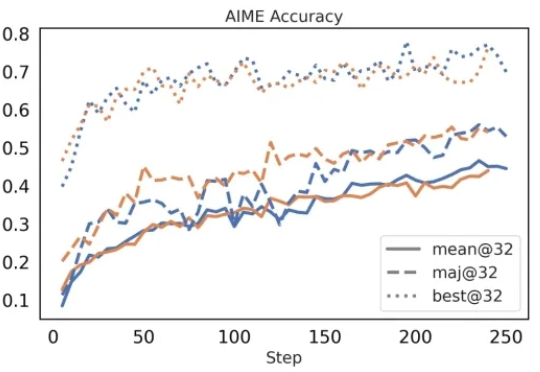
硬核拆解!从GPT-2到gpt-oss,揭秘大模型进化关键密码
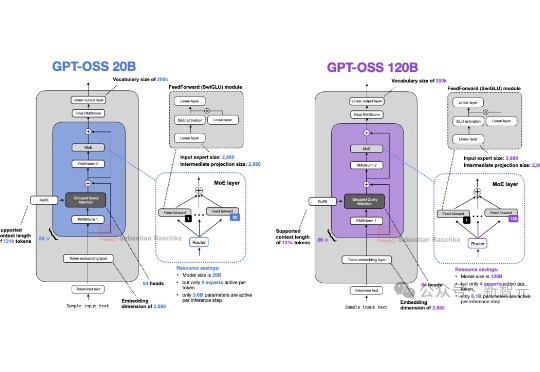
硬核拆解!从GPT-2到gpt-oss,揭秘大模型进化关键密码自GPT-2以来,大模型的整体架构虽然未有大的变化,但从未停止演化的脚步。借OpenAI开源gpt-oss(120B/20B),Sebastian Raschka博士将我们带回硬核拆机现场,回溯了从GPT-2到gpt-oss的大模型演进之路,并将gpt-oss与Qwen3进行了详细对比。
来自主题: AI技术研报
10075 点击 2025-08-18 11:13