RL加持的3D生成时代来了!首个「R1 式」文本到3D推理大模型AR3D-R1登场
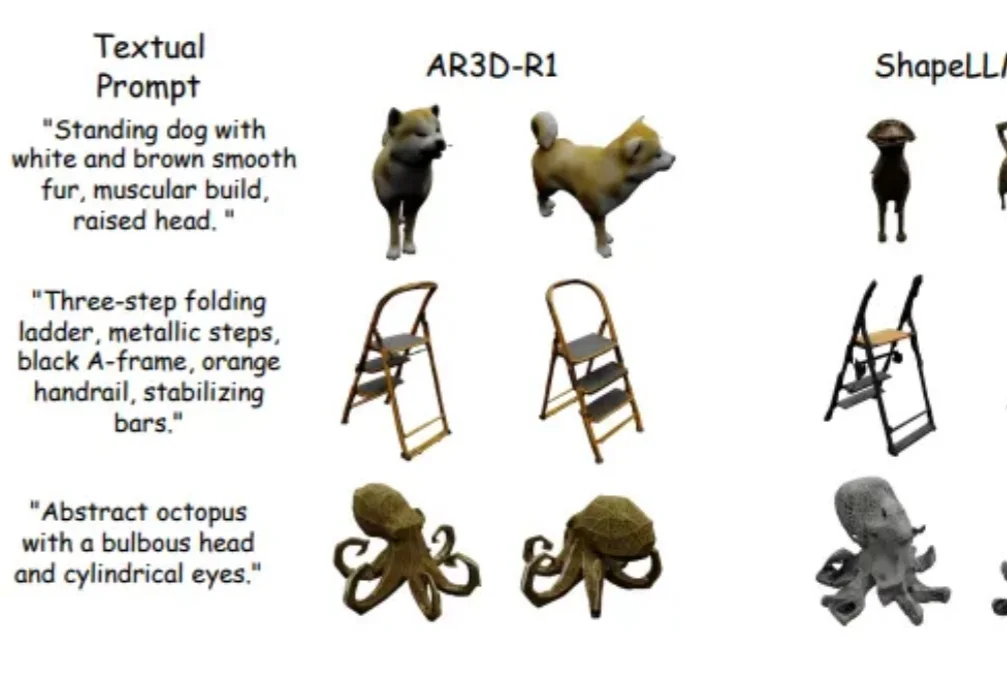
RL加持的3D生成时代来了!首个「R1 式」文本到3D推理大模型AR3D-R1登场强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
来自主题: AI技术研报
9031 点击 2025-12-23 09:27
 搜索
搜索
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
还记得前段时间在 AI 圈刷屏的李飞飞「3D 世界生成模型」吗?现在,国产版终于来了。
键盘不会立刻消失,但在越来越多的场景里,它已经悄悄退成语音之后的「编辑器」。如果几年前有人跟我说,「你以后写稿可能不怎么需要键盘了」,我大概会把这句话当成一句玩笑。那时候我正处在对机械键盘的迷恋期,研究轴体、键帽、键程,购入过 Cherry、Filco、NiZ、Keychron、3D 打印分体式键盘。甚至为了提高打字效率,专门学习过双拼输入法。
和传统的游戏自动化脚本不同,这是一个完整的通用的大模型,不仅限于单一游戏的操作,能够玩遍市面上几乎全部的游戏类型。于是,让我们正式介绍主角,来自英伟达的最新开源基础模型 NitroGen。该模型的训练目标是玩 1000 款以上的游戏 —— 无论是 RPG、平台跳跃、吃鸡、竞速,还是 2D、3D 游戏,统统不在话下!
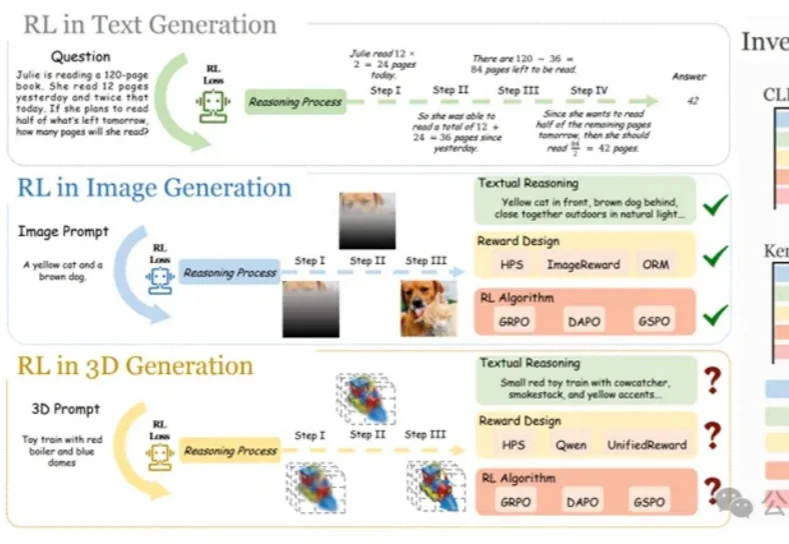
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。

智东西12月19日报道,由三名00后武汉大学校友创办的大模型领域科技创企模态跃迁(MercAllure),已完成两轮累计数千万元融资,投资方包括深圳高新投、力合科创、楚天凤鸣天使基金、武汉基金、奇绩创坛等机构。

在计算机图形学、三维视觉、虚拟人、XR 领域,SIGGRAPH 是毫无争议的 “天花板级会议”。 SIGGRAPH Asia 作为 SIGGRAPH 系列两大主会之一,每年只接收全球最顶尖研究团队的成果稿件,代表着学术与工业界的最高研究水平与最前沿技术趋势。
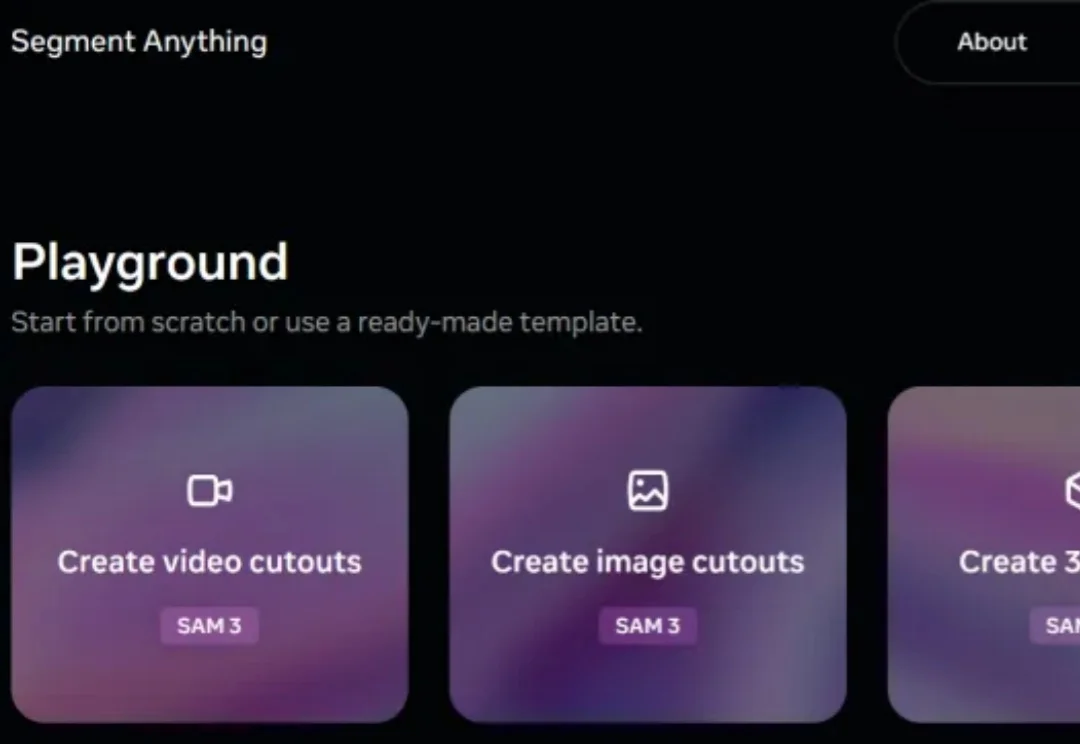
继 SAM(Segment Anything Model)、SAM 3D 后,Meta 又有了新动作。
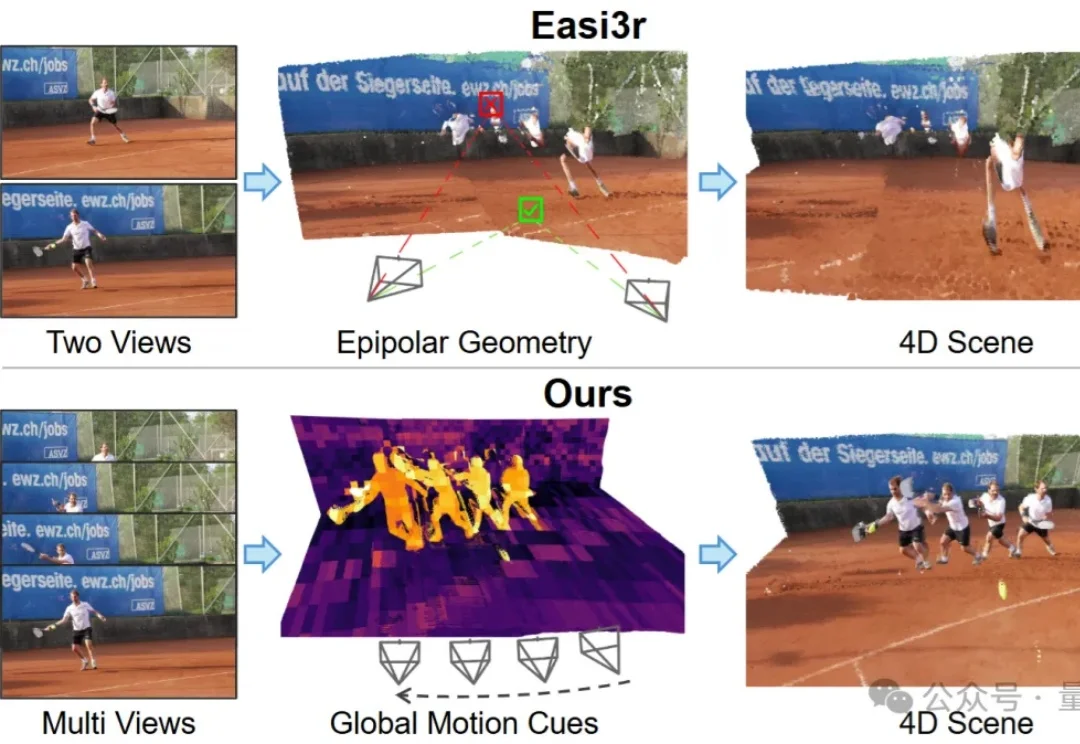
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
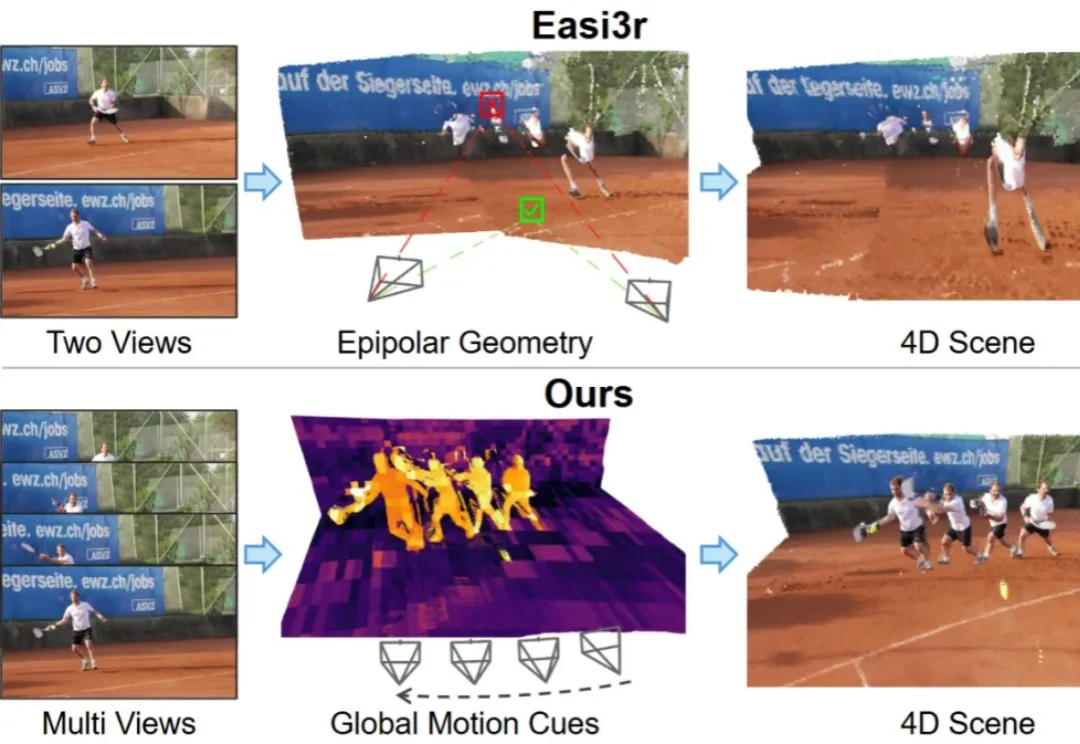
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?