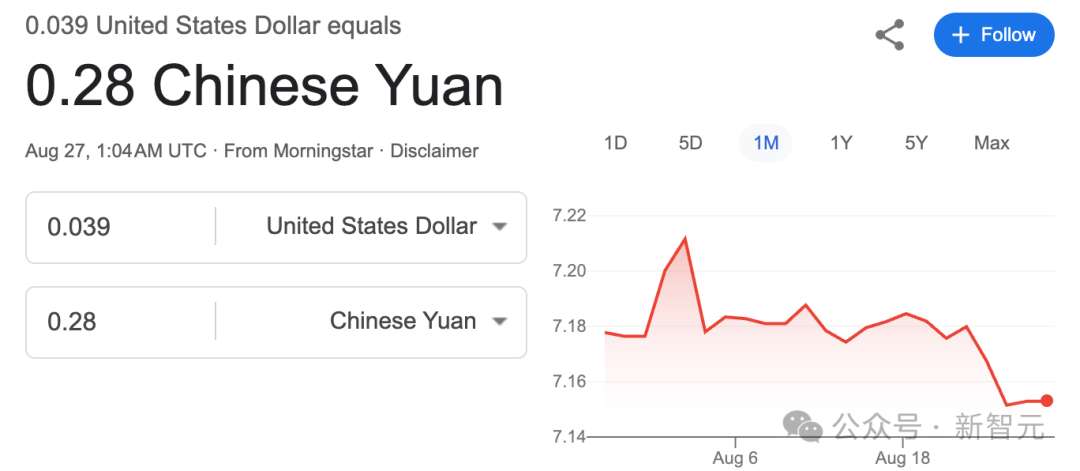
Gemini 2.5 Flash Image的价格为每百万输出token 30.00美元,每张图片为1290个输出token。
也就是每张图片只需0.039美元,按照现在的费率,一张图也就是不到3毛钱!
比OpenAI便宜太多了!网友纷纷表示,谷歌这是请奥特曼吃香蕉呢~


感觉一大批P图的都要失业了!
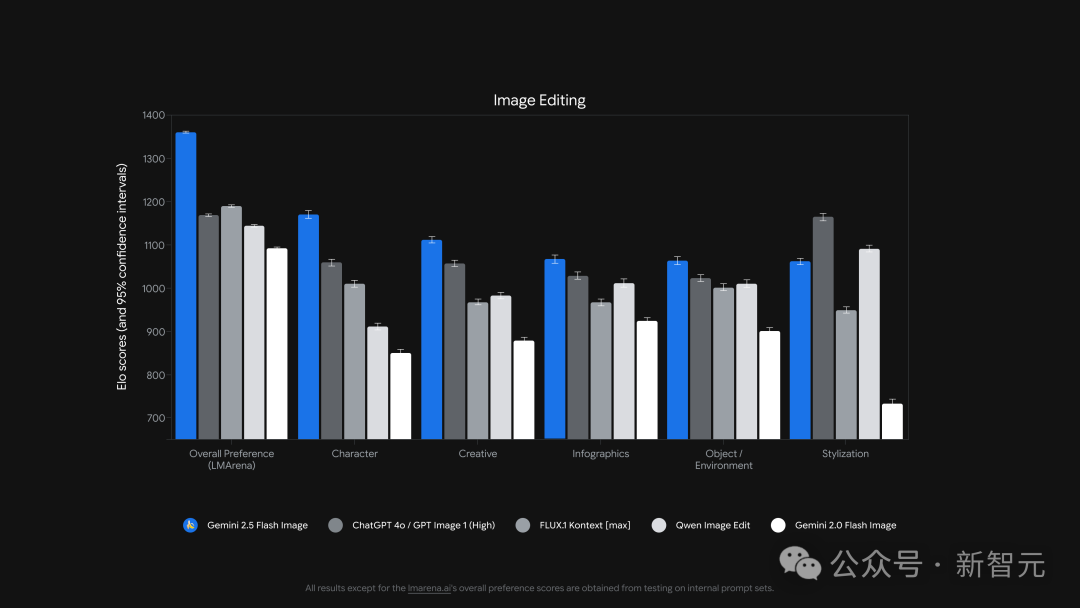
Gemini 2.5 Flash Image此次更新了四个超强能力:
可以将多张图像融合为一张图像,保持角色一致性以实现丰富的叙事效果,使用自然语言进行目标转换,并利用 Gemini的全球知识来生成和编辑图像。

比如过道、人像和手机可以完美的融合成一张人物在过道里打电话的照片。
尤其是灯管散发出的光形成的漫反射。
图像生成中的一个基本挑战是在多个提示和编辑中保持角色或物体的外观一致。
现在,可以将同一个角色放置在不同的环境中,以新的设置从多个角度展示单一产品,或生成一致的品牌资产,同时保持主体的一致性。
除了在角色一致性方面表现出色外,模型还非常擅长遵循视觉模板。
谷歌已经提供了开发者探索的模板,诸如房地产列表卡片、统一的员工徽章或整个产品目录的动态产品效果图等场景。

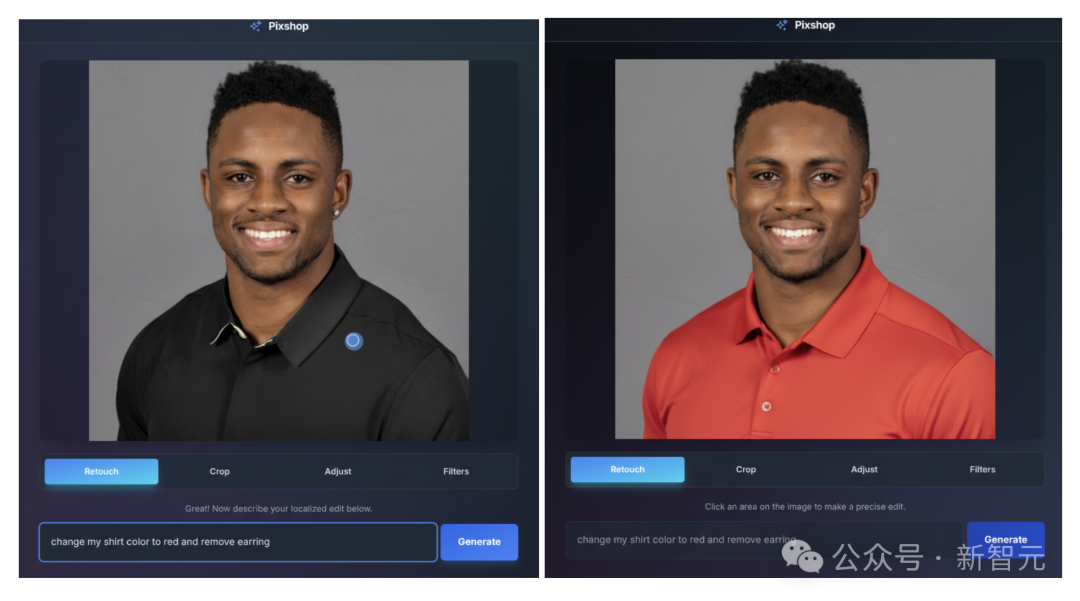
Gemini 2.5 Flash Image 支持通过自然语言进行目标化转换和精确的局部编辑。
例如,模型可以模糊图像背景、去除T恤上的污渍、从照片中移除整个人物、更改主体姿势、为黑白照片上色,或者根据简单的提示实现您所能想象到的其他效果。
更绝的是,此次更新的nano-banana还具有出色的「原生世界知识」。
从历史上看,图像生成模型在生成美观的图像方面表现出色,但在对现实世界的深层语义理解方面有所欠缺。
而Gemini 2.5 Flash Image受益于Gemini的全球知识,从而解锁了新的用例。
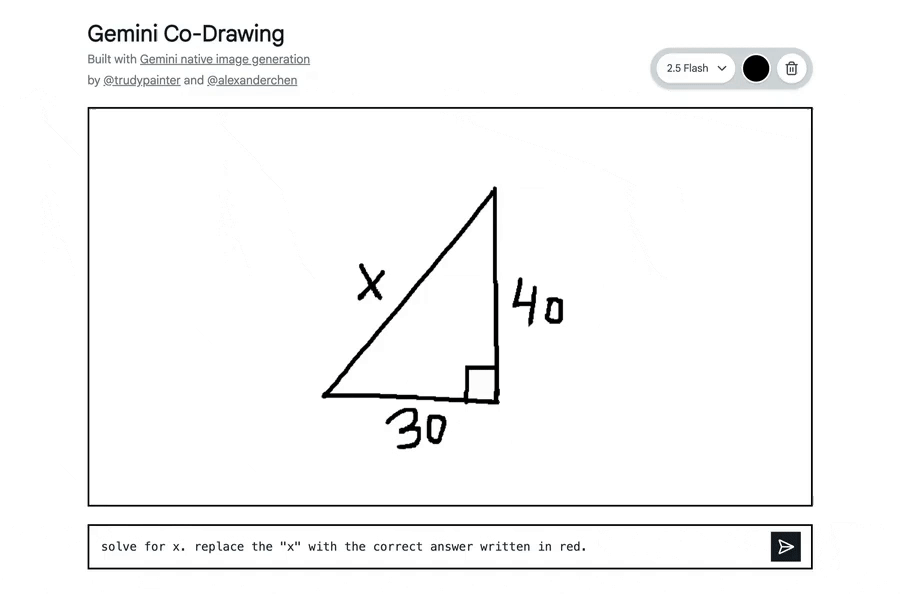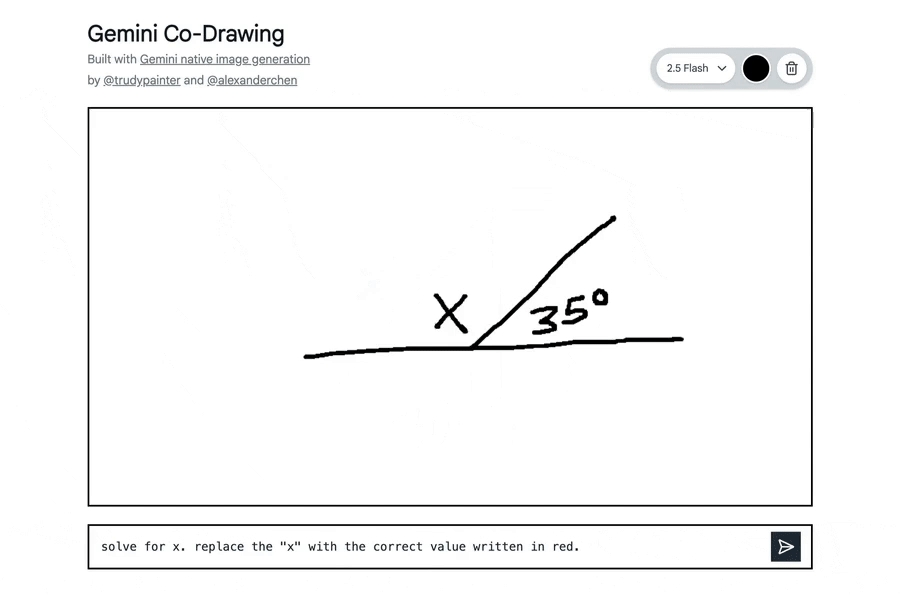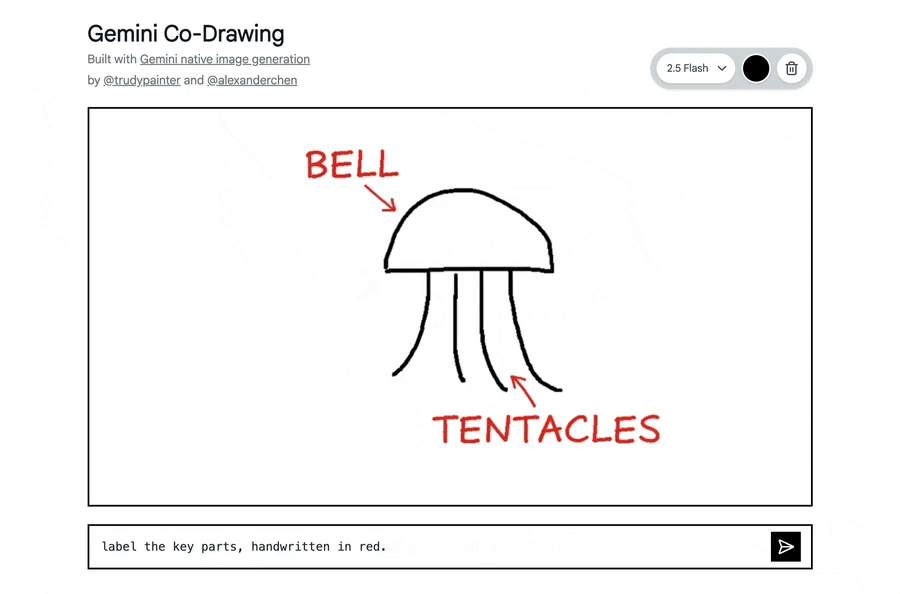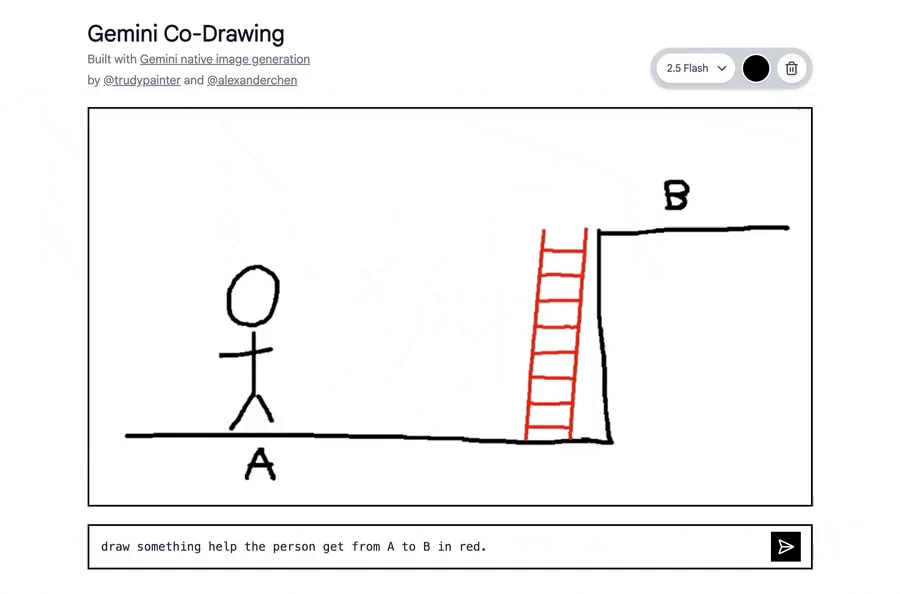
在Google AI Studio中构建了一个模板应用,可将简单的画布转变为交互式教育导师。
它展示了该模型读取和理解手绘图、帮助解答现实世界问题,以及在单一步骤中遵循复杂编辑指令的能力。
Gemini 2.5 Flash Image能够理解和融合多张输入图像。
可以将某个对象放入场景中,使用配色方案或纹理重新设计房间风格,并通过单个提示融合图像。
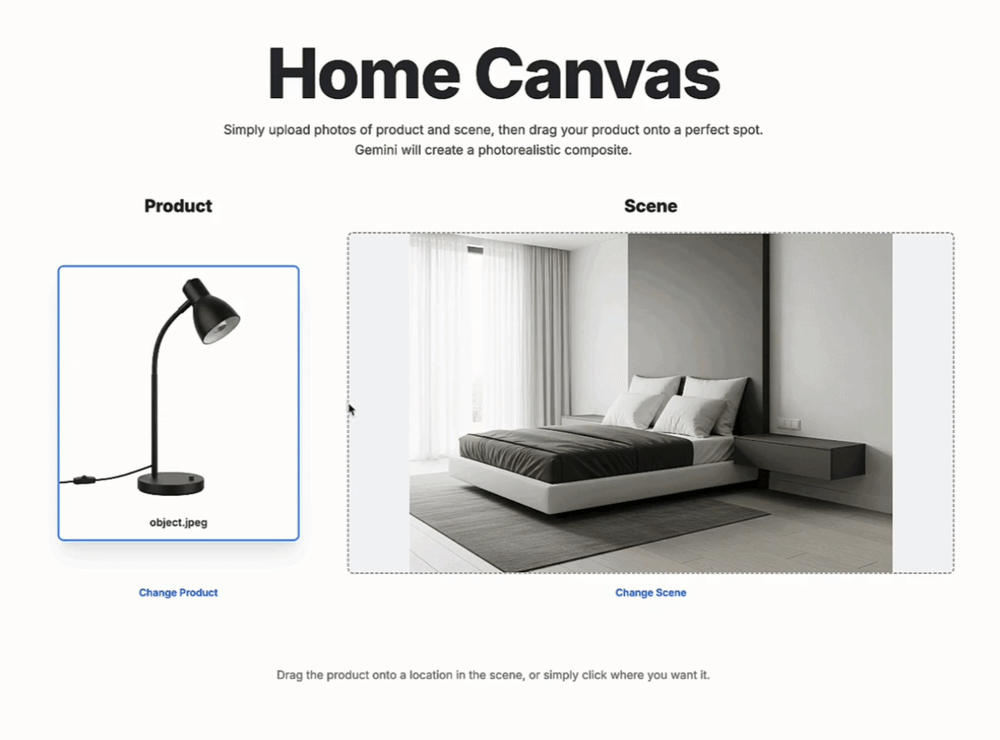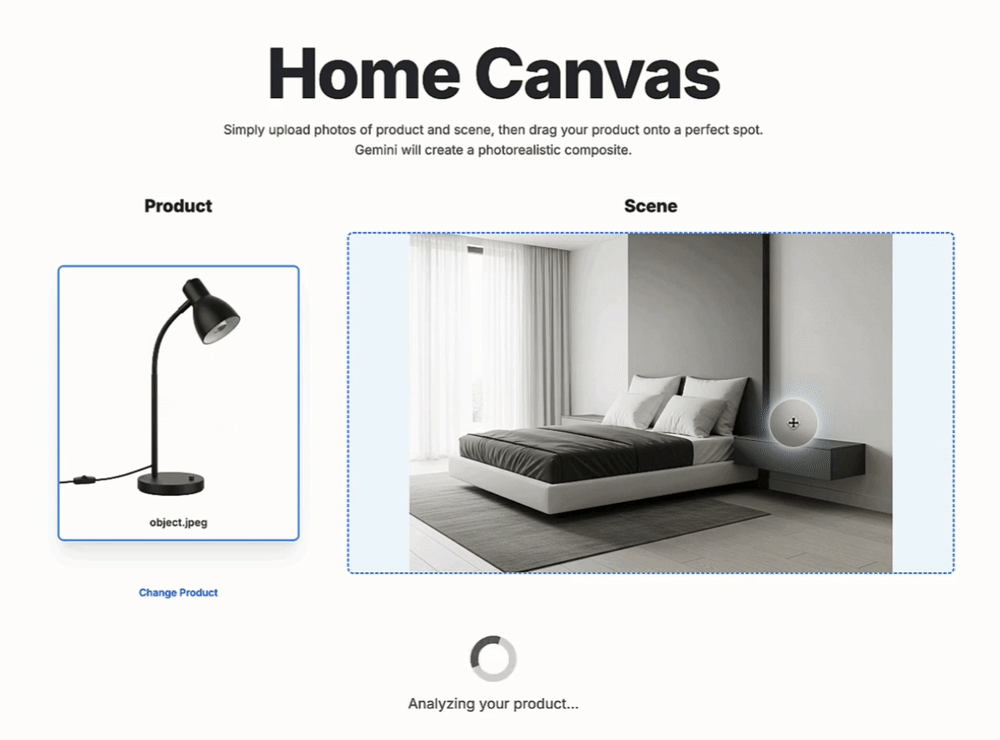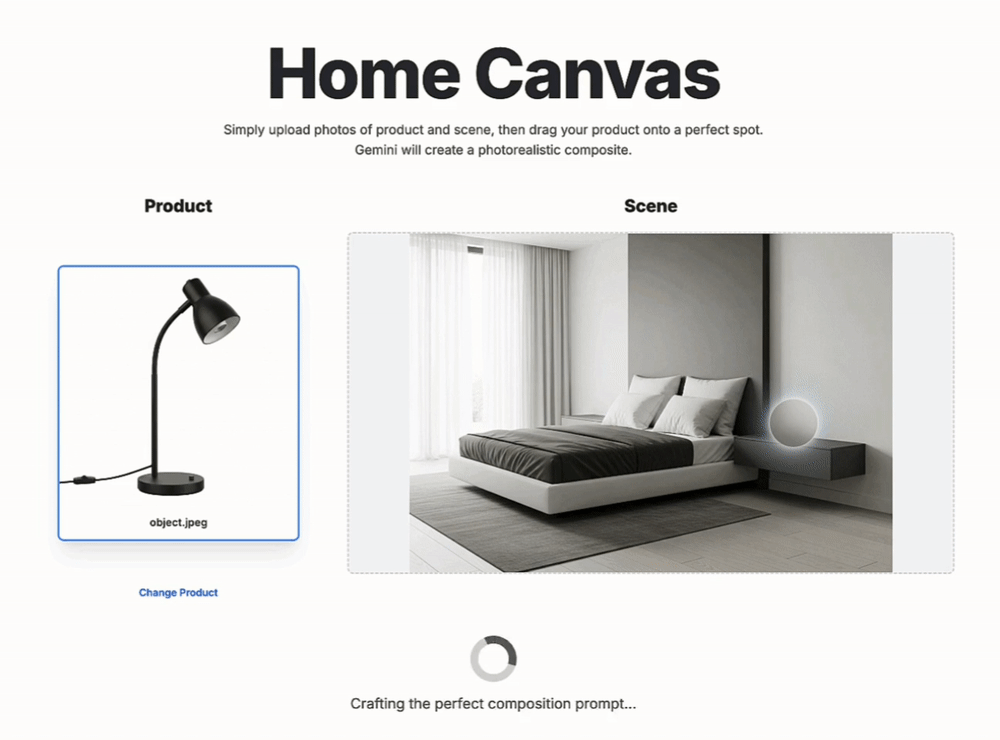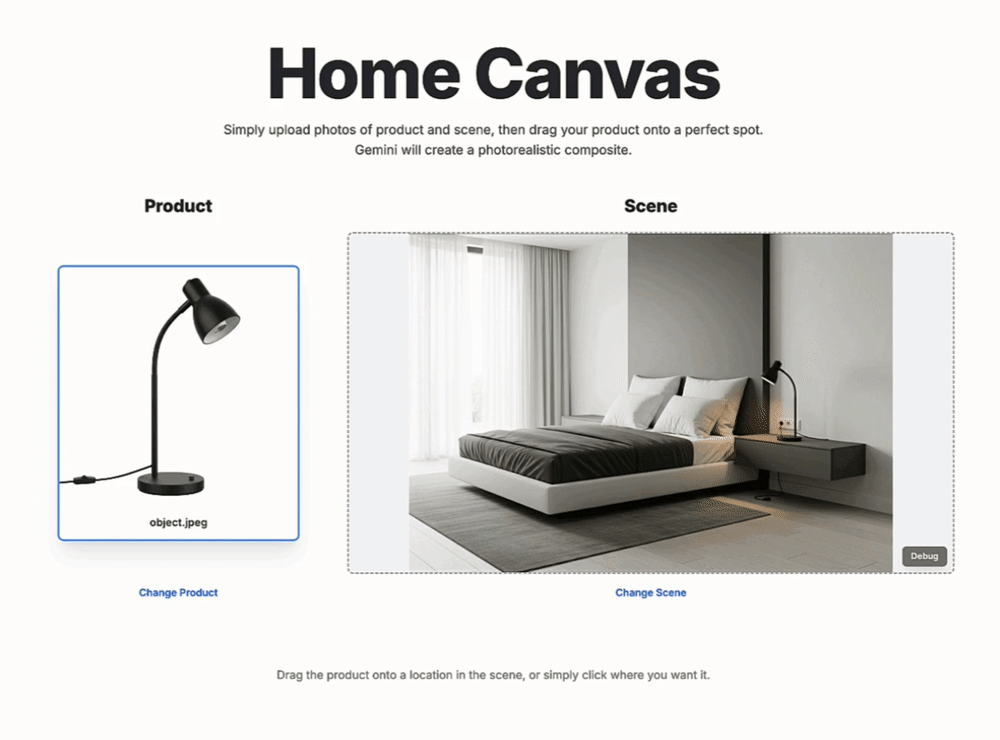
关于新模型的性能,谷歌DeepMind进行了详细介绍。
首先是模型的能力介绍:
「从逼真的写实杰作到令人惊叹的幻想世界,现在可以原生地生成、编辑和优化图像,在推理、控制和创意方面达到全新水平。」

角色一致性方面,为模型提供参考图像,它便能生成新的视觉内容,在不同的姿势、光照、环境或风格中保持角色、主体或对象的相似性,从而帮助创作出更具吸引力、叙事性更强的作品。
感觉个人就能制作电影的时代即将到来!

新模型可以应用特定的艺术风格、设计或纹理,可以轻松地将这些从一张图像转移到另一张图像,同时保留原主体的形态和细节。
这对于广告设计界几乎就是降维打击。

在创意构图方面,只需一个提示词,即可将多个图像中的创意元素融合在一起。
使用2.5 Flash,可以开始融合最多三个输入中的不同元素,从而创建出独特而统一的构图。
比如在山峰前跃出水面的鲸鱼。

借助Gemini的底层逻辑,2.5 Flash可以推断出图像中某个时刻之前或之后发生的事情。
这相当一种现实世界推理,需要完全依赖于世界知识。
比如,生成一个气球飘向仙人掌的初始画面后,让它设想接下来可能出现的场景。

谷歌的新模型一发布,最不开心的估计就是Photoshop了。
AI图片编辑功能直接降维打击了Adobe腹地。

未来像Adobe Photoshop等传统工具将面临重大挑战。
不过目前Nano-banana并不是完美的,比如在合并两张不同照片时,有时难以准确复制人脸。
但它在对现有图片进行细微调整方面表现已经非常出色。
而且成本还这么低。
你觉得AI会彻底取代传统产业吗?
参考资料:
https://developers.googleblog.com/en/introducing-gemini-2-5-flash-image/
https://deepmind.google/models/gemini/image/
文章来自于微信公众号“新智元”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
