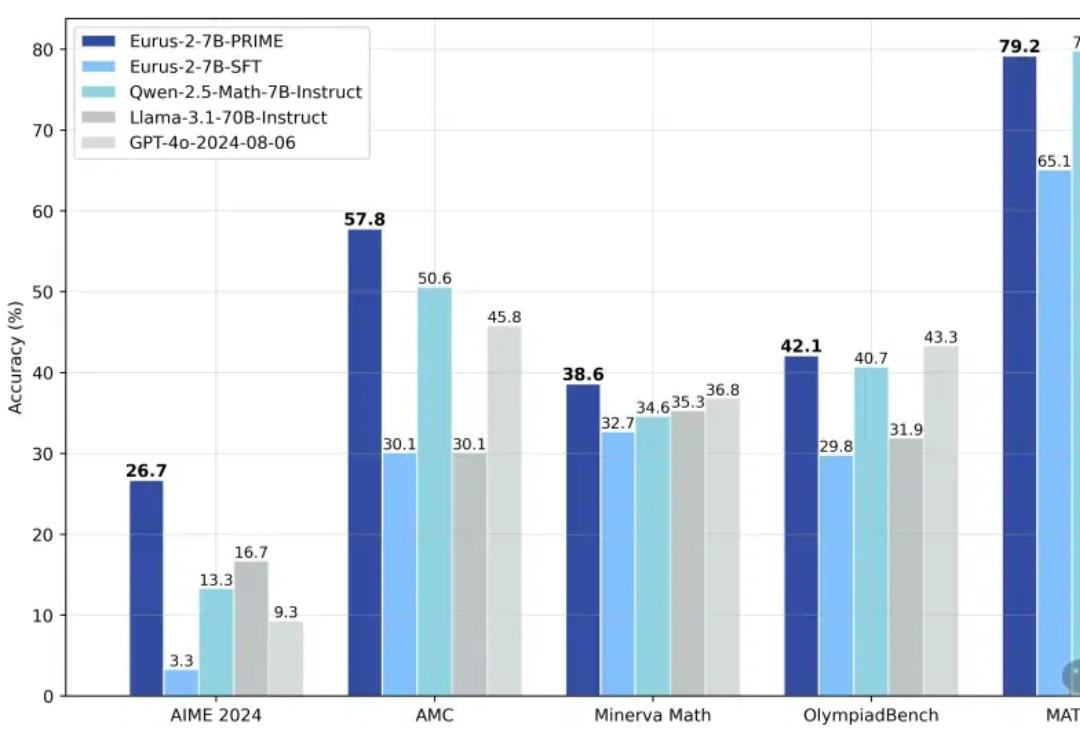
仅需一万块钱!清华团队靠强化学习让 7B模型数学打败GPT-4o
仅需一万块钱!清华团队靠强化学习让 7B模型数学打败GPT-4oOpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。
来自主题: AI资讯
7726 点击 2025-01-06 14:56
 搜索
搜索
OpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。
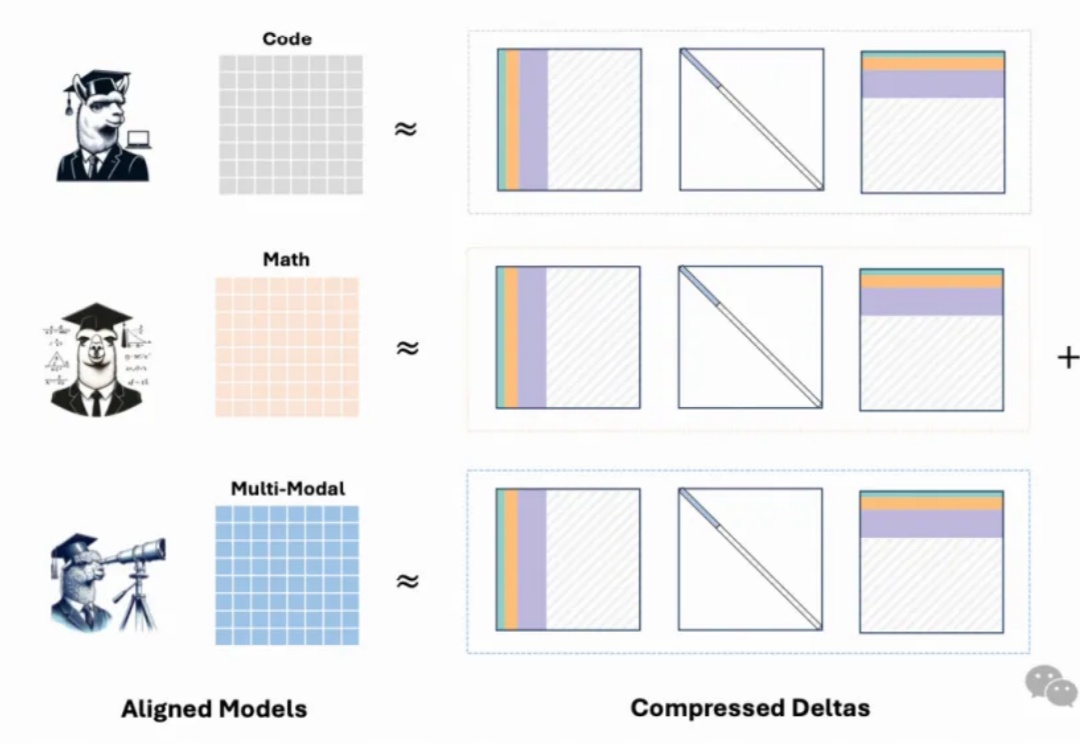
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。

消除激活值(outliers),大语言模型低比特量化有新招了—— 自动化所、清华、港城大团队最近有一篇论文入选了NeurIPS 2024(Oral Presentation),他们针对LLM权重激活量化提出了两种正交变换,有效降低了outliers现象,达到了4-bit的新SOTA。

工具调用是 AI 智能体的关键功能之一,AI 智能体根据场景变化动态地选择和调用合适的工具,从而实现对复杂任务的自动化处理。例如,在智能办公场景中,模型可同时调用文档编辑工具、数据处理工具和通信工具,完成文档撰写、数据统计和信息沟通等多项任务。
苹果最新杀入开源大模型战场,而且比其他公司更开放。 推出7B模型,不仅效果与Llama 3 8B相当,而且一次性开源了全部训练过程和资源。大模型,AI,苹果AI,苹果开源模型

Mistral AI两款全新7B模型宣战OpenAI,对标更长的代码分析和更高效的数学推理。

只需激活60%的参数,就能实现与全激活稠密模型相当的性能。

最近,7B小模型又成为了AI巨头们竞相追赶的潮流。继谷歌的Gemma2 7B后,Mistral今天又发布了两个7B模型,分别是针对STEM学科的Mathstral,以及使用Mamaba架构的代码模型Codestral Mamba。

谷歌的Gemma 2刚刚发布,清华和北航的两名博士生就已经成功推出了指令微调版本,显著增强了Gemma 2 9B/27B模型的中文通用对话、角色扮演、数学、工具使用等能力。
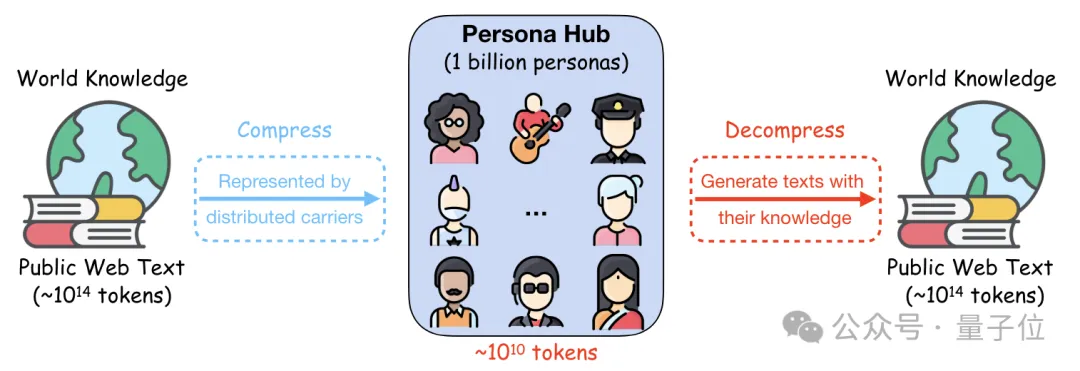
10亿名“员工”生产数据合成,数量占到了世界人口的13%。