
卷起来!让智能体评估智能体,Meta发布Agent-as-a-Judge
卷起来!让智能体评估智能体,Meta发布Agent-as-a-Judge微软发布了 Copilot,Apple 将 Apple Intelligence 接入了 OpenAI 以增强 Siri。
来自主题: AI技术研报
6110 点击 2024-10-18 13:59
 搜索
搜索
微软发布了 Copilot,Apple 将 Apple Intelligence 接入了 OpenAI 以增强 Siri。

随着对现有互联网数据的预训练逐渐成熟,研究的探索空间正由预训练转向后期训练(Post-training),OpenAI o1 的发布正彰显了这一点。

在AI的世界里,模型的评估往往被看作是最后的「检查点」,但事实上,它应该是确保AI模型适合其目标的基础。

测试结果显示出想开发出能与人类计算机操作能力相仿的AI,还存在很大挑战。
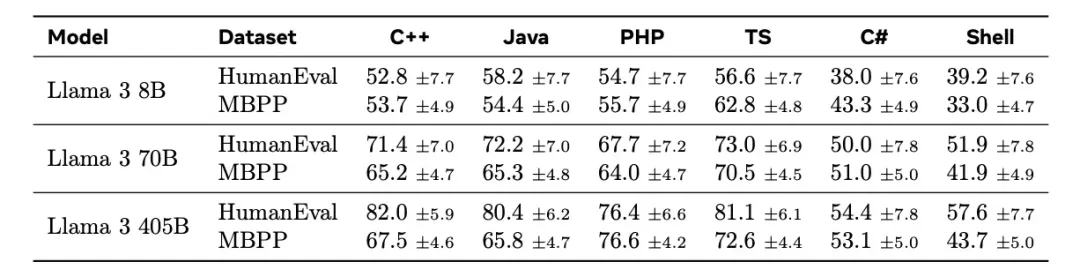
最近两款大型 AI 模型相继发布。
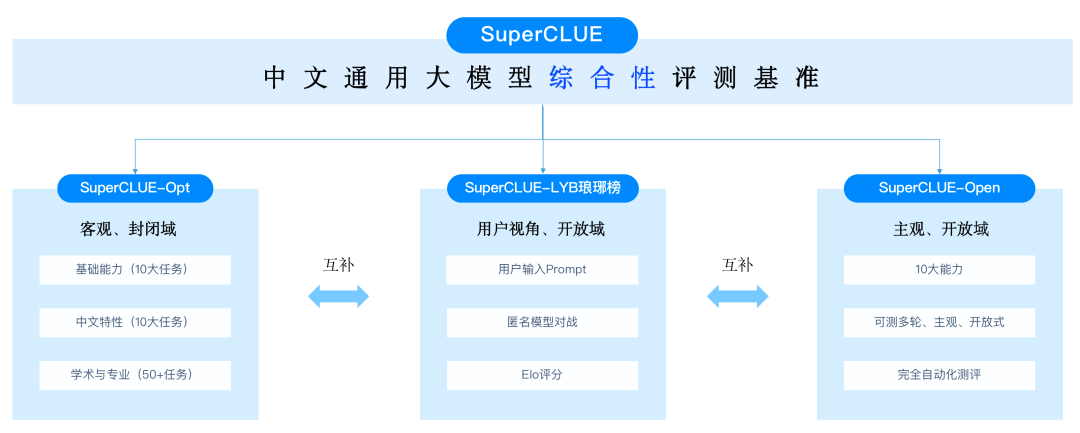
基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。

大语言模型(LLM)的迅速发展,引发了关于如何评估其公平性和可靠性的热议。
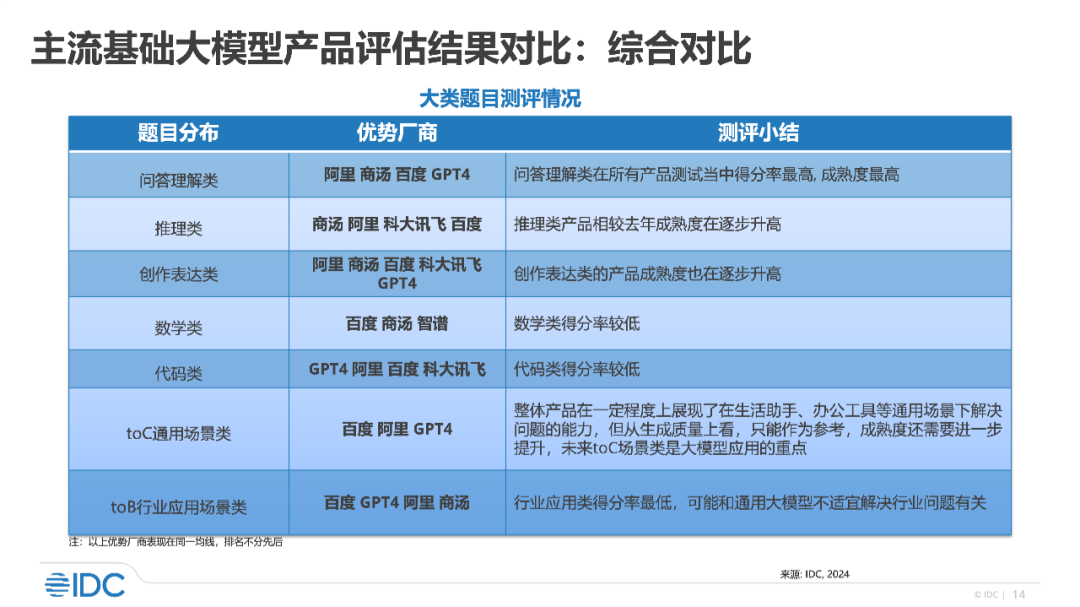
如果考试题太简单,学渣也能拿一百昏。在 AI 圈,我们应该拿怎样的「试卷」来检验一直处于流量 C 位的大模型的真实水平?是高考题吗?当然不是!