
刚刚,万元级个人机器人再升级!喊一声就跳英歌舞
刚刚,万元级个人机器人再升级!喊一声就跳英歌舞小布米OTA V3.0来了。喊一声就跳舞,拖拽胳膊就学会新动作,还能跟你打拳——你的第一个个人机器人,这次真的听话了。
来自主题: AI资讯
8217 点击 2026-06-30 10:47
 搜索
搜索
小布米OTA V3.0来了。喊一声就跳舞,拖拽胳膊就学会新动作,还能跟你打拳——你的第一个个人机器人,这次真的听话了。
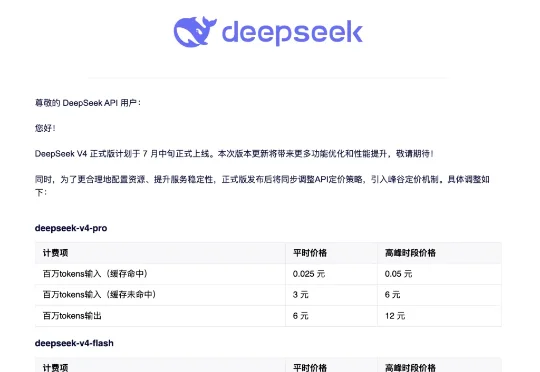
记者获悉,DeepSeek宣布价格调整,引入峰谷计费机制:以DeepSeek-v4-pro为例,其输入价格(缓存命中)平时为0.025元/百万tokens,高峰时期为0.05元/百万tokens;输入价格(缓存未命中)平时为3元/百万tokens,高峰时期为6元/百万tokens;输出价格平时为6元/百万tokens,高峰时期为12元/百万tokens。

2026年6月23日,字节跳动CEO梁汝波罕见地出现在火山引擎FORCE原动力大会的视频画面中。他没有选择现场登台,但视频透露了一个关键:“攀登AI高峰是字节当下最重要的事情”。紧接着,他补了一句更关键的判词:过去几年,字节一直在“聚焦收缩业务宽度”,把精力重点放到AI,在AI领域聚焦到提升模型能力。

就在今天凌晨,哈佛博士Douglas Yao在X宣布,研发了一款针对阿尔茨海默病的新药PAC-832,引发了数百人的围观。这是世界上第一个选择性GalR1拮抗剂,创始人表示全程使用了机器人自动化技术和AI大模型。
没错,我说的就是从6月下半旬开始在Github上爆火的OpenMontage。这是一个专门用来给AI视频生成准备的Harness工具,你把你的提示词给它,它就能自动帮你完善成专业的AI视频生成提示词,并且还配有剪辑、配音等等一系列后期工作。
清华系物理AI企业「清研精准」已于近日完成数亿元B3轮融资,本轮融资由北京市绿色能源基金、北汽产投领投,裕隆集团跟投。据悉,该轮资金将会用于核心人才招募、多模态数采设备的研发与规模化部署,以及算力采购与模型训练基础设施建设等方向。

就在最近,英国前首相府数据科学家Liam Wilkinson,花一个周末搭了76个MCP工具,把Claude、GPT、Gemini等四个顶尖模型扔进了《文明VI》。结果,23场对局打完,其中一个AI造了核弹炸了法国——然后输了。
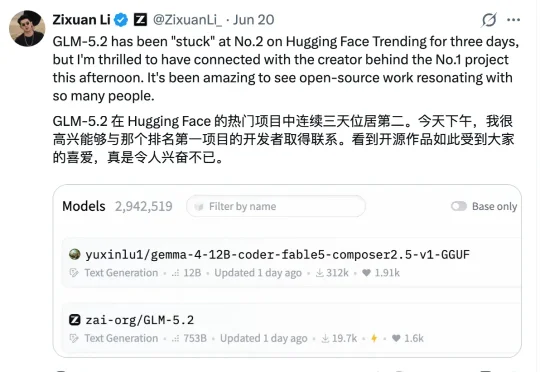
一位个人开发者,竟然在一众大厂中,杀进了抱抱脸Models Trending榜的前排?!突然出现了一个个人账号:yuxinlu1。再一看下载量——最新数据已高达20.7万和53.6万。好家伙,这是什么神仙模型来了?

就在外界惊呼“AI快要接管纯数学研究”之际,一场限制条件极其严格、并由30位数学家以匿名方式进行评审的数学测试,却揭开了AI数学能力的另一面:AI不仅会幻觉、会跳步骤,甚至还把数学家论文里的关键论证几乎原样照搬,却忘了注明引用。

来自 Sharpa、清华大学、UC Berkeley、上海交通大学、ETH Zurich 等机构的研究者提出了首个通用触觉基础策略 FTP-1。它基于约 3,000 小时、来自 26 个数据来源和 21 种触觉传感器的数据进行预训练