惊天巨骗!一夜刷爆全球榜单的「神秘实验室」,竟然是假的
惊天巨骗!一夜刷爆全球榜单的「神秘实验室」,竟然是假的7月18日,AI圈忽然被这个消息刷屏了。一个名为「Basalt Labs」的神秘中国AI实验室,忽然空降。没有任何预热、没有任何预告,他们在X上扔出了一枚重磅消息——发布Monolith-1.0模型,登顶世界第一!
来自主题: AI资讯
8884 点击 2026-07-20 15:40
 搜索
搜索
7月18日,AI圈忽然被这个消息刷屏了。一个名为「Basalt Labs」的神秘中国AI实验室,忽然空降。没有任何预热、没有任何预告,他们在X上扔出了一枚重磅消息——发布Monolith-1.0模型,登顶世界第一!

让大模型给一张图片打“质量分”,它其实经常看走眼。
Digital AI和Physical AI之间,曾有一道难以跨越的鸿沟。

AI 角色硬件公司酷奇奇科技(Coolqq.com)已完成数千万元种子轮融资,本轮融资由上海浦东人工智能种子基金领投,商汤科技、零以创投跟投。云杉资本Spruce Capital担任长期独家财务顾问。

Hinge 创始人 Justin McLeod 宣布 为他的新交友公司 Overtone 完成了 1800 万美元的融资。McLeod 去年刚刚辞去他在 Hinge 的首席执行官职务,Hinge 的所有者 Match Group——也拥有 Tinder 和 OkCupid 等应用——正在与 FirstMark Capital 和 Pace Capital 一起为他的新公司提供资金支持。

作为WAIC 2026最受关注的论坛,由商汤科技承办的“基座大模型架构创新与生态合作论坛”吸引了无数AI研究者、产业专家和投资机构的目光。因它直面了当前大模型行业最核心的焦虑:当Scaling Law在逼近物理极限,多模态究竟是破局的“解药”,还是新瓶装旧酒的延伸?

Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。
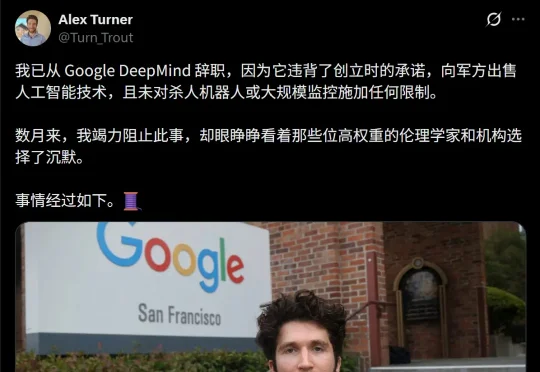
7月15日,前谷歌DeepMind科学家Alex Turner宣布辞职。在一篇令人震惊的长文中,他揭露了谷歌如何一步步向五角大楼妥协,最终签下一份「毫无红线」的军事AI协议。以下,是Alex Turner用离职换来的惊人真相。
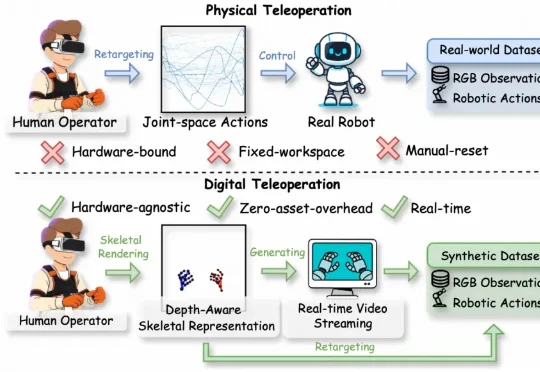
阿里巴巴达摩院的最新工作RynnWorld-Teleop对此给出的方案是:用生成式世界模型替代真实机器人。操作员的手势驱动一个实时视频生成器,由“数字世界中的机器人”完成全部视觉演示,同时自动获得关节级的动作标签。该方案被称为数字遥操作(Digital Teleoperation)。

最近,来自 Google、哥本哈根大学、牛津大学等机构的研究者提出了 VGGRPO(Visual Geometry GRPO,收录于 ECCV 2026)。这项工作聚焦于一个核心问题:如何在不牺牲预训练模型泛化能力的前提下,高效地提升视频生成的几何一致性,并使其适用于动态场景。其核心思路是,在隐空间(latent space)中利用 4D 几何奖励,进行几何感知的视频后训练。