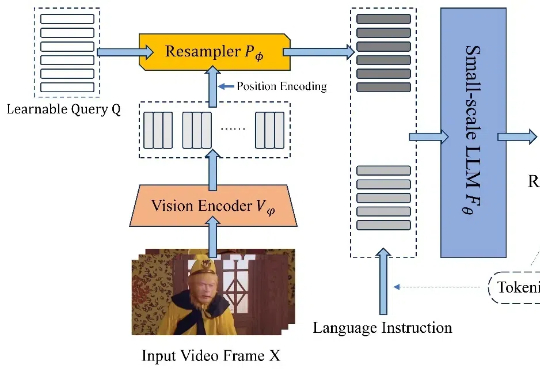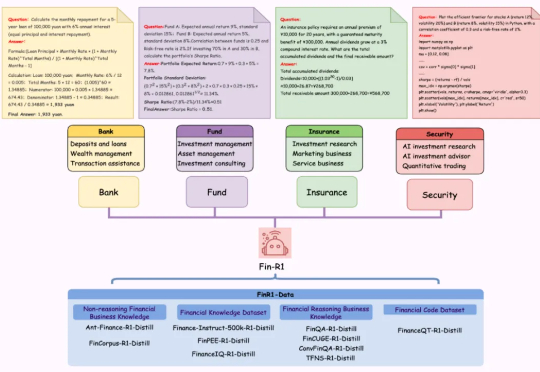
上财开源首个金融领域R1类推理大模型,7B模型媲美DeepSeek-R1 671B满血版性能
上财开源首个金融领域R1类推理大模型,7B模型媲美DeepSeek-R1 671B满血版性能近日,上海财经大学统计与数据科学学院张立文教授与其领衔的金融大语言模型课题组(SUFE-AIFLM-Lab)联合数据科学和统计研究院、财跃星辰、滴水湖高级金融学院正式发布首款 DeepSeek-R1 类推理型人工智能金融大模型:Fin-R1,以仅 7B 的轻量化参数规模展现出卓越性能,全面超越参评的同规模模型并以 75 的平均得
来自主题: AI技术研报
9094 点击 2025-03-27 09:41