真·顺着网线抓你!OpenAI深夜上线防沉迷,GPT直连警局
真·顺着网线抓你!OpenAI深夜上线防沉迷,GPT直连警局ChatGPT也推出「防沉迷系统」了?如果你习惯用缩写、语气太嫩,或者仅仅是作息不规律,都可能被判定为未成年!想恢复成人权限,代价是上传你的脸部3D扫描数据。不需要等到未来,欢迎来到2026年的「行为算命」时代。
来自主题: AI资讯
8887 点击 2026-01-23 15:18
 搜索
搜索
ChatGPT也推出「防沉迷系统」了?如果你习惯用缩写、语气太嫩,或者仅仅是作息不规律,都可能被判定为未成年!想恢复成人权限,代价是上传你的脸部3D扫描数据。不需要等到未来,欢迎来到2026年的「行为算命」时代。

2025年,风光无限的机器人们在Demo中大秀绝活,从叠衣服、工厂和物流站分拣包裹,到零售店卖货……它们忙碌的身影存在于各种各样的场景中。但回到现实世界,具身智能真正参与的生活和生产环节,却少之又少。
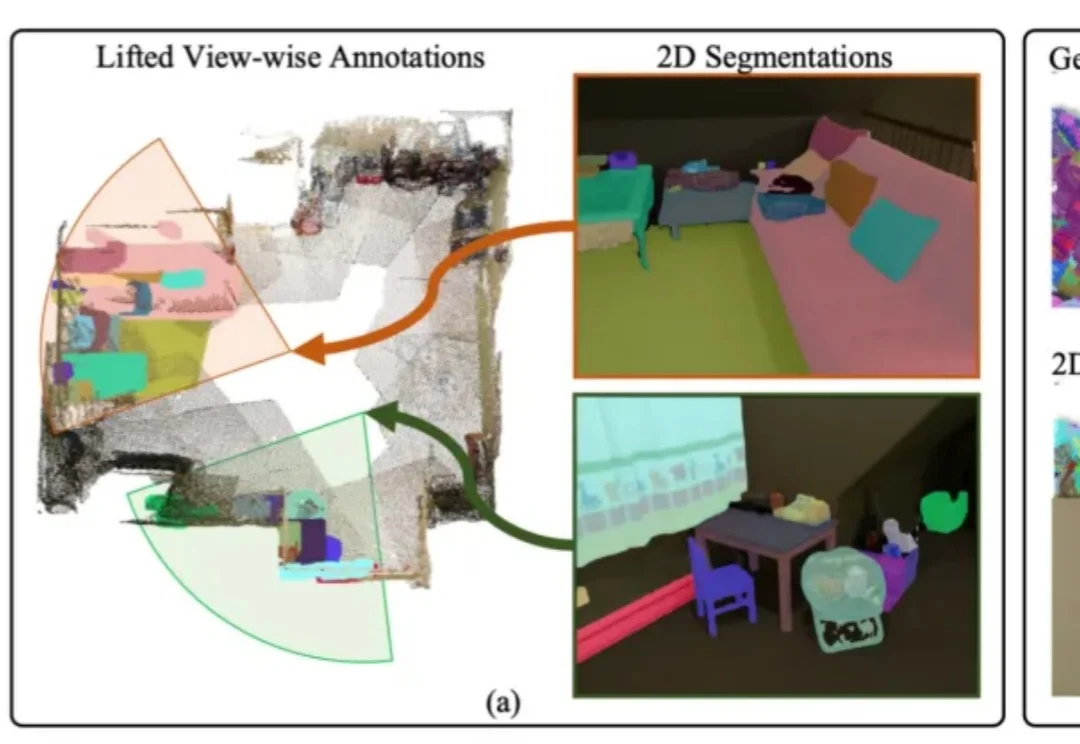
3D模型的实例分割一直受限于稀缺的训练数据与高昂的标注成本,训练效果有待提升。
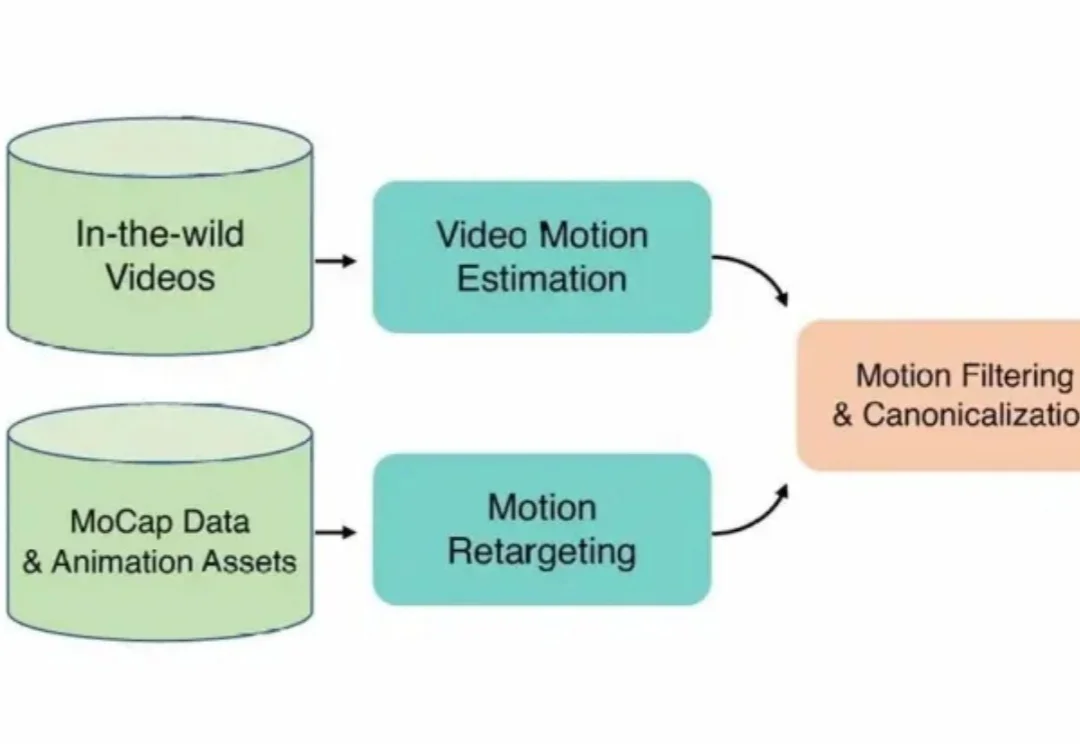
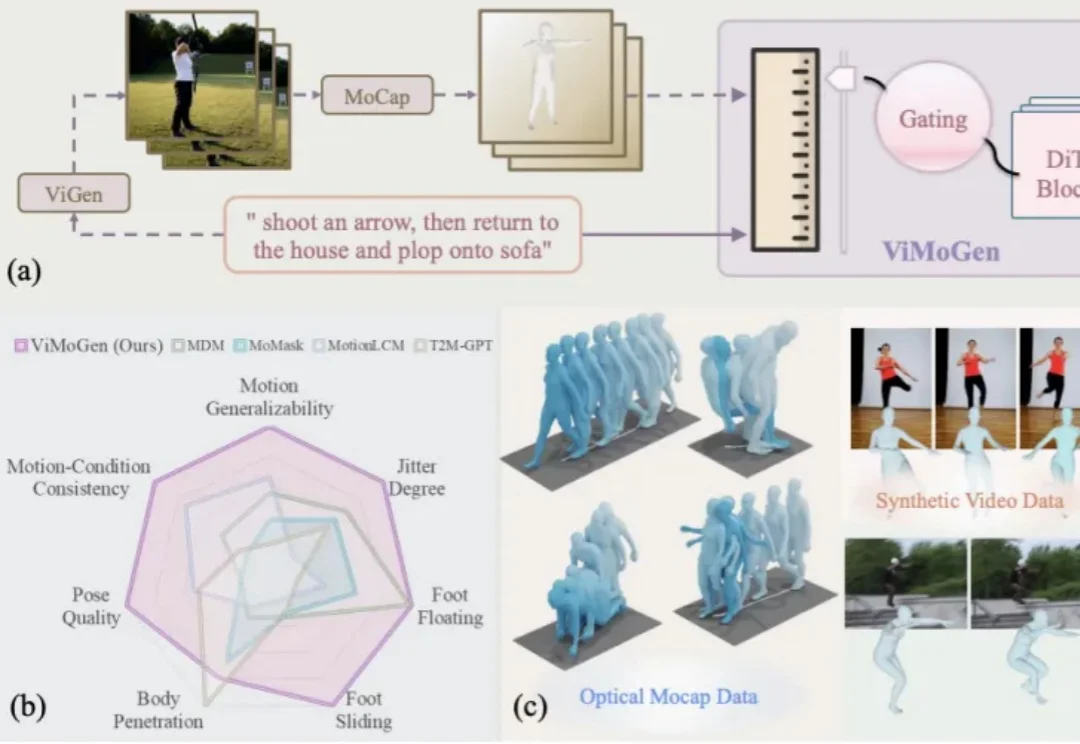
在3D角色动画创作领域,高质量动作资产的匮乏长期制约着产出的上限。
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。

让静态3D模型「动起来」一直是图形学界的难题:物理模拟太慢,生成模型又不讲「物理基本法」。近日,北京大学团队提出DragMesh,通过「语义-几何解耦」范式与双四元数VAE,成功将核心生成模块的算力消耗降低至SOTA模型的1/10,同时将运动轴预测误差降低了10倍。
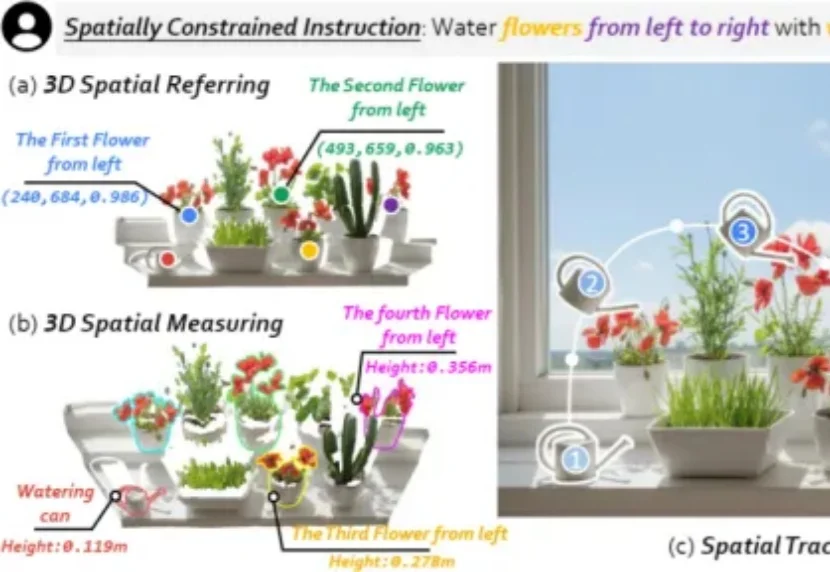
我们希望具身机器人真正走进真实世界,尤其走进每个人的家里,帮我们完成浇花、收纳、清洁等日常任务。但家庭环境不像实验室那样干净、单一、可控:物体种类多、摆放杂、随时会变化,这让机器人在三维物理世界中「看懂并做好」变得更难。

“我其实天生就是一个适合创业的人。”

近期,上海路米尔网络科技有限公司(下文简称:路米尔)已完成了天使轮和Pre-A轮融资。其中,天使轮融资由真格基金领投,Pre-A轮融资由IDG资本领投,公司融资额超千万美元,目前,公司估值已经接近7000万美元。
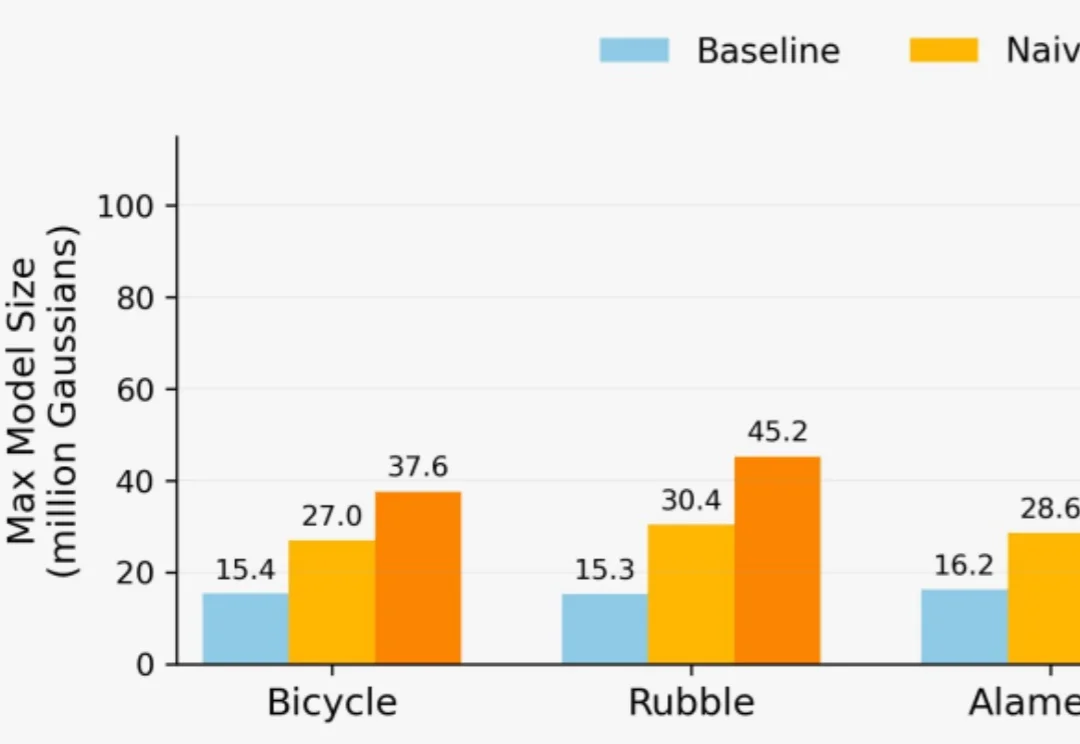
想用3D高斯泼溅(3DGS)重建一座城市?