a16z领投Probook3400万美元A轮押注家政调度AI
a16z领投Probook3400万美元A轮押注家政调度AIa16z近日公开表示,已领投Probook 3400万美元A轮融资。对关注科技资本流向的投资圈而言,这一信息的意义并不止于“又一家AI公司完成融资”,更重要的是,头部风投正在明确把关注点从客服、语音代理等前台自动化场景,转向家政与本地服务行业更核心的运营中枢——调度系统。
来自主题: AI资讯
8974 点击 2026-07-01 14:57
 搜索
搜索
a16z近日公开表示,已领投Probook 3400万美元A轮融资。对关注科技资本流向的投资圈而言,这一信息的意义并不止于“又一家AI公司完成融资”,更重要的是,头部风投正在明确把关注点从客服、语音代理等前台自动化场景,转向家政与本地服务行业更核心的运营中枢——调度系统。

6月30号,《科创板日报》独家报了个消息:Kimi上一轮融资刚交割完,新一轮已经启动了。上一轮投后估值200亿美元,新一轮投前315亿美元。今天的中国一级市场,已经默认了一件事,Kimi应该继续融资,OpenAI和Anthropic也应该继续融资。

今天要分享的公司是:Sengine,生境科技,之前我也分享过一家国内做 3D 的 AI 公司,但 Sengine 和 VAST 完全不是一个产品路径,后面会分析。2026 年,Forbes 30 Under 30 Asia 的 AI 榜单里,有一家来自深圳的公司:Sengine Technology,生境科技。

三位哈佛辍学生创办。

近日,穗升科技首款产品Memoket在海外正式开启预售。这是一款AI Memory可穿戴硬件,仅11克,分表带款和手环款两种形态,待机超过30天,连续录音续航20小时。它可以将物理世界中所听到的信息结构化,需要时调给Agent,实现跨时间聚合和Context(上下文)串联。
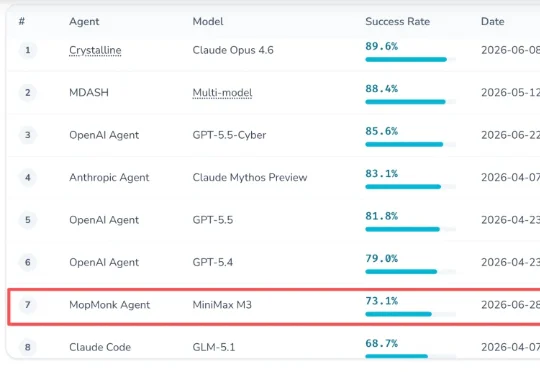
太疯狂了!一个连官网都没有的神秘中国AI「扫地僧」,以73.1%的胜率杀入CyberGym全球前七,紧咬OpenAI。全网都在疯传,这到底是谁家的高手?它叫MopMonk(扫地僧)。凭借73.1%的成功率,以微弱差距紧咬OpenAI,一举刷新了中国团队在该榜单上的历史最高分。

都说AI会写代码了,程序员的饭碗就保不住。但Anthropic的Boris Cherny却说:真正重要的从来不是岗位,而是你这一刻在扮演哪种角色。
最近,清华教授、智谱灵魂人物唐杰聊得有点high。

全球金融科技赛道再迎重磅融资。Z Potentials获悉,全球金融科技平台Airwallex 空中云汇近日宣布完成H轮3.2亿美元融资 ,投后估值达110亿美元。

小布米OTA V3.0来了。喊一声就跳舞,拖拽胳膊就学会新动作,还能跟你打拳——你的第一个个人机器人,这次真的听话了。